GPU Computing Startup
GPU, Compute and AI.
目录
- 目录
- 资料汇总
- github 资源汇总
- 论文
- datawhale
- 李沐
- machine learning sys blog
- 机器人
- pytorch 知识点整理
- 安装 pytorch cpu 版本
- 安装 pytorch cuda 版本
- pytorch book vscode 环境配置
- 示例
资料汇总
| 链接 | 说明 |
|---|---|
| 《深度学习框架PyTorch:入门与实战》代码 | 这个适合开始阶段,参考pytorch 知识点整理。此书配套1.6版本的pytorch,参考安装 pytorch cpu 版本和pytorch book vscode 环境配置 |
| Pytorch 官方文档 | 最新的是2.3版本,和下面教程搭配着看 |
| Pytorch 官方文档教程仓库 | PyTorch tutorials。有点占地方,里面和文档内容对应,有直接可运行的脚本 |
| Pytorch 安装指引 | 安装CPU/CUDA版本 |
| Pytorch 官方文档翻译版 | Pytorch 中文文档,缺点,广告太多 |
| Pytorch Examples | 围绕 pytorch 的视觉、文本、强化学习等方面的一组示例。 |
| Pytorch 源码仓库 | 具有强大 GPU 加速的 Python 张量和动态神经网络。 |
github 资源汇总
| 仓库 | 说明 |
|---|---|
| 1. AI/AGI/AIoT | |
| HuggingFace/Transformers ★★★★★ |
著名论文Attention Is All You Need 提出的 Transformers 提供数千个预训练模型,用于执行不同模态(例如文本、视觉和音频)的任务。这些模型可应用于: 1. 📝 文本,用于 100 多种语言的文本分类、信息提取、问答、摘要、翻译和文本生成等任务。 2. 🖼️ 图像,用于图像分类、对象检测和分割等任务。 3. 🗣️ 音频,用于语音识别和音频分类等任务。 Transformers 模型还可以执行多种模态组合的任务,例如表格问答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问答。 |
| Karpathy/llm.c ★★★★★ |
简单、纯 C/CUDA 的 LLM,无需 245MB 的 PyTorch 或 107MB 的 cPython。当前重点是预训练,特别是重现 GPT-2 和 GPT-3 迷你剧,以及 train_gpt2.py 中的并行 PyTorch 参考实现。测试见:llm.c |
| Google/Vision Transformer ★★★★★ |
