机密计算: 大模型安全解决方案
随着大模型技术的高速发展,大模型在各个领域的应用日益广泛,从科研到商业,再到日常生活、办公等方方面面。
大模型安全的重要性
首先,大模型在许多应用场景中处理大量敏感数据和个人信息,如用户的搜索记录、社交媒体互动和金融交易等。这使得数据泄露和隐私侵犯的风险不容忽视。一旦这些敏感信息遭受泄露,个人隐私权益可能会受到严重损害,甚至被用于恶意行为,如身份盗窃、诈骗和社会工程攻击。这不仅会对受害者造成经济损失,还可能导致社会的恐慌和不信任。
其次,大模型的强大能力也可能被用于进行各种形式的恶意攻击。模型的对抗性样本攻击,即针对模型的输入进行微小改动,从而欺骗模型产生错误预测,已成为一种常见的威胁。恶意使用者可以通过这种方式制造虚假信息,影响决策结果,如将误导性的信息传播到社交媒体平台,从而扰乱社会秩序。此外,大模型的生成能力也可能被用于生成虚假的内容,威胁到媒体的可信度和新闻的真实性。
另外,模型本身也可能成为攻击者的目标。模型参数和权重的泄露可能导致知识产权的损失,甚至使恶意使用者能够复制或修改模型,进一步恶化风险。对模型的针对性攻击,如投毒攻击,可能使模型的输出产生不良影响,从而影响到正常的业务运行。这些威胁可能在不经意间对企业和社会造成巨大的损失。此外,大模型的使用往往涉及到社会伦理和法律问题。例如,算法的歧视性问题,即模型在处理数据时产生的不公平或偏见,可能引发社会的不满和争议。
此外,大模型可能会被用于传播虚假信息、仇恨言论或不当内容,从而引发社会不安定和文化冲突。
最后,国家网信办联合国家发展改革委、教育部、科技部、工业和信息化部、公安部、广电总局公布《生成式人工智能服务管理暂行办法》,自2023年8月15日起施行,旨在促进生成式人工智能健康发展和规范应用,维护国家安全和社会公共利益,保护公民、法人和其他组织的合法权益。这既是促进生成式人工智能健康发展的重要要求,也是防范生成式人工智能服务风险的现实需要。
因此,确保大模型的安全性和可信度是一个紧迫的任务。需要综合运用技术手段、政策法规以及社会共识,建立起一套全面的大模型安全风险管理体系。通过逐一应对数据隐私保护、模型防御、内容合规、恶意行为检测等方面的挑战,我们能够更好地应对现实中的安全风险,保障个人权益和社会稳定。这也是本白皮书所要探讨的核心议题之一。
安全挑战与潜在威胁
- 数据安全与隐私问题
- 传输截获风险
- 运营方窥探风险
- 模型记忆风险
