Llama Local Deployment
Chinese-LLaMA-Alpaca 是基于 Meta 发布的可商用大模型 Llama 开发,llama.cpp 是一个 C++ 语言部署 Llama 的框架。
llama 2
部署
注:FP16版本较慢,可以下q8_0或Q6_K,非常接近F16模型的效果。
1 | |
chat.sh内容:
1 | |
GPU版本需要用-ngl 40参数指定(必须编译CUDA版本)。
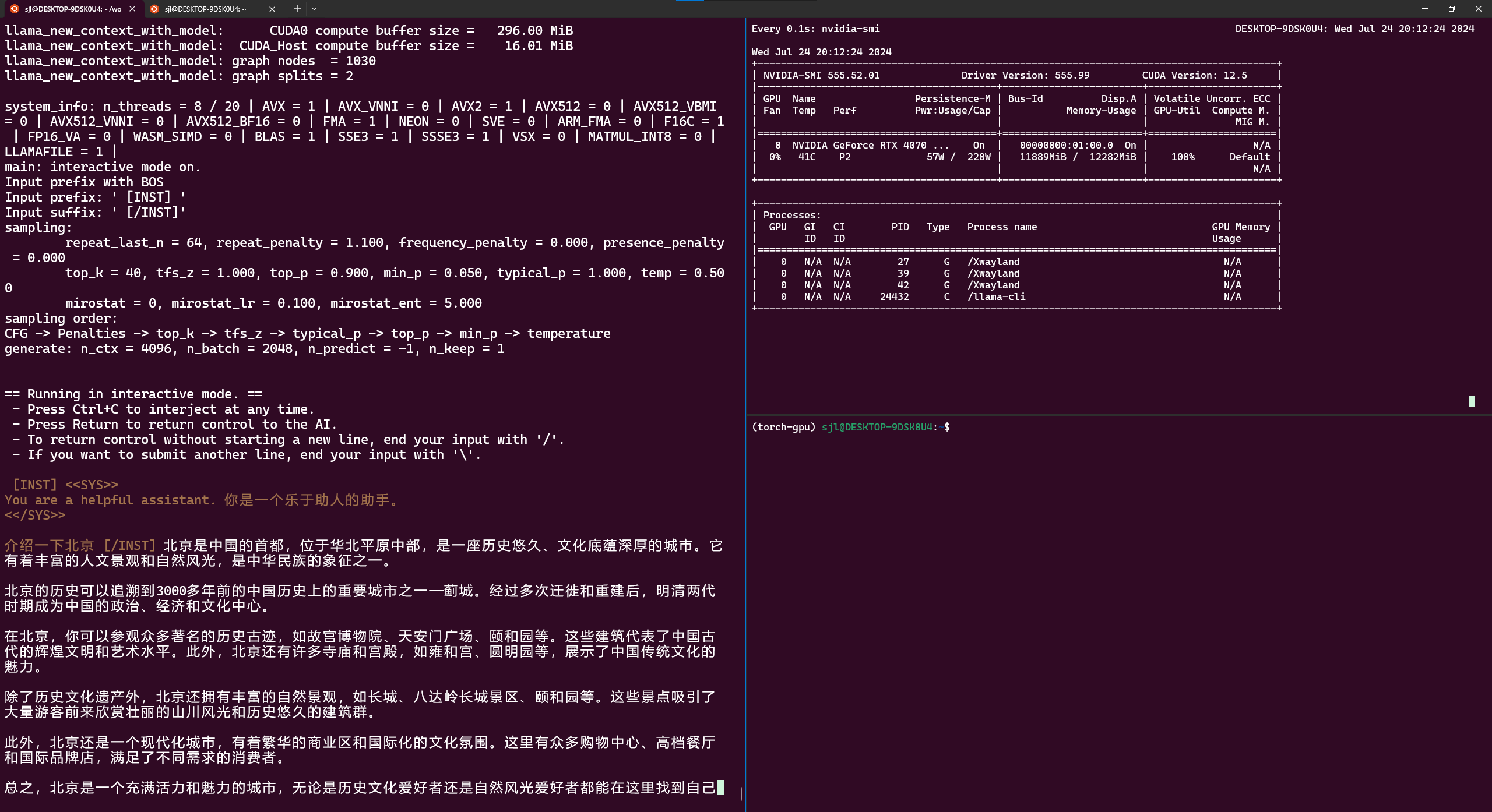
server 设置
1 | |
创建一个client脚本:
1 | |
1 | |
1 | |
Jetson Orin Nano
- Your GPU Compute Capability
- chinese-alpaca-2-1.3b-gguf 下载
q_2k版本,其他未测试
因为cuda版本低,编译llama.cpp前需要指定计算能力:
1 | |
其他配置同上
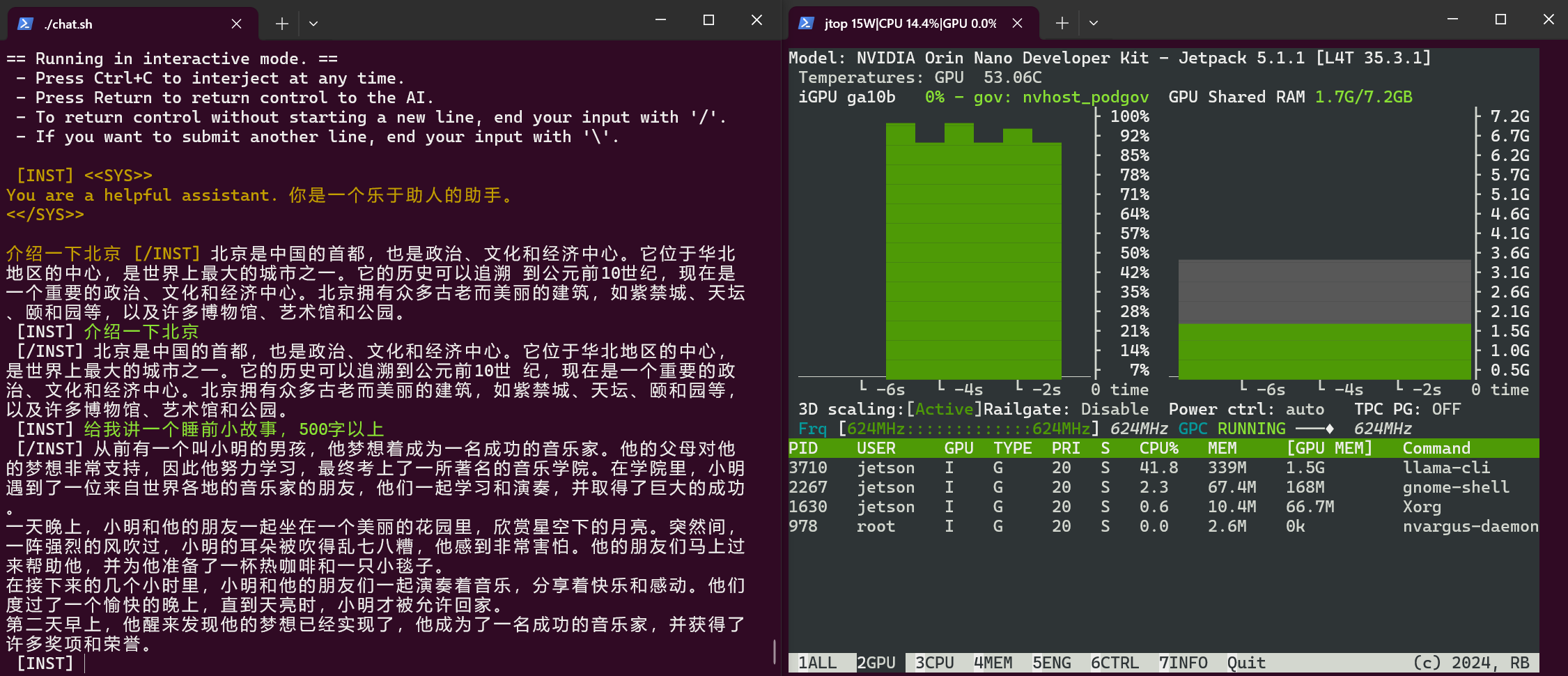
第一次执行导入模型会很慢,之后会变快很多。图右边为jtop指令显示GPU占用情况。
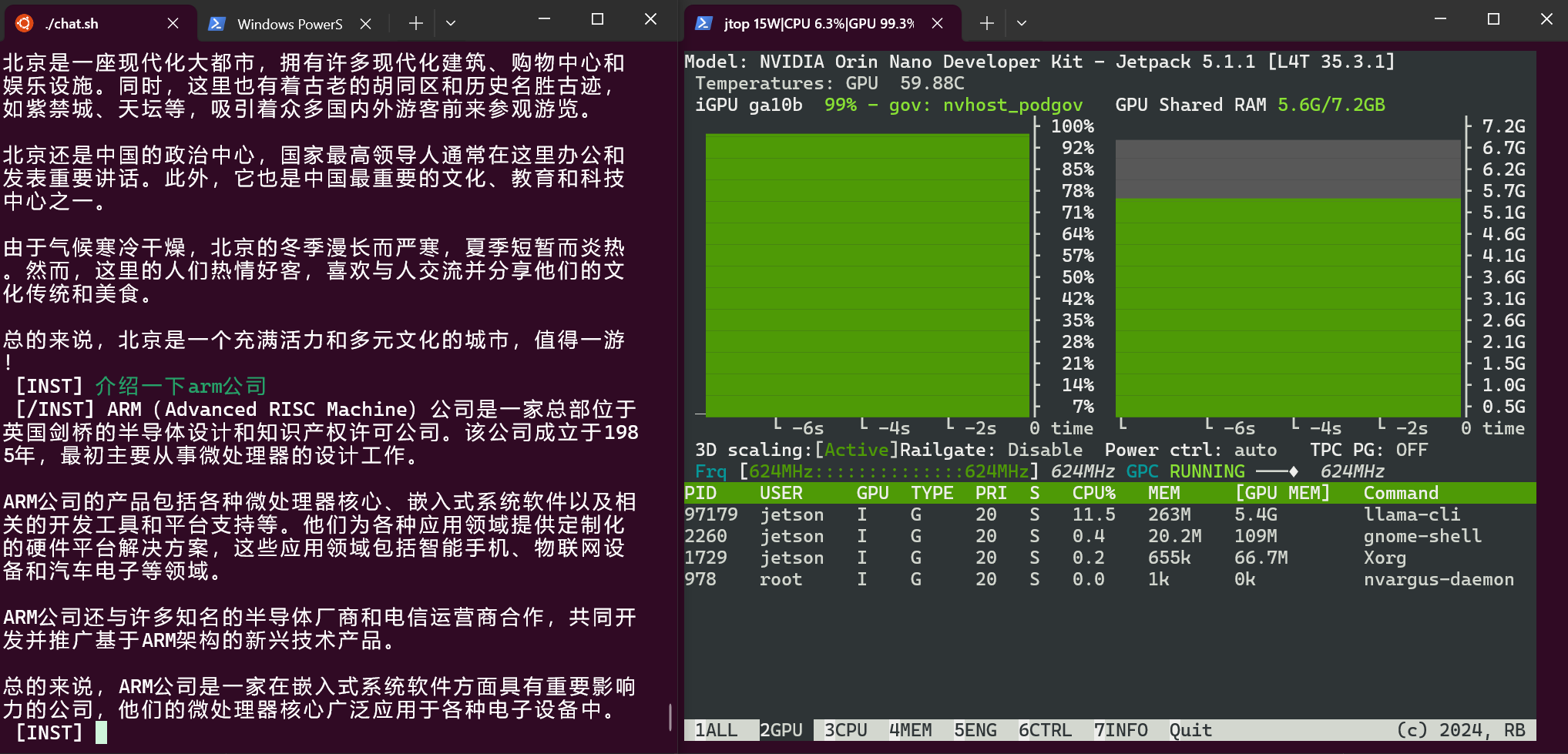