在这个存储库中,我们发布了论文中的模型 1. 一张图片胜过 16x16 个单词:用于大规模图像识别的 Transformers 2. MLP-Mixer:用于视觉的全 MLP 架构 3. 如何训练你的 ViT?视觉 Transformers 中的数据、增强和正则化 4. 当视觉 Transformers 在没有预训练或强大的数据增强的情况下胜过 ResNets 时 5. LiT:使用锁定图像文本调整的零样本传输 6. 替代间隙最小化改进了清晰度感知训练 这些模型在 ImageNet 和 ImageNet-21k 数据集上进行了预训练。我们在 JAX/Flax 中提供了用于微调已发布模型的代码。 |
| Open WebUI (Formerly Ollama WebUI) ★★★★★ |
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线操作。它支持各种LLM运行程序,包括 Ollama 和 OpenAI 兼容的 API。有关更多信息,请务必查看我们的Open WebUI 文档。 |
| Ultralytics/Yolov5 ★★★★★ |
YOLOv5🚀是世界上最受欢迎的视觉 AI,代表了 Ultralytics 对未来视觉 AI 方法的开源研究,融合了数千小时研发过程中获得的经验教训和最佳实践。 |
| Dusty-nv/Jetson Inference ★★★★★ |
该项目使用 TensorRT 在 C++ 或 Python 的 GPU 上运行优化网络,并使用 PyTorch 训练模型。支持的 DNN 视觉基元包括用于图像分类的 imageNet、用于对象检测的 detectNet、用于语义分割的 segNet、用于姿势估计的 poseNet 和用于动作识别的 actionNet。提供了从实时摄像头源进行流式传输、使用 WebRTC 制作 Web 应用程序以及对 ROS/ROS2 的支持的示例。 |
| Stable Diffusion WebUI ★★★★★ |
使用 Gradio 库实现的Stable Diffusion的 Web 界面。 简体中文翻译扩展 |
| Zhouyi-AIPU/Model Zoo ★★★ |
各种Embedded model汇总 |
| HuggingFace/Pytorch image models ★ |
最大的 PyTorch 图像 encoders / backbone 集合。包括训练、评估、推理、导出脚本和预训练权重 - ResNet、ResNeXT、EfficientNet、NFNet、Vision Transformer (ViT)、MobileNetV4、MobileNet-V3 & V2、RegNet、DPN、CSPNet、Swin Transformer、MaxViT、CoAtNet、ConvNeXt 等 |