- 模型流转/部署过程中的安全问题
- 模型知识泄漏: 在将模型部署到生产环境中,模型的输出可能会暴露训练数据的一些信息。攻击者可以通过分析模型的输出,推断出训练数据的特征和分布,进而构建类似的数据集,甚至还原部分原始数据。
- 模型逆向工程: 攻击者可能尝试通过逆向工程技术还原部署模型的架构、权重和训练数据。这可能导致知识产权盗窃、模型盗用和安全漏洞的暴露。逆向工程可能通过模型推理结果、输入输出分析以及梯度攻击等方式进行。
- 输入数据的合法性和安全性:在模型部署阶段,恶意用户可能试图通过提供恶意输入来攻击系统。例如,输入中可能包含恶意代码、命令执行、注入语句或文件包含路径,从而导致安全漏洞。
- 模型更新和演化:模型需要定期更新以保持性能和适应新的数据分布。然而,模型更新可能引入新的漏洞和问题。安全地更新模型需要考虑版本控制、验证新模型的安全性和稳定性,以及备份机制以防产生不良影响。
- AIGC 的内容合规问题
- 个人隐私问题
- Smart Compose 隐私问题
- 语音助手隐私问题
- 个性化内容生成隐私问题
- 虚假信息和误导性内容
- Deepfake 虚假视频
- 虚假新闻和评论
- 制造虚假证据
- 民族仇恨言论和不当内容
- 偏见和歧视问题
- 淫秽色情内容
- 政治/军事敏感内容
- 恐怖/暴力内容
- 版权和知识产权问题
- 滥用和恶意使用
- 责任和透明度
- 责任归属
- 透明度和解释性
- 个人隐私问题
- 大模型运营的业务安全问题
- 前置业务环节
- 大模型交互环节: 在大模型交互环节,本节将分别从用户的“提问行为“和”提问内容“两个维度展开”。首先是提问行为,在针对大模型发起提问时,黑产等不发分子围绕提问接口发起AIGC盗爬/垃圾提问/接口攻击/频控突破/资源侵占等攻击行为;针对大模型输出结果,黑灰产可以发起投毒反馈、恶意反馈等攻击行为。如下图所示,今年北京某公司起诉其多年的合作的伙伴某知名网校品牌,指其近期推出的数学大模型MathGPT和在某品牌学习机上线的AI助手,在未经其授权和许可情况下,爬取了海量数据,要求其公开道歉、删除数据资源,求偿1元,打响了AIGC盗爬的第一案。
- 大模精调/推理环节
大模型安全解决方案
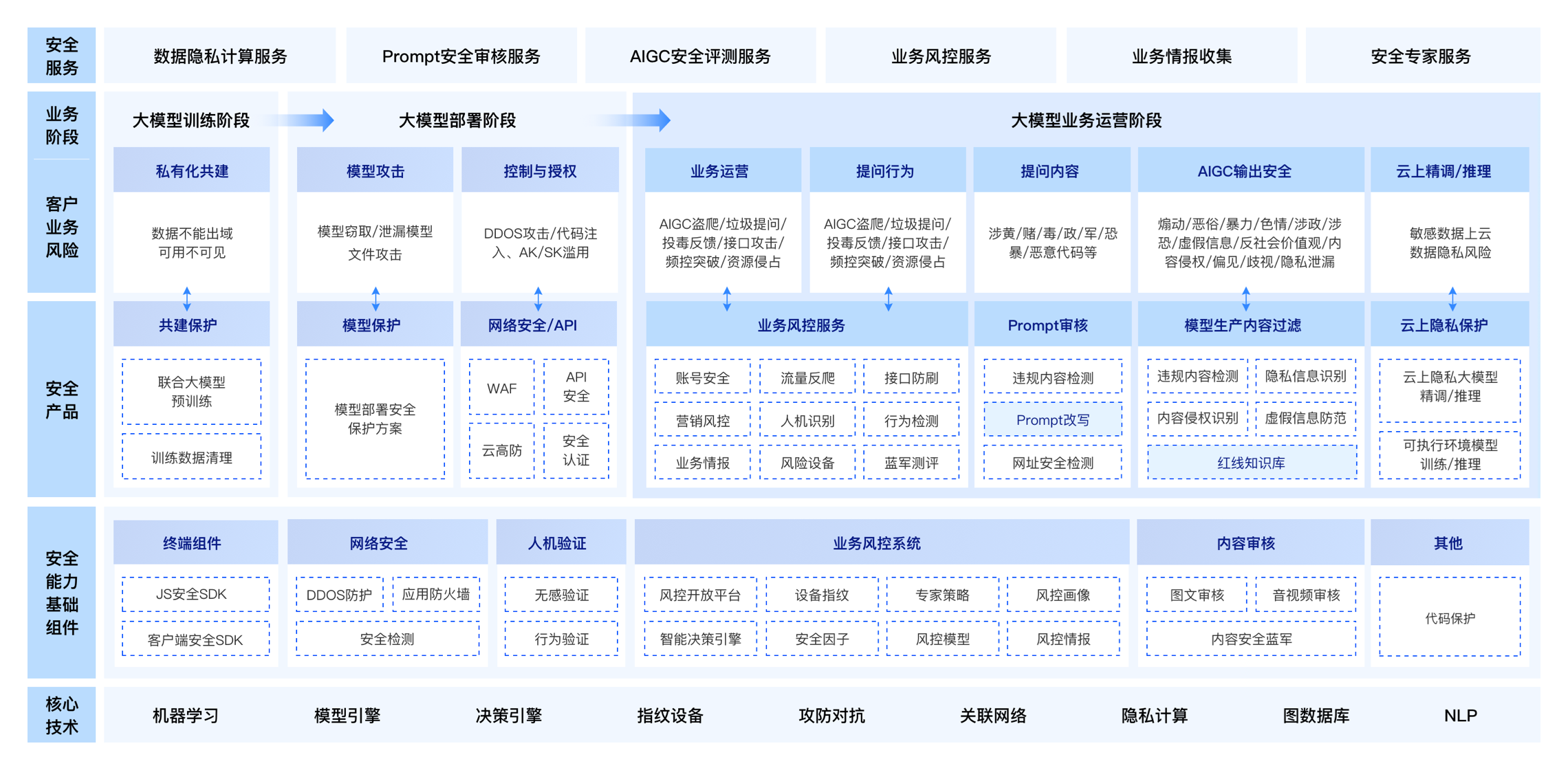
数据安全与隐私保护
联邦学习
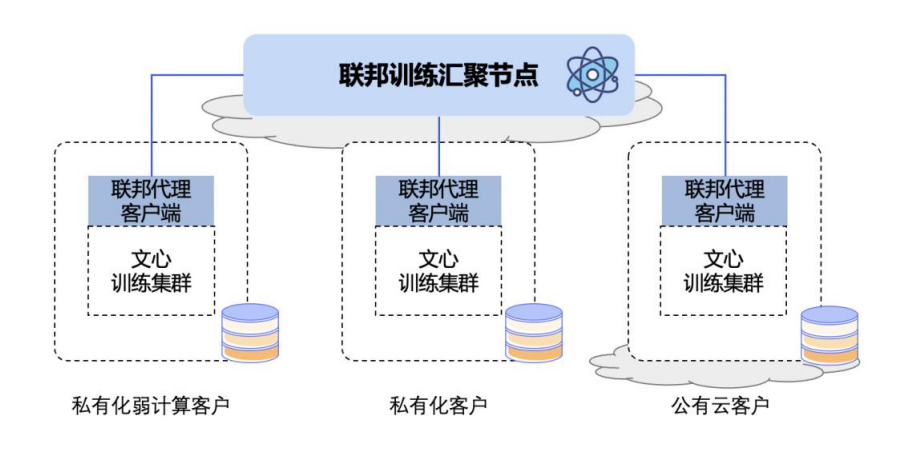