测试长上下文 7B q_2k: chinese-alpaca-2-7b-64k-gguf, 显著提高了显存占用率。
Jetson + WebUI
参考:
1 | |
打开http://JETSON_IP:8080:
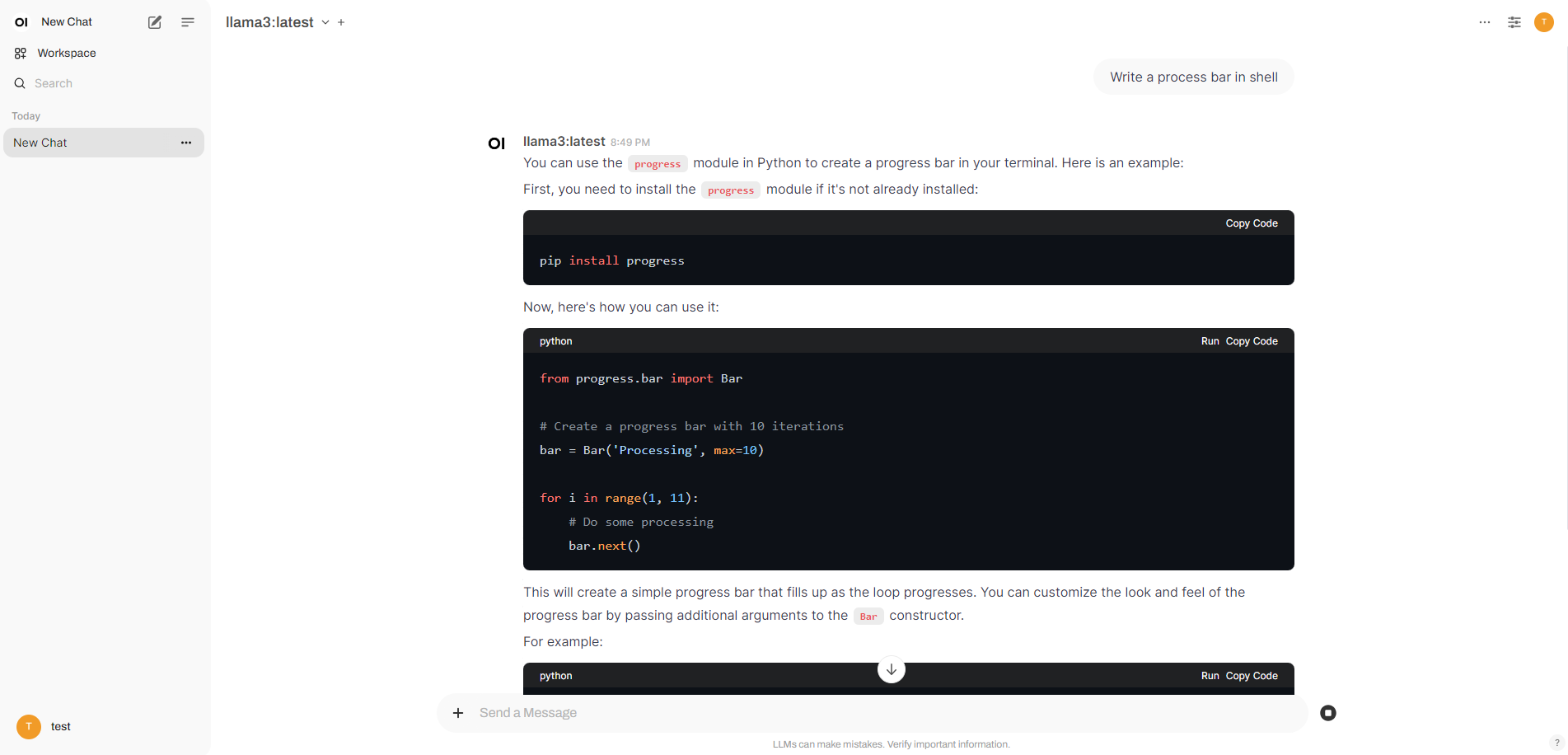
ollama 部署
首次运行ollama run llama3,会联网加载模型:
1 | |
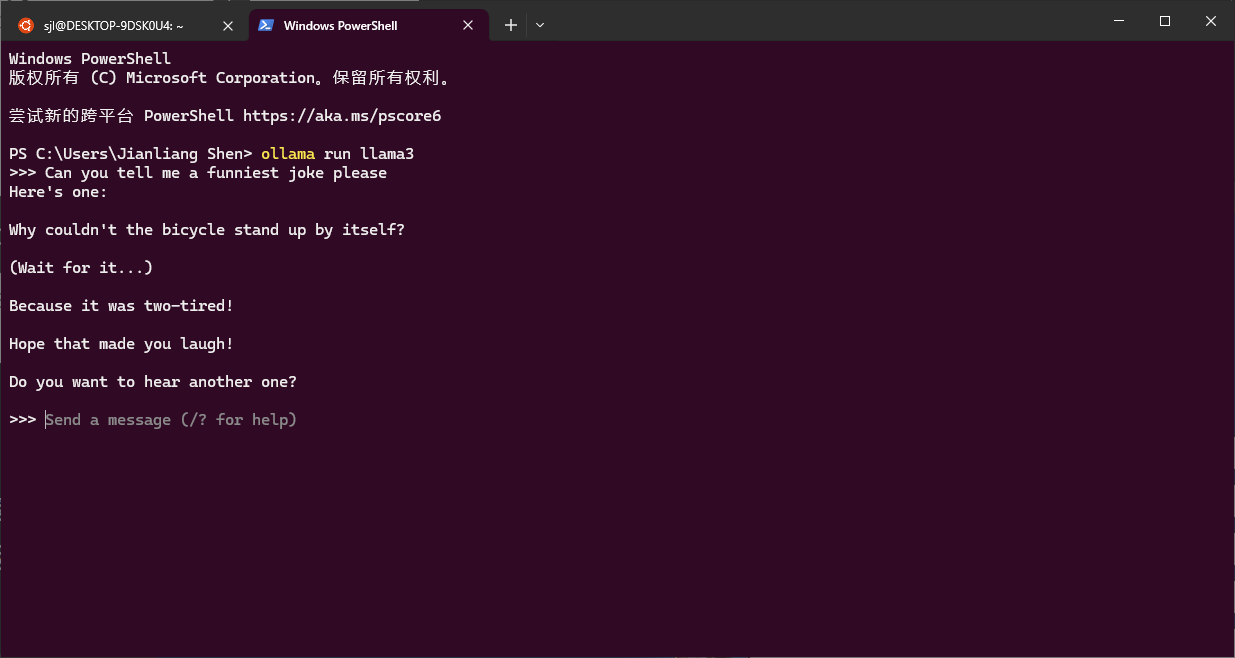
实测是自动运行了GPU加速的。
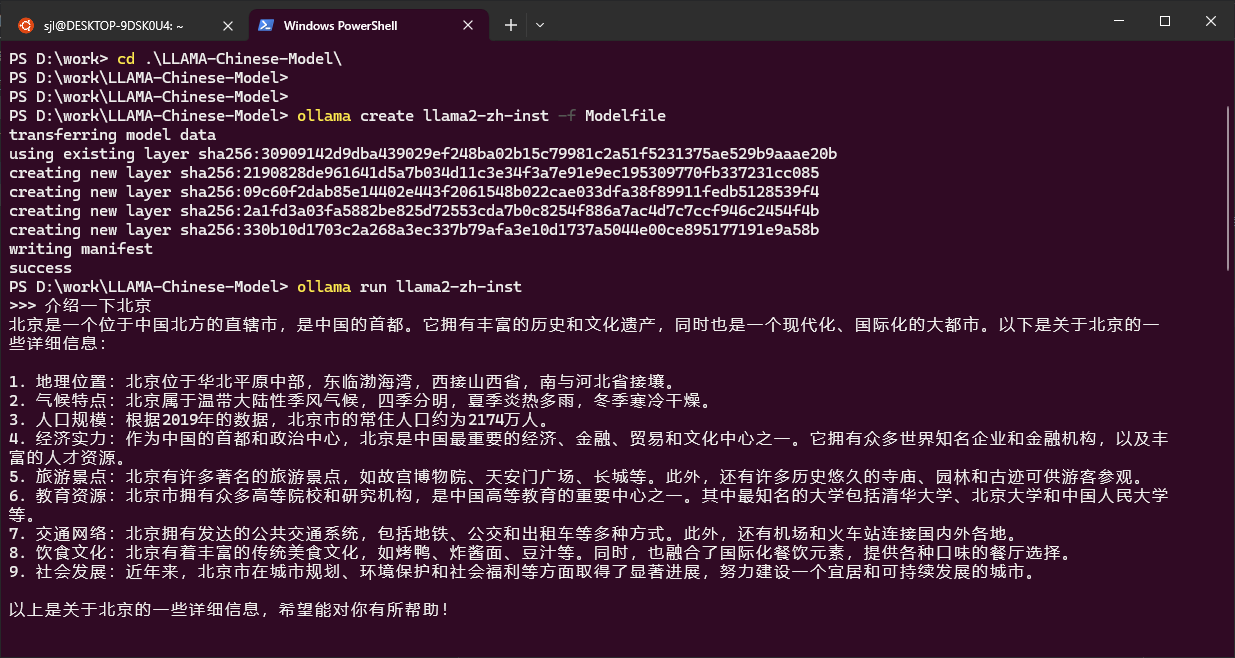
体验本地中文LLama2大模型,参考使用Ollama进行聊天,Modelfile如下:
1 | |
模型下载
模型选择指引
以下是中文LLaMA-2和Alpaca-2模型的对比以及建议使用场景。如需聊天交互,请选择Alpaca而不是LLaMA。[1]
| 对比项 | 中文LLaMA-2 | 中文Alpaca-2 |
|---|---|---|
| 模型类型 | 基座模型 | 指令/Chat模型(类ChatGPT) |
| 已开源大小 | 1.3B、7B、13B | 1.3B、7B、13B |