| HuggingFace/Datasets ★ |
Datasets 是一个轻量级库,提供两个主要功能:适用于许多公共数据集的单行数据加载器;高效的数据预处理。 |
| HuggingFace/Accelerate ★ |
Accelerate 是为那些喜欢编写 PyTorch 模型训练循环但不愿意编写和维护使用多 GPU/TPU/fp16 所需的样板代码的 PyTorch 用户创建的。 |
| Stability-AI/Generative Models ★ |
Generative Models by Stability AI |
| Stability-AI/Stable Diffusion ★ |
此存储库包含从头开始训练的 Stable Diffusion 模型,并将使用新的检查点不断更新。 |
| TensorFlow ★ |
An Open Source Machine Learning Framework for Everyone |
| TensorFlow Models ★ |
Models and examples built with TensorFlow |
| Ultralytics/ultralytics ★ |
Ultralytics YOLOv8 是一款尖端的、最先进的 (SOTA) 模型,它以之前 YOLO 版本的成功为基础,并引入了新功能和改进,以进一步提高性能和灵活性。YOLOv8 旨在快速、准确且易于使用,使其成为各种对象检测和跟踪、实例分割、图像分类和姿势估计任务的绝佳选择。 |
| Karpathy/llama2.c ★ |
在 PyTorch 中训练 Llama 2 LLM 架构,然后使用一个简单的 700 行 C 文件 (run.c) 进行推理。 |
| GPT2-Chinese ★ |
中文的GPT2训练代码,使用BERT的Tokenizer或Sentencepiece的BPE model |
| openai-cookbook ★★ |
使用 OpenAI API 完成常见任务的示例代码和指南。 |
| ONNX ★★★ |
开放神经网络交换(ONNX)是一个开放的生态系统,使人工智能开发人员能够随着项目的发展选择合适的工具。ONNX为人工智能模型提供了一种开源格式,包括深度学习和传统ML,它定义了一个可扩展的计算图模型,以及内置运算符和标准数据类型的定义。目前我们专注于推理(评分)所需的功能。 |
| Microsoft/ONNX Runtime ★ |
ONNX Runtime 是一个跨平台推理和训练机器学习加速器。 |
| onnx-tensorrt ★★ |
