GPU 多卡互联
多卡如何互联通信,以 NV / AMD 实现为例。

参考:
- How GPU-GPU Connectivity Works With NVLink
- 使用第三代 NVIDIA NVSwitch 升级多 GPU 互连
- NVIDIA GB200 NVL72 提供万亿参数 LLM 训练和实时推理
- NVLink 和 NVLink Switch
- nvidia nvlink 互联与 nvswitch 介绍
- NVIDIA NVLink和NVSwitch介绍
- 【工业前沿】NVIDIA NVLink-C2C
单卡
指一张 GPU 连接到 CPU 主板上:
C2C(Chip-to-Chip)通信是指同一块GPU芯片内的不同计算单元(如SM,Streaming Multiprocessor)之间的数据传输。这种通信通常在GPU内部的高速缓存或共享内存中进行。
单节点多卡
P2P(Peer-to-Peer)通信是指GPU之间进行数据传输。NVIDIA的P2P通信可以通过PCIe或NVLink实现。NVLink是NVIDIA开发的高带宽GPU互连接口,旨在解决PCIe带宽和延迟瓶颈。NVLink提供比PCIe更高的带宽和更低的延迟,使得GPU之间的数据传输更加高效。NVLink 2.0和3.0版本进一步提升了带宽和效率。NVSwitch是一种高性能互连交换机,允许多个GPU之间实现全互连(All-to-All)的高带宽通信。