| 训练类型 | Causal-LM (CLM) | 指令精调 |
| 训练方式 | 7B、13B:LoRA + 全量emb/lm-head; 1.3B:全量 | 7B、13B:LoRA + 全量emb/lm-head; 1.3B:全量 |
| 基于什么模型训练 | 原版Llama-2(非chat版) | 中文LLaMA-2 |
| 训练语料 | 无标注通用语料(120G纯文本) | 有标注指令数据(500万条) |
| 词表大小[2] | 55,296 | 55,296 |
| 上下文长度[3] | 标准版:4K(12K-18K); 长上下文版(PI):16K(24K-32K); 长上下文版(YaRN):64K | 标准版:4K(12K-18K); 长上下文版(PI):16K(24K-32K); 长上下文版(YaRN):64K |
| 输入模板 | 不需要 | 需要套用特定模板[4],类似Llama-2-Chat |
| 适用场景 | 文本续写:给定上文,让模型生成下文 | 指令理解:问答、写作、聊天、交互等 |
| 不适用场景 | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
| 偏好对齐 | 无 | RLHF版本(1.3B、7B) |
完整模型下载
以下是完整版模型,直接下载即可使用,无需其他合并步骤。推荐网络带宽充足的用户。
| 模型名称 | 类型 | 大小 | 下载地址 | GGUF |
|---|---|---|---|---|
| Chinese-LLaMA-2-13B | 基座模型 | 24.7 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-LLaMA-2-7B | 基座模型 | 12.9 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-LLaMA-2-1.3B | 基座模型 | 2.4 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-Alpaca-2-13B | 指令模型 | 24.7 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-Alpaca-2-7B | 指令模型 | 12.9 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-Alpaca-2-1.3B | 指令模型 | 2.4 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