解析 ONNX 模型以便使用 TensorRT 执行。 NVIDIA® TensorRT™ 是一个用于高性能深度学习推理的 API 生态系统。TensorRT 包括推理运行时和模型优化,可为生产应用程序提供低延迟和高吞吐量。TensorRT 生态系统包括 TensorRT、TensorRT-LLM、TensorRT 模型优化器和 TensorRT Cloud。 |
| onnx-simplifier ★ |
ONNX 很棒,但有时太复杂。 |
| tensorflow-onnx ★ |
tf2onnx 通过命令行或 python api 将 TensorFlow(tf-1.x 或 tf-2.x)、keras、tensorflow.js 和 tflite 模型转换为 ONNX。 |
| 2. GPU/CUDA/Rocm | |
| CUDA-Learn-Notes ★★★★★ |
CUDA-Learn-Notes: CUDA 笔记、大模型手撕CUDA、C++笔记 |
| CUDA-Programming-Guide-in-Chinese ★ |
本项目为 CUDA C Programming Guide 的中文翻译版。 |
| NN-CUDA-Example ★ |
调用自定义 CUDA 运算符的神经网络工具包(PyTorch、TensorFlow 等)的几个简单示例。 |
| NVTrust ★ |
nvTrust 是一个存储库,其中包含在受信任的环境(例如机密计算)中使用 NVIDIA 解决方案时利用的许多实用程序和工具、开源代码和 SDK。 |
| LLM Guard | LLM 交互的安全工具包 |
| ROCm/ROCT-Thunk-Interface ★ |
此存储库包含用于与 (AMD)ROCk 驱动程序交互的用户模式 API 接口。 |
| 3. 免费资源 | |
| GitHub中文开源仓库排行榜 ★★★★★ |
GitHub中文排行榜,帮助你发现优秀中文项目,可以无语言障碍地、更高效地吸收优秀经验成果 |
| free-programming-books ★★★★★ |
多种语言的免费学习资源列表 |
| Datawhale ★★★★★ |
Datawhale 是一个专注于数据科学与 AI 领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。 |
| OpenBMB ★★★★★ |
OpenBMB (Open Lab for Big Model Base), founded by ModelBest Inc (面壁智能) & TsinghuaNLP, aims to build foundation models and systems towards AGI. |
| CS EBook ★★★ |
超过1000本的计算机经典书籍分享,解压密码:a123654 |
| CS EBook ★★★ |
本储存库是一些高质量的计算机科学与技术书籍推荐书单,需要学习的可以按照此书单进行学习进阶,包含了计算机大多数软件相关方向。而且敢承诺一直更新。 |