横向联邦大模型解决方案: 采用中心化的CS架构,中心节点为汇聚服务器,用于将不同参与方的结果数据进行汇聚,平衡各参与方的计算节奏,保持和管理最终的合并后的模型。每个参与方,采取弱侵入式的接入方式,部署参与方插件,用于和现有的算力平台进行结合,收集和管理本方的计算集群。
差分隐私
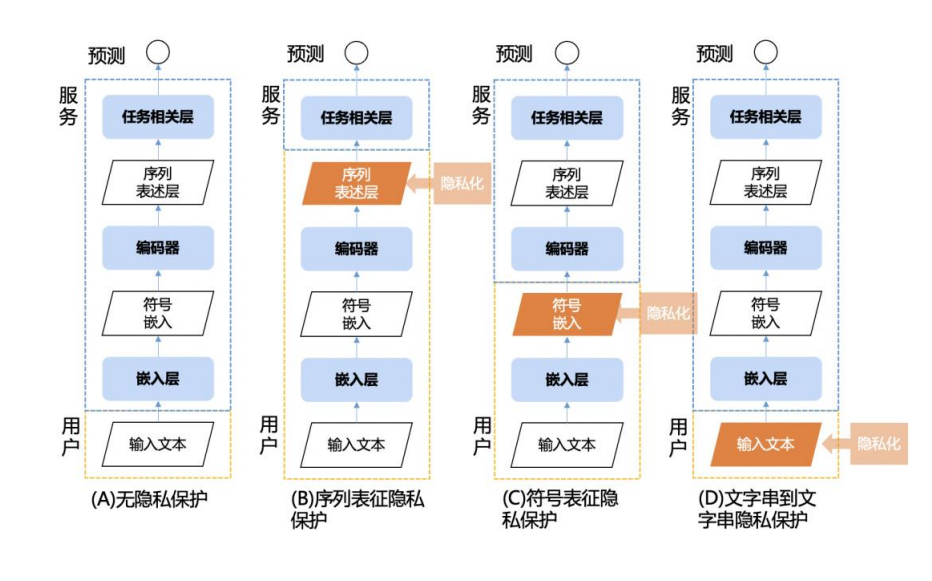
基于差分隐私的软件精调/推理方案: 差分隐私(differentialprivacy)是一个数据保护手段,通过使用随机噪声来确保请求信息的可见结果时,不会因为个体的变化而变化,实现仅分享可以描述数据库的一些统计特征、而不公开具体到个人的信息。这一特性可以被用来保护大模型在精调和推理时与云端服务端交互的用户数据隐私。
同态密码学
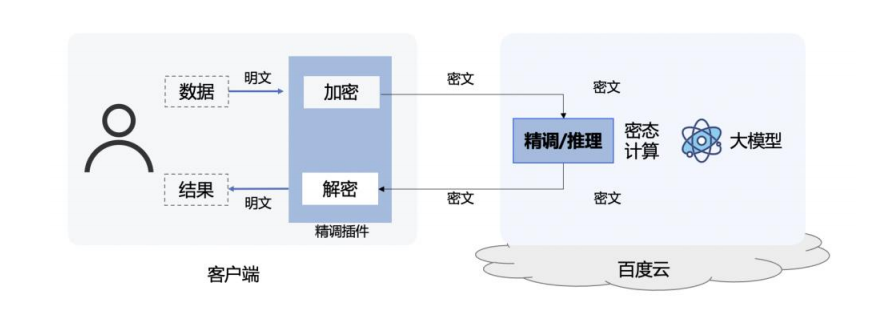
基于同态密码学的软件精调/推理方案: 同态密码学是一项联邦学习的关键技术,提供了在加密状态下对数据进行计算和处理的能力,从而保护数据的隐私和安全。对于大模型的数据保护思路,是通过同态密码学来实现大模型的计算逻辑,从而大模型可以接受密态化的数据输入,整体精调和推理过程完全是密态化的进行,最终的结果也是以密态的形式返回给客户端,整个过程完全是密态化的,所以将此过程完全部署到在云上的服务端。而客户仅需要将本地的隐私数据密态化后上传给服务端,所有计算过程由云端外包完成,但是云端服务,不能获取到计算的内容。对于同态密码学方案,核心是如何通过同态密码学实现大模型的核心计算逻辑,其中主要包括,Embedding,Transformer(Attention)和Header等大模型基础组件结构。由于同态密码学计算复杂性和支持的计算有限,如何合理的利用同态密码学算法能达到可用性和精度的要求,实现精调和推理阶段隐私保护的方案。目前基于同态密码学方面的大模型研究,公开研究主要集中在推理阶段,也有少量的精调方面。根据所采用的同态密码学算法的实现不同,大致可以分成基于全同态密码学FHE实现和基于MPC(Secure Share)实现两大方向。
- 在 FHE 方向,有基于 CKKS 的 THE-X[1],以及基于 BGV 的 Liu, Xuanqi[2], 基于 HGS 的 Primer[3];
- 在 MPC 方向有基于 2PC 的 MPC Former[4] 和 Iron[5], 基于 3PC 的 Puma[6]。