长上下文版模型
以下是长上下文版模型,推荐以长文本为主的下游任务使用,否则建议使用上述标准版。
| 模型名称 | 类型 | 大小 | 下载地址 | GGUF |
|---|---|---|---|---|
| Chinese-LLaMA-2-7B-64K 🆕 | 基座模型 | 12.9 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-Alpaca-2-7B-64K 🆕 | 指令模型 | 12.9 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-LLaMA-2-13B-16K | 基座模型 | 24.7 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-LLaMA-2-7B-16K | 基座模型 | 12.9 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-Alpaca-2-13B-16K | 指令模型 | 24.7 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
| Chinese-Alpaca-2-7B-16K | 指令模型 | 12.9 GB | [Baidu] [Google] [🤗HF] [🤖ModelScope] | [🤗HF] |
llama 3
模型下载
| 模型名称 | 完整版 | LoRA版 | GGUF版 |
|---|---|---|---|
| Llama-3-Chinese-8B-Instruct-v3(指令模型) | [🤗Hugging Face] [🤖ModelScope][🟣wisemodel] | N/A | [🤗Hugging Face] [🤖ModelScope] |
| Llama-3-Chinese-8B-Instruct-v2(指令模型) | [🤗Hugging Face] [🤖ModelScope][🟣wisemodel] | [🤗Hugging Face] [🤖ModelScope][🟣wisemodel] | [🤗Hugging Face] [🤖ModelScope] |