| zhoucz97/myLearning | 记录个人的学习历程。包括但不限于算法、机器学习、论文写作等。 |
| 李宏毅深度学习教程LeeDL-Tutorial(苹果书) | 本教程主要内容源于《机器学习》(2021年春),并在其基础上进行了一定的原创。比如,为了尽可能地降低阅读门槛,笔者对这门公开课的精华内容进行选取并优化,对所涉及的公式都给出详细的推导过程,对较难理解的知识点进行了重点讲解和强化,以方便读者较为轻松地入门。此外,为了丰富内容,笔者在教程中选取了《机器学习》(2017年春) 的部分内容,并补充了不少除这门公开课之外的深度学习相关知识。 |
论文
Attention is All Your Need 中英对照
datawhale

Datawhale 是一个专注于数据科学与 AI 领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。
Datawhale 以“ for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
官网:https://linklearner.com/
课程:https://linklearner.com/learn
Github:https://github.com/datawhalechina
课程:
LLM 相关仓库:
- 大模型基础: 一文了解大模型基础知识
- 面向开发者的大模型手册 - LLM Cookbook
- 基于transformers的自然语言处理(NLP)入门
- 动手学LLM, 从0逐步构建GLM4\Llama3\RWKV6, 深入理解大模型原理
- 《开源大模型食用指南》基于Linux环境快速部署开源大模型,更适合中国宝宝的部署教程
- 面向小白开发者的大模型应用开发教程
补充:
李沐
machine learning sys blog
机器人
- Nvidia cosmos
- NVIDIA Cosmos for Developers
- Cosmos World Foundation Model Platform for Physical AI
- Hugging face model
pytorch 知识点整理
《深度学习框架 PyTorch: 入门与实战》
- 安装Pytorch
- 基本操作,如cat等
- 准备一个cifar-10模型,并训练推理
| 概要 | 内容 |
|---|---|
| 基本操作 | Tensor(*sizes), tensor(data) ones/zeros/eye(*sizes) arrange(start, end, step), linspace(start, end, steps) rand / randn(*sizes) new_* / *_like() |