除了底层实现方法的不同之外,对于如何通过同态密码学中有限的计算方式去实现和逼近大模型的基础算子也是目前研究的热点。在降低计算量的同时,如何平衡计算量和网络传输量之间的关系,以达到在实际应用中能最大化的降低耗时,将算法可用性能进一步接近可用,也是研究所追求的目标。我们的同态密码学方案是结合同态密码学和差分隐私等技术,构建的一个对用户数据进行密态计算的方案,并将此技术运用在大模型的精调和推理阶段。在用户客户端,会安装一个客户端插件,此插件主要用于加密用户的隐私数据,形成可以用于密态计算的语料,通过网络连接将加密后的数据发送给服务端。在服务端,将加密的语料直接加载后,通过同态的特性直接用于模型计算。最终的结果也将以密文的形式,返回给客户端。客户端,通过插件将数据解密后得到最终的结果。由于数据全程都是密态形态,所以任何第三方都不可窃取到用户在使用大模型中交互的数据,从而保护了用户数据的隐私。
可信执行缓解
可信执行环境解决方案: TEE能够作为云计算的信任根,保管根密钥,确保TEE外实体无法获取,还可以通过远程证明和负载度量值的结合,使公有云达到私有云的安全等级。对于私有化的场景,TEE可以充分发挥“飞地”的作用,将隐私敏感资产部署在其他实体。
- 在如下大模型使用场景中保护敏感数据资产:
- 在使用第三方大模型服务提供的精调和预测功能时,保护用户输入数据和精调产出模型的隐私
- 在第三方部署大模型服务时,保护模型的隐私
- 通过安全的设计与配置,可以运行复杂的分布式系统
- 处于机密计算状态的处理器操作明文数据,不需要使用差分和同态等密码学算法,具备高性能处理海量数据的能力
- 支持通用的 NLP 算法,模型和计算精度无损失
- 解决方案:
- TDX(TrustedDomianExtension)是英特尔新提出的能够部署硬件隔离的虚拟机(可信域,trusteddomain,TD)的技术框架
- SEV(Secure Encrypted Virtualization)是 AMD 提出的机密虚拟机方案, 其推出时间较 TDX 早,因此软件生态较好,upstream linux kernel, openstack,kubevirt 和 libvirt 等虚拟化相关生态支持较好;
- CSV(ChineseSecureVirtualization)是海光根据AMDSEV国产化的解决方案,使用国密算法,信任根全部国产化。