| Llama-3-Chinese-8B-Instruct(指令模型) | [🤗Hugging Face] [🤖ModelScope][🟣wisemodel] | [🤗Hugging Face] [🤖ModelScope][🟣wisemodel] | [🤗Hugging Face] [🤖ModelScope] |
| Llama-3-Chinese-8B(基座模型) | [🤗Hugging Face] [🤖ModelScope][🟣wisemodel] | [🤗Hugging Face] [🤖ModelScope][🟣wisemodel] | [🤗Hugging Face] [🤖ModelScope] |
部署
- llama.cpp 部署
chat_llama3.sh:
1 | |
- 运行:
1 | |
ollama 部署
Modelfile_llama3:
1 | |
- 运行
1 | |
指令微调
- 模型下载:llama-3-chinese-8b-instruct-v3
- 数据:ruozhiba_gpt4
- 训练参考:指令精调脚本
训练示意图:
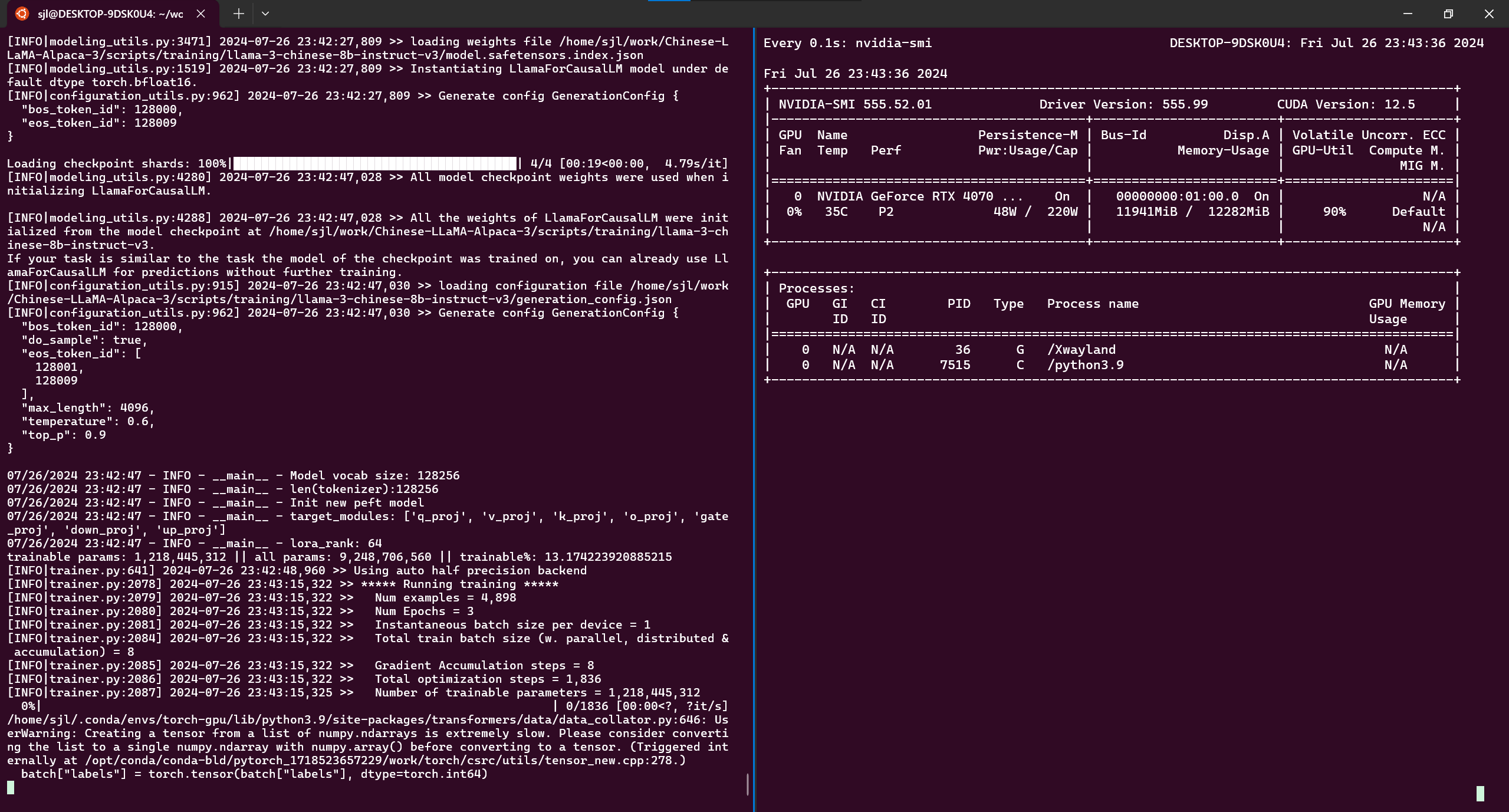
报错:显存不足
在魔塔社区使用GPU实例:
训练脚本:
1 | |
其中一些参数的含义不言自明。部分参数的解释如下:
- –dataset_dir: 指令精调数据的目录,包含一个或多个以json结尾的Stanford Alpaca格式的指令精调数据文件
- –validation_file: 用作验证集的单个指令精调文件,以json结尾,同样遵循Stanford Alpaca格式
- –use_flash_attention_2: 启用FlashAttention-2加速训练
- –load_in_kbits: 可选择参数为16/8/4,即使用fp16或8bit/4bit量化进行模型训练,默认fp16训练。
- –modules_to_save:需要额外训练的模块,注意这部分是全量精调;资源受限的情况下请设置为None(效果也会受到一些影响)
训练过程:
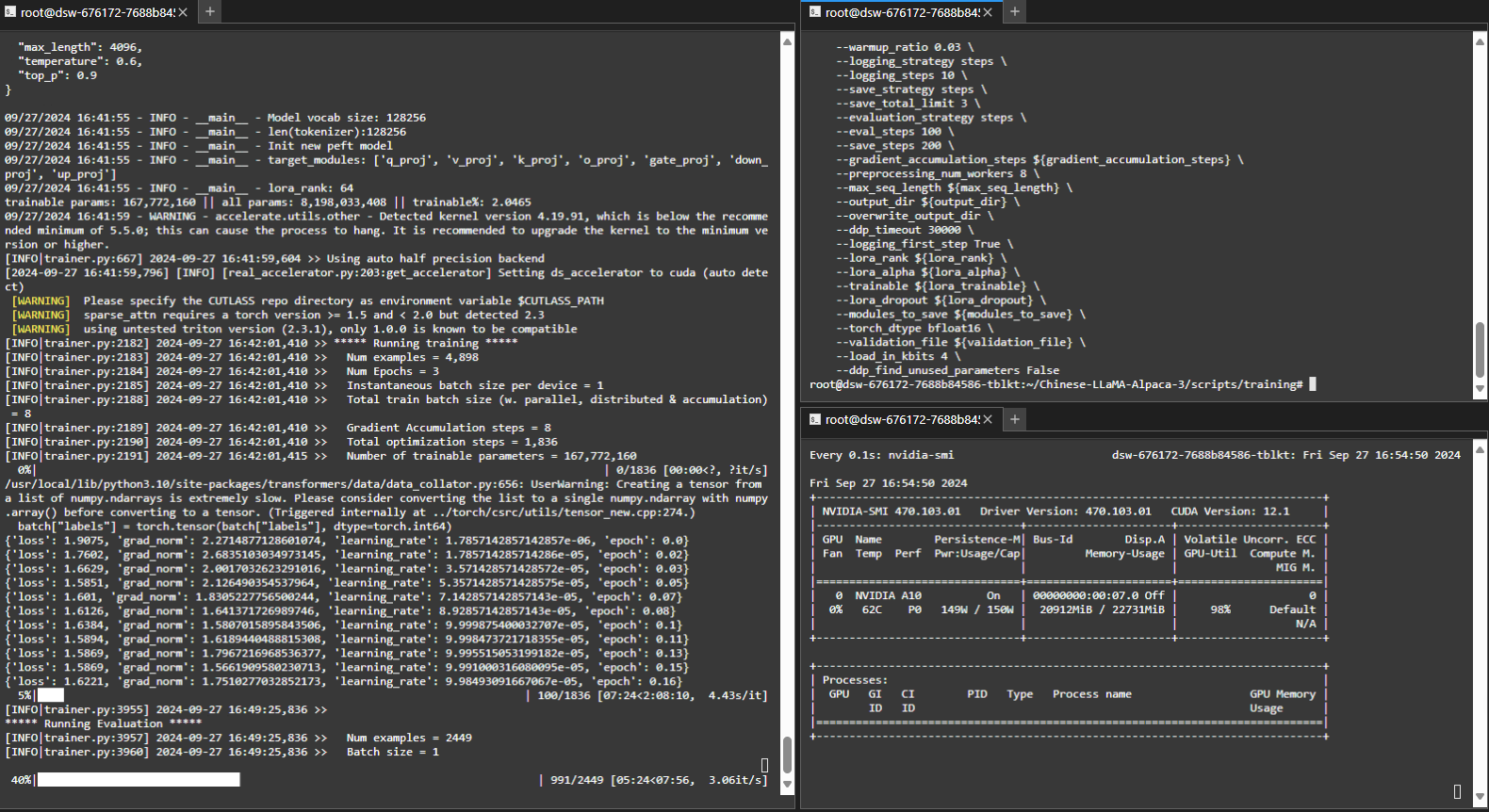
实测,int4,缺省modules_to_save 要 20GB,难怪我的小卡爆显存。
魔塔社区可以关闭网页,下次进来还是当前窗口。注意,单次实例只有10h,不会保存任何文件。
训练完成:
1 | |
在最后一次checkpoint文件夹里:
1 | |
TODO: 参考 https://github.com/ymcui/Chinese-LLaMA-Alpaca-3/wiki/llamacpp_zh 量化模型,尝试调用。