| 命名张量 | names, refine_names, rename, align_to |
| 类型 | set_default_tensor_type, type(new_type) == .float(), .long(), .half(), to(device) |
| 索引 | index_select(input, dim, index) masked_select(input, mask) gather(input, dim, index) input.scatter_(dim, index)放回 non_zero(input)非零下标 |
| 元素操作 | abs/sqrt/div/exp/fmod/log/pow, cos/sin/asin/atan2/cosh, ceil/round/floor/trunc, clamp(input,min,max), sigmod/tanh, cumsum/cumprod |
| 归并操作 | mean/sum/median/mode, norm/dist, std/var, keepdim=True 保留维度, 在哪个维度操作, 哪个维度变成1,或者消失 |
| 比较 | gt/lt/ge/le/eq/ne, topk, sort, max/min |
| 线性代数 | trace, diag, triu/tril, mm/bmm, addmm/addbmm/addmv, t, dot/cross, inverse, svd |
| Numpy | from_numpy,共享内存 torch.tensor()只进行数据拷贝, 不会共享内存 torch.Tensor()在类型不一致时是复制而非共享内存 |
| Tensor基本结构 | storage()查看是否共享, contiguous()变成连续 |
| Tensor改变形状 | 查看信息, size() = shape, dim() = len(tensor.shape), numel <=> numpy.size 改变维度, reshape(), view(), view_as() 增加减少维度, squeeze()压缩, unsqueeze()新建维度, flatten(start_dim, end_dim) 转置, transpose()仅限二维, t(), T, permute() |
| 线性回归实例 | 手动计算求导函数 |
| autograd | requires_grad=True, retain_graph=None, is_leaf, backward() |
| 用autograd实现线性回归 | 自动backward, 梯度下降 |