百度提供的可信执行环境解决方案( Mesa TEE )是基于硬件TEE的大模型机密计算方案,支持在 Intel SGX,Intel TDX,AMD SEV-SNP 和海光 CSV 等多种硬件TEE内进行大模型训练和推理。通过以 PCIe 穿透(pass through)的方式访问 Nvidia H 系列 GPU 和海光集成 DCU 等具备机密计算能力的外部加速设备,Mesa TEE 能够获得与非机密计算相当的大模型计算性能,拥有良好的模型效率和用户体验。 Mesa TEE 将传统虚拟机安全与TEE相结合,将可信启动过程记录到远程认证的度量值中,保证启动过程的安全,提高远程认证的真实性。机密虚拟机中运行的容器启动前,其数字签名会被校验,确保程序来源的合法性。隐私数据以透明加解密的方式落盘,保护数据隐私和安全的同时,提高应用的兼容性;非秘密的程序,通过建立哈希树(Hash tree)的方式,保证其完整性的同时,兼顾访问性能。机密虚拟机之间使用基于远程认证的透明加解密技术,确保通信过程中的数据隐私安全。 Mesa TEE 深耕大模型使用场景,支持分布式训练、精调和推理,通过基于身份的访问控制,具备多租户数据及模型隔离管理和保护,多方数据训练和推理等数据融合功能。可信执行环境是云计算中不可或缺的一部分,它从硬件层面解决了软件根本的信任问题,是云计算的“根”。机密计算是大趋势,英特尔、AMD 和英伟达等硬件提供商均提供了机密计算硬件解决方案。微软、亚马逊云、谷歌云和阿里云等均提供机密计算的设备和解决方案。百度、蚂蚁金服和字节跳动等均在使用机密计算为业务提供隐私及安全能力。
安全沙箱
基于安全沙箱的解决方案: 安全沙箱技术是一种通过构建隔离的可供调试、运行的安全环境,来分离模型、数据使用权和所有权的技术,同时提供模型精调计算所需的算力管理和通信等功能,保证模型拥有方的预训练模型在不出其定义的私有边界的前提下,数据拥有方可以完成模型精调任务。安全沙箱通过界面隔离、环境隔离、网络隔离、执行隔离、数据隔离五大隔离技术达到模型和数据的可用不可见。
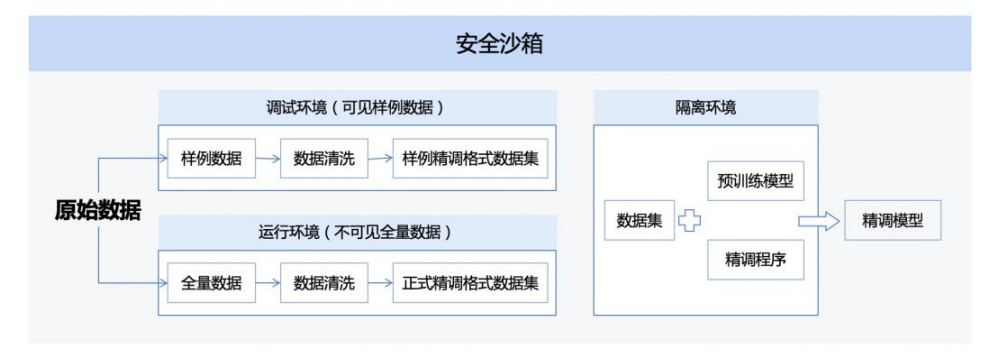
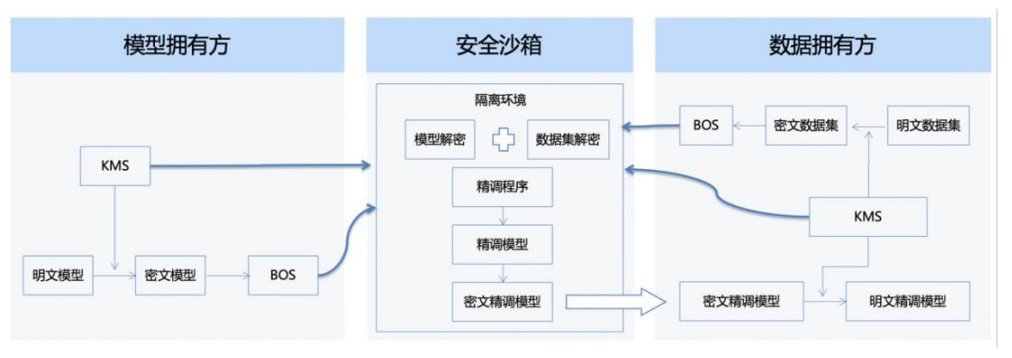
结合KMS作为密钥管理服务,对进入到沙箱的预训练模型和精调数据集进行加密,在沙箱的隔离环境内进行模型精调时,对其使用对应的KMS进行解密,完成精调时产出密文精调模型,数据拥有方使用自己的KMS对其解密为明文精调模型。