torch.nn是专门为深度学习而设计的模块。torch.nn的核心数据结构是Module,它是一个抽象的概念,既可以表示神经网络中的某个层(layer),也可以表示一个包含很多层的神经网络。在实际使用中,最常见的做法是继承nn.Module,从而编写自己的网络/层。多层感知机的网络结构如图所示,它由两个全连接层组成,采用$sigmoid$函数作为激活函数(图中没有画出)。

PyTorch内部实现了神经网络中绝大多数的layer,这些layer都继承于nn.Module,封装了可学习参数parameter,并实现了forward函数。同时,大部分layer都专门针对GPU运算进行了CuDNN优化,其速度和性能都十分优异。关注每一层的信息有:
- 构造函数的参数,如nn.Linear(in_features, out_features, bias),需关注这三个参数的作用;
- 属性、可学习参数和子module。如nn.Linear中有
weight和bias两个可学习参数,不包含子module; - 输入输出的形状,如nn.linear的输入形状是(N, input_features),输出为(N,output_features),其中N是batch_size。
图像nn包括,卷积层(Conv)、池化层(Pool),池化方式又分为平均池化(AvgPool)、最大值池化(MaxPool)、自适应池化(AdaptiveAvgPool)等。而卷积层除了常用的前向卷积之外,还有逆卷积(TransposeConv)。卷积神经网络的本质就是卷积层、池化层、激活层以及其他层的叠加。池化层可以看作是一种特殊的卷积层,其主要用于下采样,增加池化层可以在保留主要特征的同时降低参数量,从而一定程度上防止了过拟合。池化层没有可学习参数,它的weight是固定的。在torch.nn工具箱中封装好了各种池化层,常见的有最大池化(MaxPool)和平均池化(AvgPool)。
安装 pytorch cpu 版本
https://pytorch.org/get-started/previous-versions/
安装 Anaconda. 下载地址: https://www.anaconda.com/download
1 | |
换源
1 | |
创建Pytorch虚拟环境
1 | |
创建过程的log
1 | |
激活环境
1 | |
安装Pytorch 1.6
1 | |
安装的log
1 | |
Conda删除环境
1 | |
不用Anaconda,使用python虚拟env
1 | |
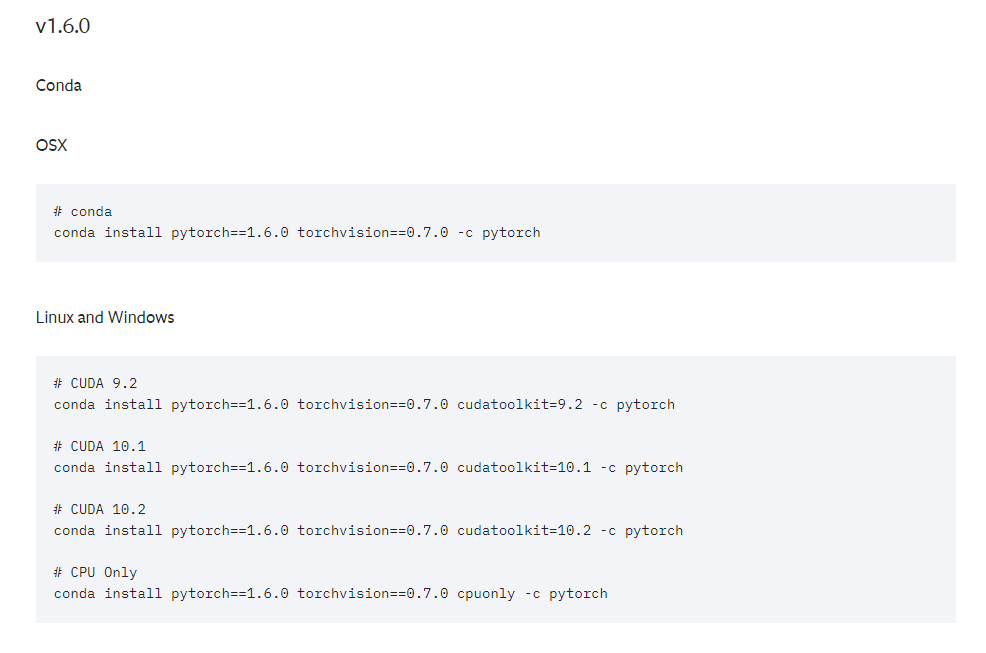
安装 pytorch cuda 版本
在RTX4070S windows中配置WSL相关的AI环境,包括CUDA,PyTorch,Cudnn等
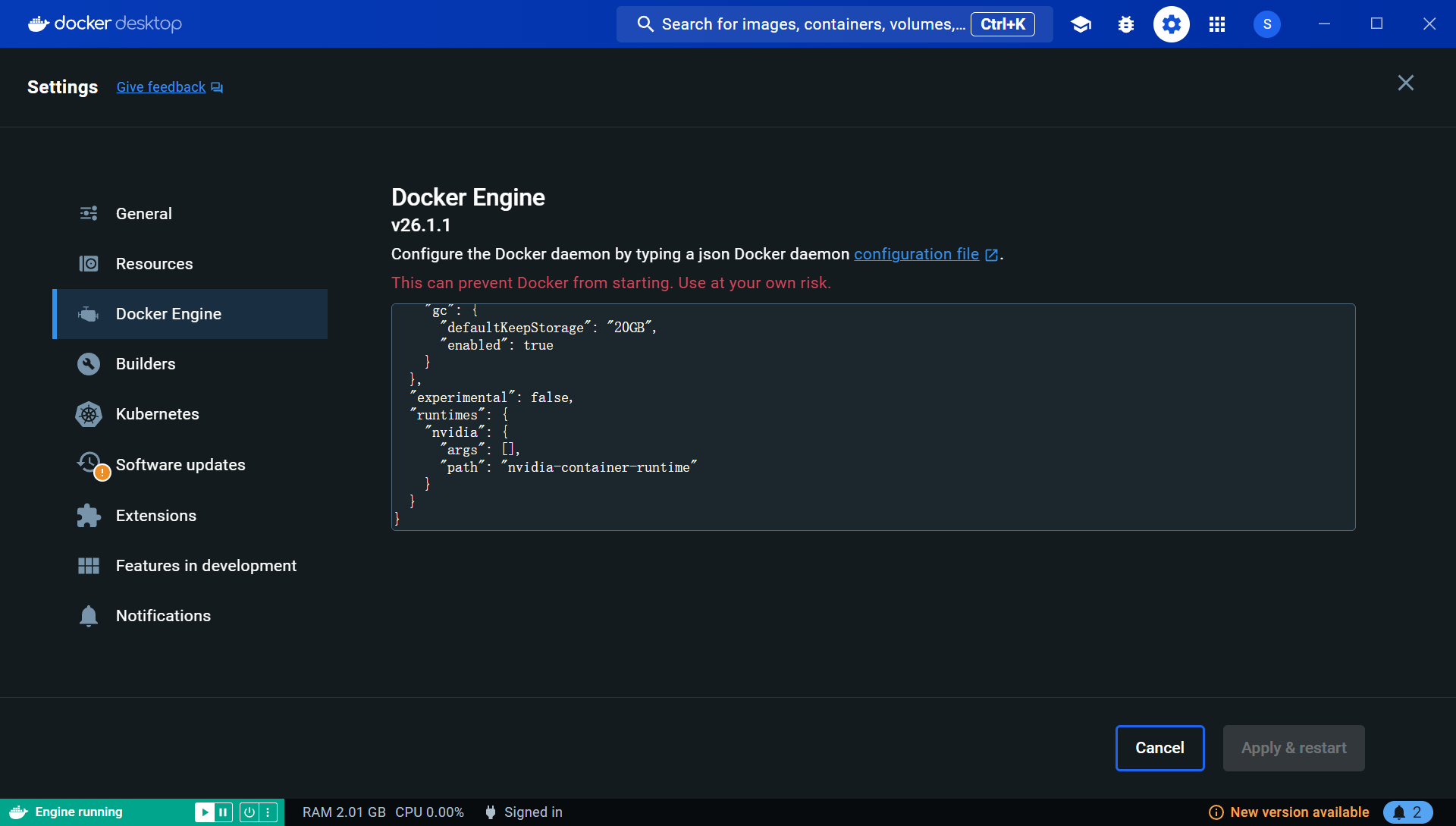