在大模型推理领域,安全沙箱可提供在线推理服务用于一键部署精调后的大模型,对外提供在线API推理服务。在线推理服务提供精调模型部署、API网关、负载均衡、安全访问认证、动态脱敏等功能。模型支持多实例部署方式和实例动态扩缩容,提供API网关能力,对后端的实例进行负载均衡,以保证在线推理服务的高可用性;对请求进行安全访问认证,确保请求来源的合法性;对推理服务返回的内容实时动态脱敏,确保推理结果不包含敏感数据。
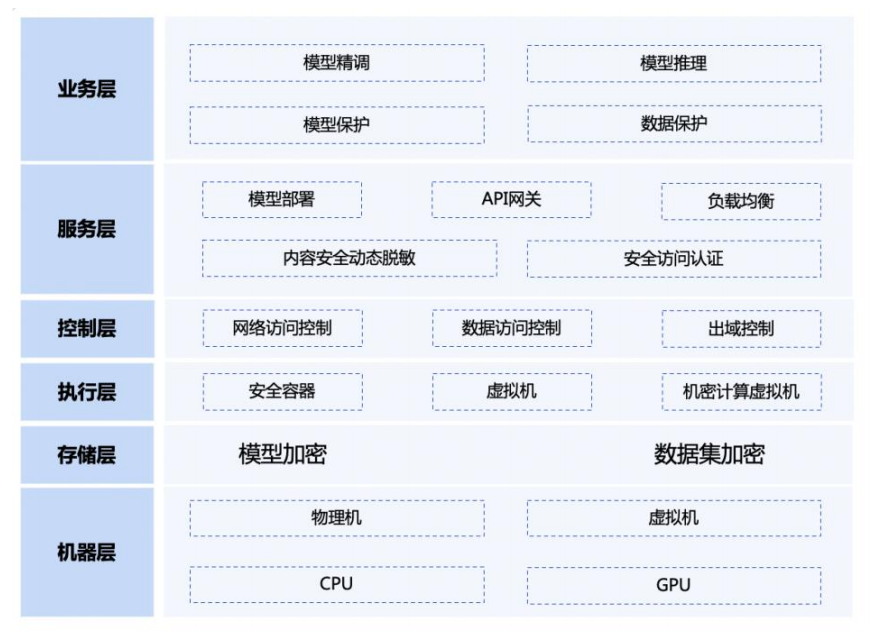
模型保护方案
- 语料数据管理:面对多渠道收集珍贵语料数据,如何实现高效的数据管理,防范模型原始语料数据泄漏,提高语料数据加工效率
- 模型资产保护:大模型文件是企业核心数字资产,如何防范大模型文件在训练、推理、微调等环节的模型文件泄漏风险
大模型语料数据安全管理与大模型资产全流程保护:
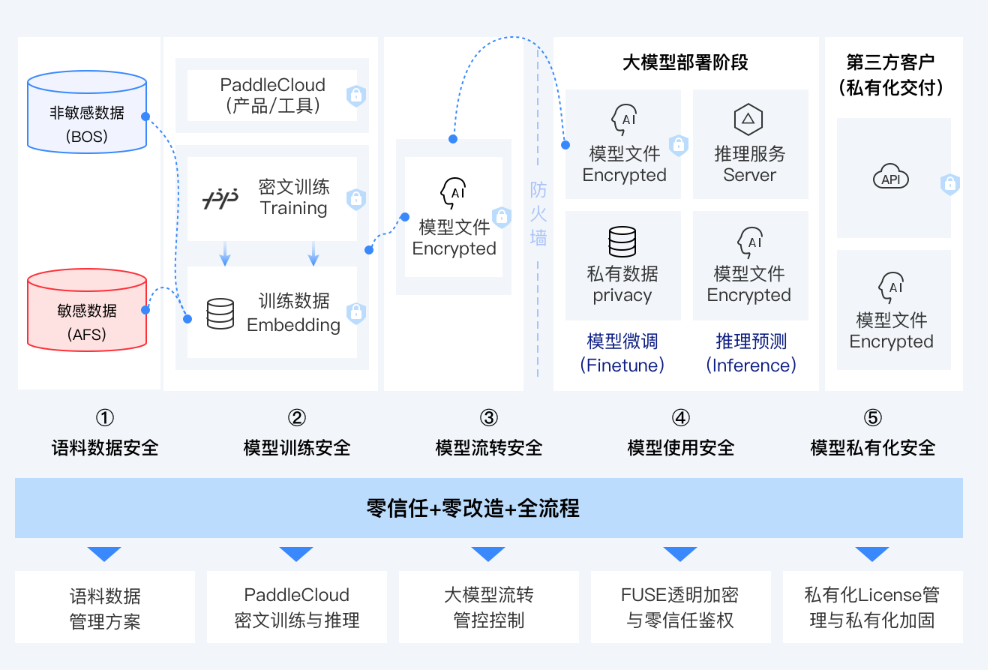
大模型语料数据安全管理
元数据管理、分类分级、流转审批、数据鉴权、加密保护、行为审计、数据脱敏、访问控制、数据备份与恢复、敏感信息检测:引入敏感信息检测技术
大模型资产全流程保护
- 模型训练安全:在模型训练过程中,采用隔离环境,确保模型训练的数据和代码不受未授权访问。引入训练数据的加密和隐私保护措施,防止敏感信息泄露。
- 模型流转安全:设计模型流转的安全机制,确保模型在传递过程中不被篡改或恶意替换。可以使用数字签名等方式验证模型的完整性。
- 模型推理安全:在模型推理阶段,引入安全沙箱和权限控制,确保模型运行在受控环境中,避免恶意代码注入和攻击。
- 模型微调安全:在模型微调过程中,采用差分隐私等技术,确保微调数据的隐私性和保密性。
- 私有化部署安全:对于私有化部署,强调数据在企业内部的隔离和安全性。建立私有化部署的权限控制和监控机制。
- 模型演化与更新:引入安全审查流程,确保模型的更新和演化过程中不引入漏洞或不安全的元素。
- 模型审计与跟踪:对模型的运行情况进行审计和跟踪,及时发现异常行为和风险。
- 安全修复与更新:在发现模型存在漏洞或安全问题时,能够及时进行修复和更新,防止潜在的威胁扩散。
AIGC 内容合规
复杂多样的内容、监管法规不断变化、技术与人工判定的平衡、多语言与文化差异、隐蔽性的风险、合规规则的标准化、时间敏感性、平衡安全与隐私、技术局限性
安全防线:
- 预训练数据过滤方案:百度使用安全内容业务中积累的海量有标注数据,基于ERNIE模型的领先内容理解能力,构建了通用的内容安全召回模型,能够高效检出训练语料中的有害内容;同时通过业务风控富集的敏感词词库过滤数据中的脏话和不适出现词汇,提供召回模型之外的快速更新能力。除了过滤有害内容,预训练数据过滤方案也能够删除可能包含个人身份信息、隐私敏感信息的内容,用以严格保护用户的隐私。
- 内容干预系统:大模型的内容干预是指通过人工审核、过滤技术或其他方式,干预模型输入的内容,以确保其符合特定的标准、规范和价值观。这种干预可以帮助减少有害、不准确或不恰当的内容,并提高生成内容的质量和安全性。百度可提供完整的实时内容干预系统,内置红线必答和Query干预功能。红线必答能够很好回答常见的红线问题,确保回复内容高度安全合规,维护社会主义核心价值观;Query干预支持用户配置相应规则,通过对包含特定敏感词的快速匹配,将不安全Query引导至更加合适的处理流程中(例如标准回复模版),减少大模型在该Query输入下产生有害内容或者不正确数据。
- 安全分类算子:大模型输入的安全分类是指将用户输入内容进行分类,以判断其安全性和合适性。这种分类能够帮助防止不良内容的生成,保护用户免受有害、不准确或不适当的内容影响。通过有效的输入内容安全过滤,能够极大程度地减少大模型生成不安全或者负面的回复内容,同时结合高精准的分类标签,通过改写技术可以构造出更适于大模型输出合规回复的提示词模版
- 大模型微调安全策略:在大模型预训练完成后,为了提高其生成内容的安全性,可以进行安全微调。基于已经通过安全审核的、符合安全标准的指令数据对大模型进行微调,以指导其生成更合适、不含有害内容的回复内容。微调后的大模型可以进一步通过RLHF方式提升大模型对安全回复内容的偏好程度,引导鼓励大模型生成更加高质量的安全内容。
- 输出内容安全过滤大模型输出内容安全过滤是指对大模型生成的文本内容进行检测和筛选,以识别并过滤掉有害、不准确、不适当或不合规的回复内容,这有助于确保大模型生成内容的质量和安全性。百度使用业务风控中积累的高危词典对输出内容进行安全过滤,在滤除有害敏感词后通过语义改写将安全回复内容作为最终的大模型输出,确保输出环节安全合规。
其他:
- Prompt 审核与改写
- 红线知识库
- AIGC 多模态内容审核
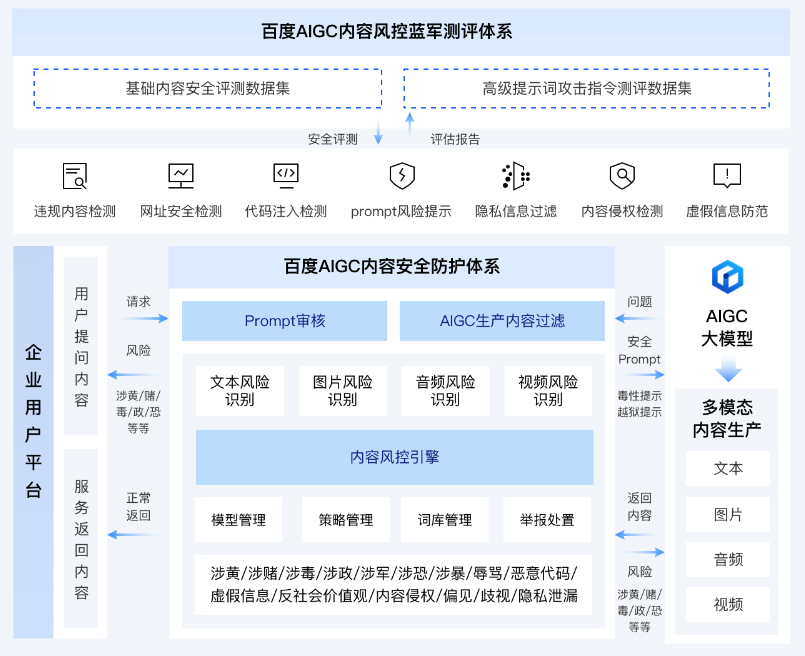
大模型业务运营与安全风控
在大模型业务运营的环节,依托百度安全智能风控能力,可以建立大模型业务运营的安全风控防护体系,可以在大模型前置云运营阶段(如:用户注册、登录、权益申请等环节)、以及大模型交互环节(如:用户提问环节、回答内容反馈等环节),结合用户行为、终端环境、网络特征等信息建立有效的安全防护体系,针对异常请求做实时风险检测,保障大模型处于一个安全、可靠的运营状态。大模型在交互场景中的业务运营中,面临着多重安全威胁和风险,本方案结合当前场景,依托百度安全昊天镜智能风控服务,构建了包含账号安全、接口防刷、人机识别、AIGC盗爬识别、设备风控以及风险情报等方面的能力
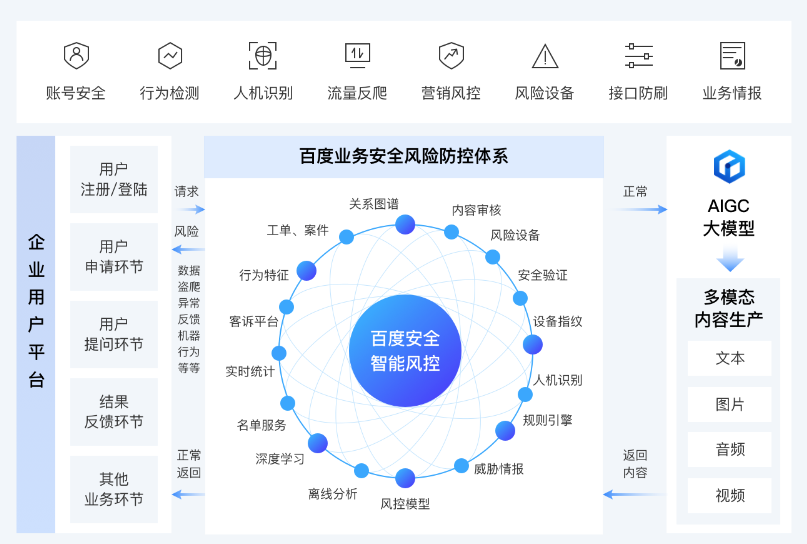
参考
- pdf, Chen, Tianyu, et al THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption. arXiv preprint arXiv:2206.00216(2022) ↩
- pdf, Liu, Xuanqi, et al LLMs Can Understand Encrypted Prompt: Towards Privacy-Computing Friendly Transformers. arXiv preprint arXiv:2305.18396(2023) ↩
- pdf, Mengxin, Zheng, et al Primer: Fast Private Transformer Inference on Encrypted Data. Design Automation Conference. 2023 ↩
- pdf, Li, Dacheng, et al MPCFormer: fast, performant and private Transformer inference with MPC. arXiv preprint arXiv:2211.01452(2022) ↩
- github, Hao, Meng, et al Iron: Private Inference on Transformers. Advances in Neural Information Processing Systems. 2022 ↩
- pdf, PUMA: Secure Inference of LLaMA-7B in Five Minutes ↩