安装WSL/Docker/Nvidia:
Windows 下让 Docker Desktop 关联上 NVidia GPU
如何查看wsl是wsl1还是wsl2
Nvidia WSL官方指引
linux上cuda相关包与opencv及相关模块安装(wsl+ubuntu22.04)
注意:WSL不需要装cuda驱动,丢在win host安装,比如Geforce等驱动软件,安装完成后运行
nvidia-smi
1 | |
Docker Desktop中的设置:
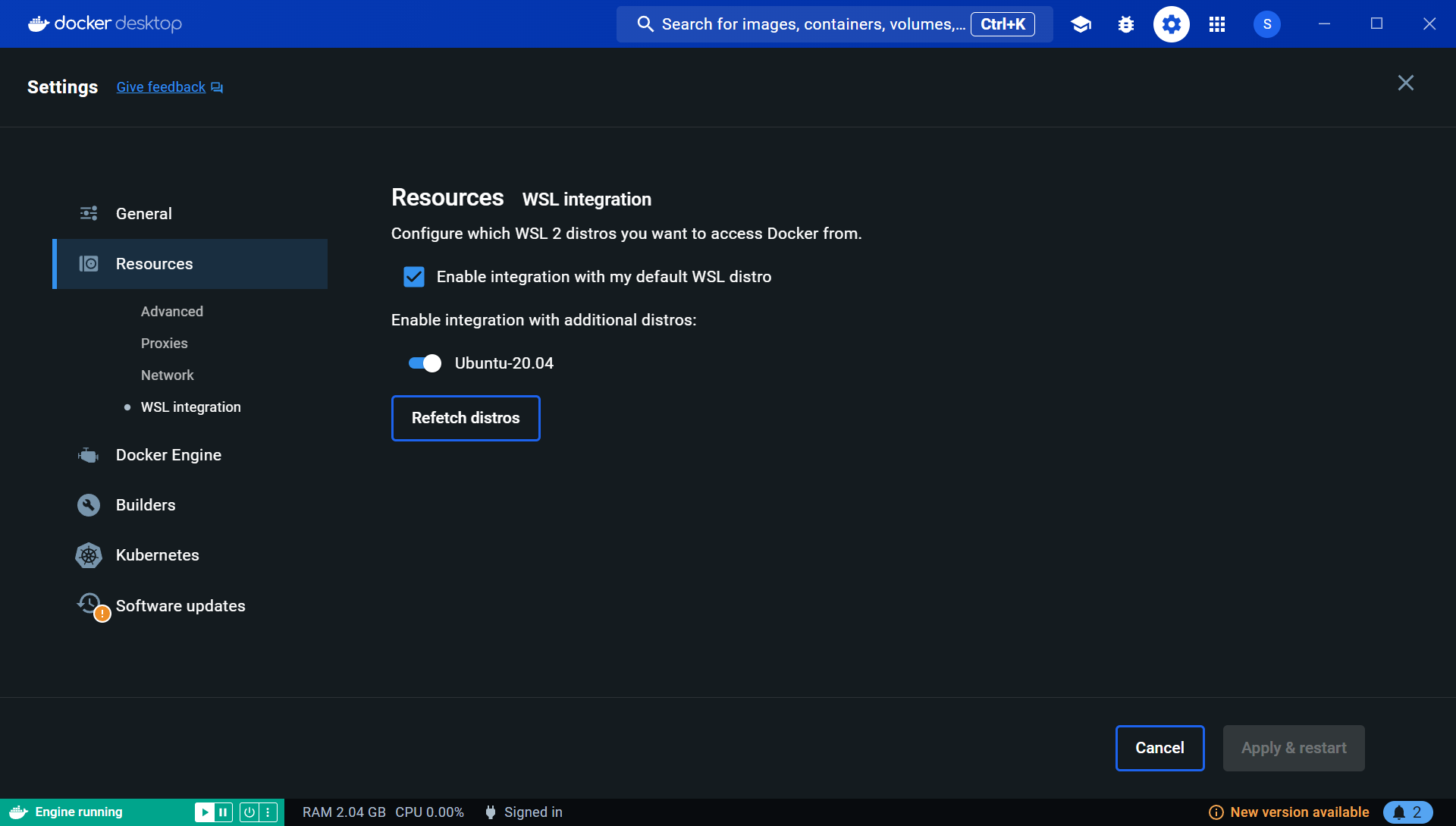
测试结果:
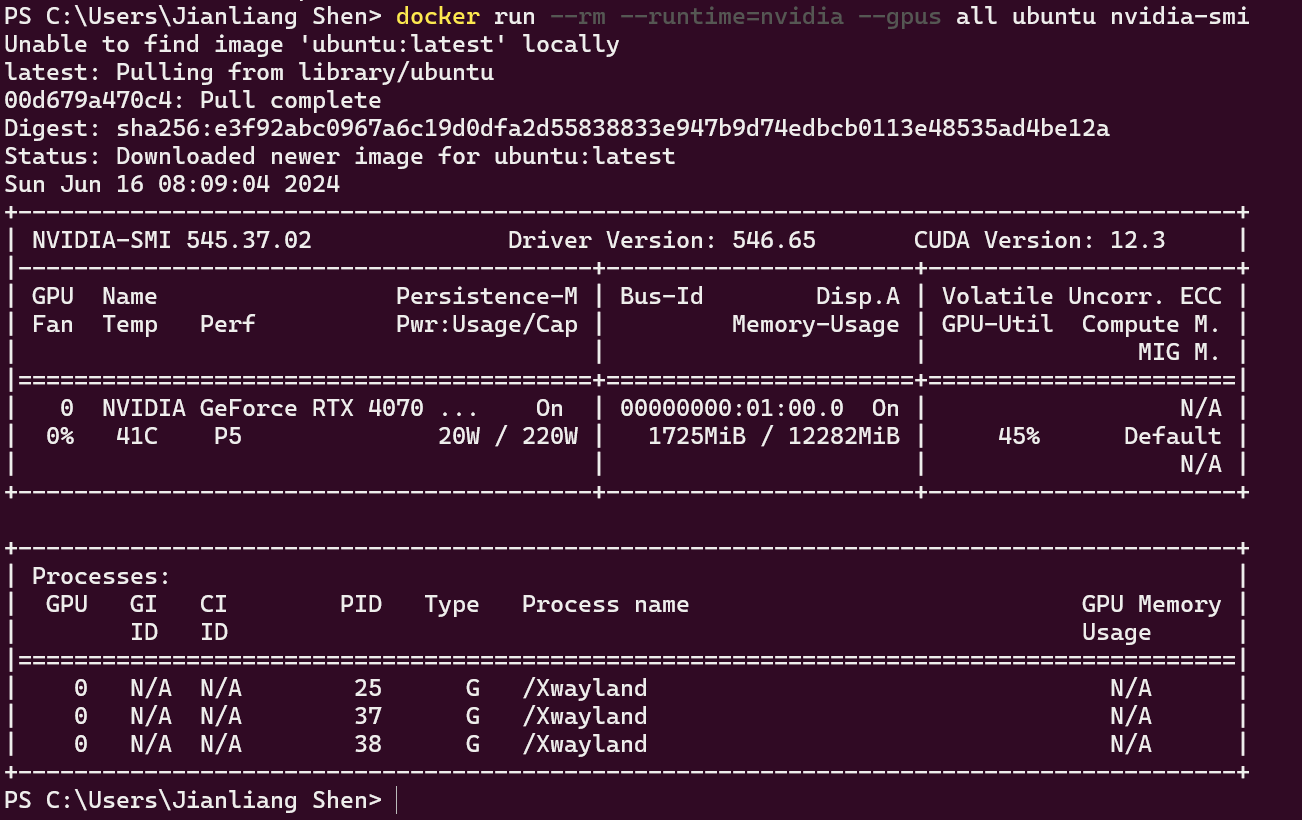
WSL中测试:
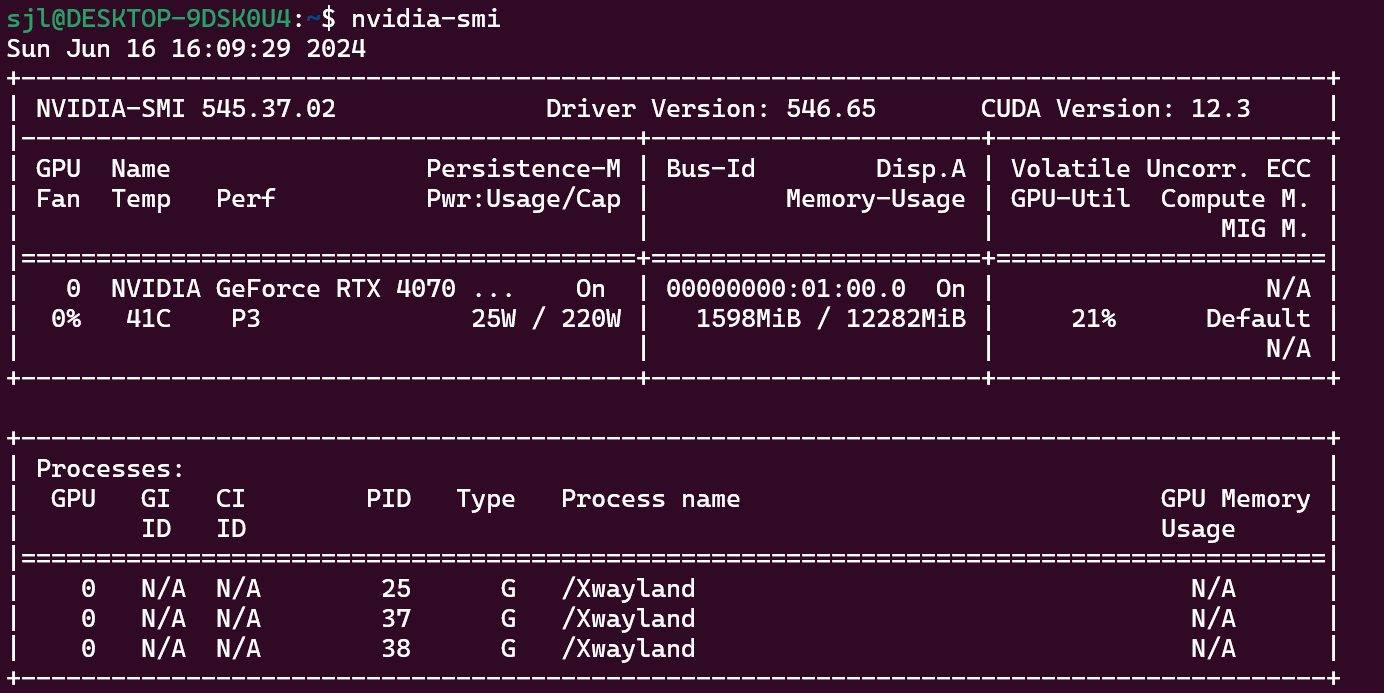
1 | |
安装Conda
1 | |
安装cuDNN:https://developer.nvidia.com/cudnn-downloads
1 | |
pytorch book vscode 环境配置
1 | |
VScode安装插件
此时打开任意一个note可以看到代码变成可以执行的框了:
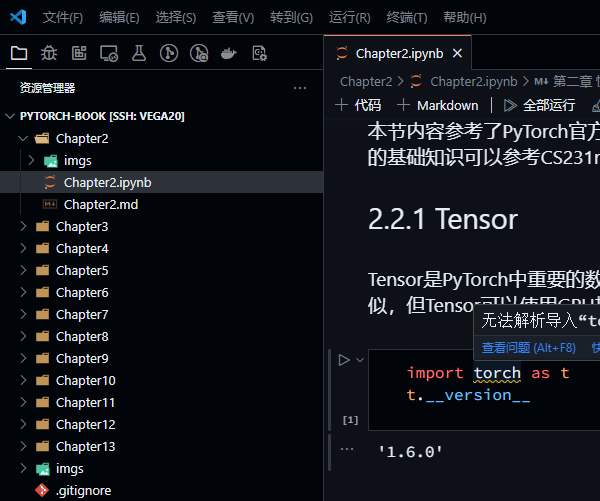
但是会显示torch未导入,点击左侧的执行三角形按钮,会提示选择安装必要的插件,安装完成后再次点击,会提示选择python版本

选择python环境,找到conda路径下的python解释器
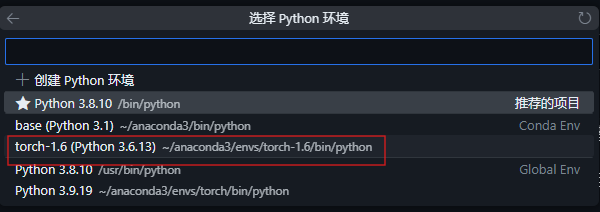
再次点击左侧运行,弹出要安装pykernel包,点击安装完成后,可以在右上角看到环境和python版本,也可以点击此处继续更换环境。
示例
线性回归
梯度下降算法和auto grad自动求解梯度函数,参考 《深度学习框架PyTorch:入门与实战》代码 小试牛刀: 用autograd实现线性回归。
fashion mnist 手写数字分类
参考Pytorch教程: Quick Start
- 下载数据集
- 数据预处理等Data Tutorial
- 定义model,类型、层、前向函数和损失计算函数,并传递至device,如CPU或者CUDA,Build Model
- Sequential,构建连续的层pytorch系列 nn.Sequential讲解
- 一些层级的简单介绍,nn 网络层:池化层、线性层和激活函数层
- 优化损失计算,Optimization Tutorials
- 训练,导入数据,计算损失,调用前向函数
- 测试,对测试集预测,计算预测结果争取率
- 保存模型,Save & Load & Run
1 | |
cifar 10
参考 《深度学习框架PyTorch:入门与实战》代码 2.2.4 小试牛刀:CIFAR-10分类。