它类似于传统网络中的交换机,但专门设计用于GPU之间的数据传输。NVSwitch支持多达16个GPU之间的全带宽互连,非常适合大型深度学习和高性能计算集群。
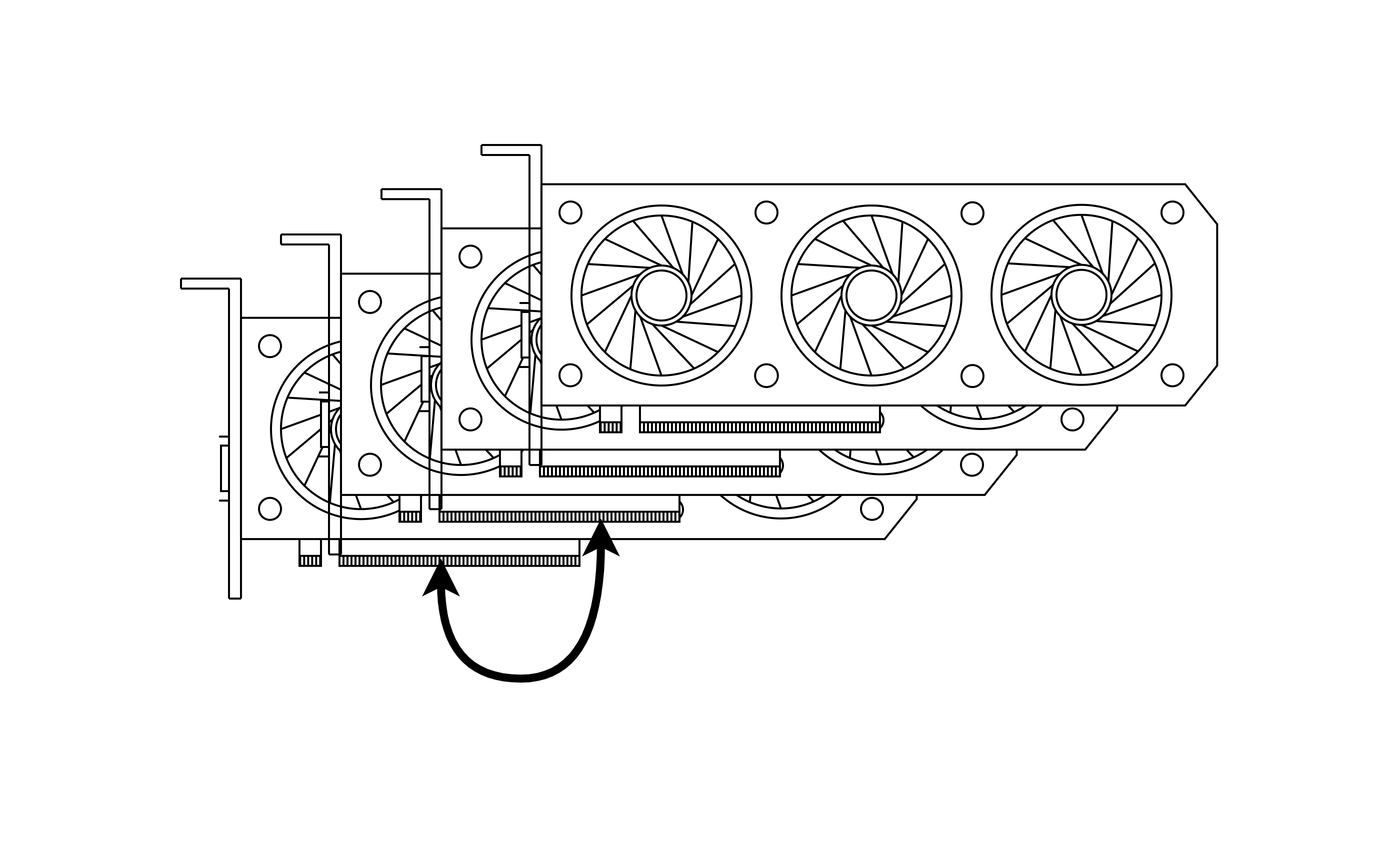
通过 PCIe 实现互联:
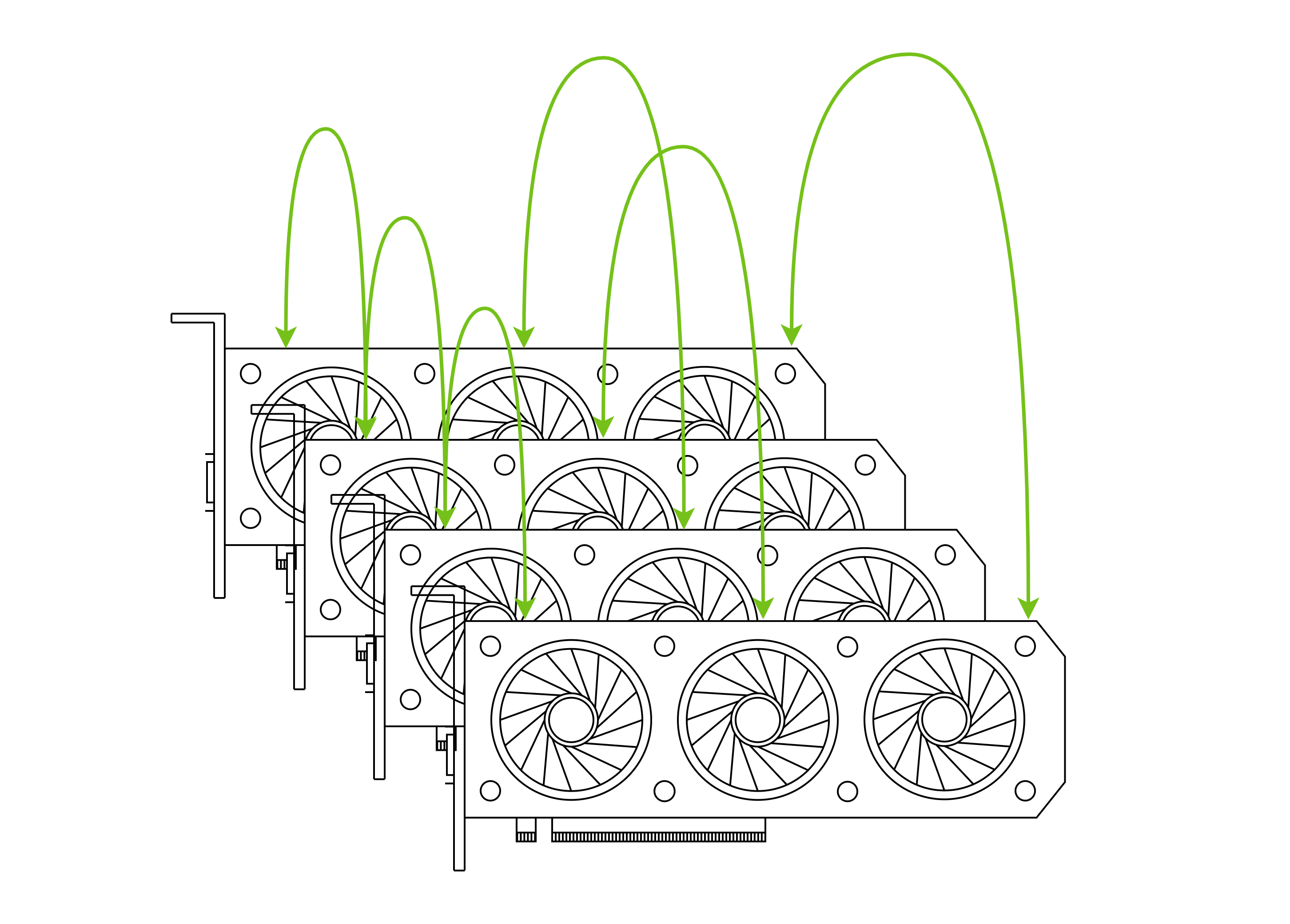
通过 NvLink / XHCL / AMD XGMI 实现互联:
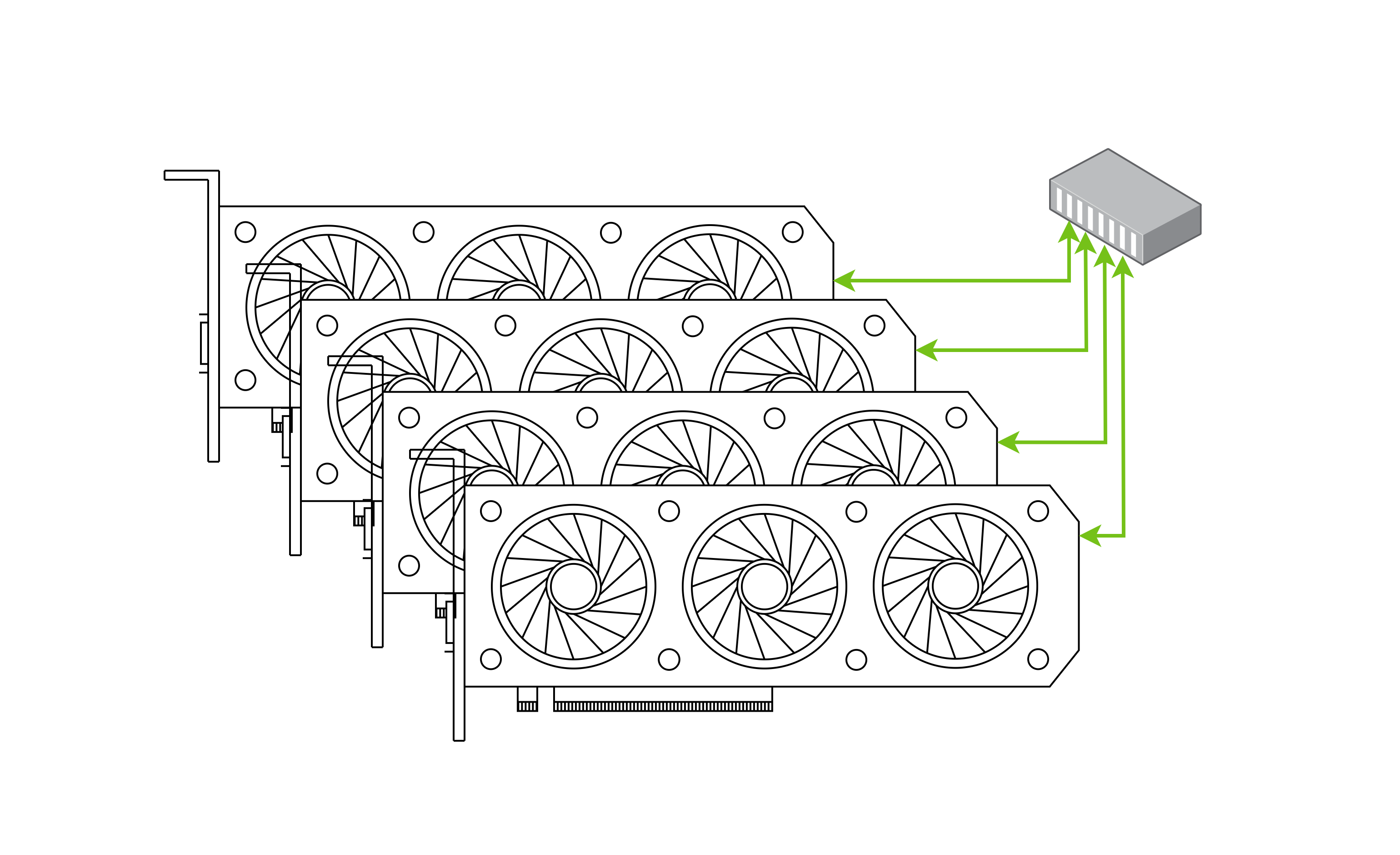
通过 NvSwitch / HySwitch 实现互联:
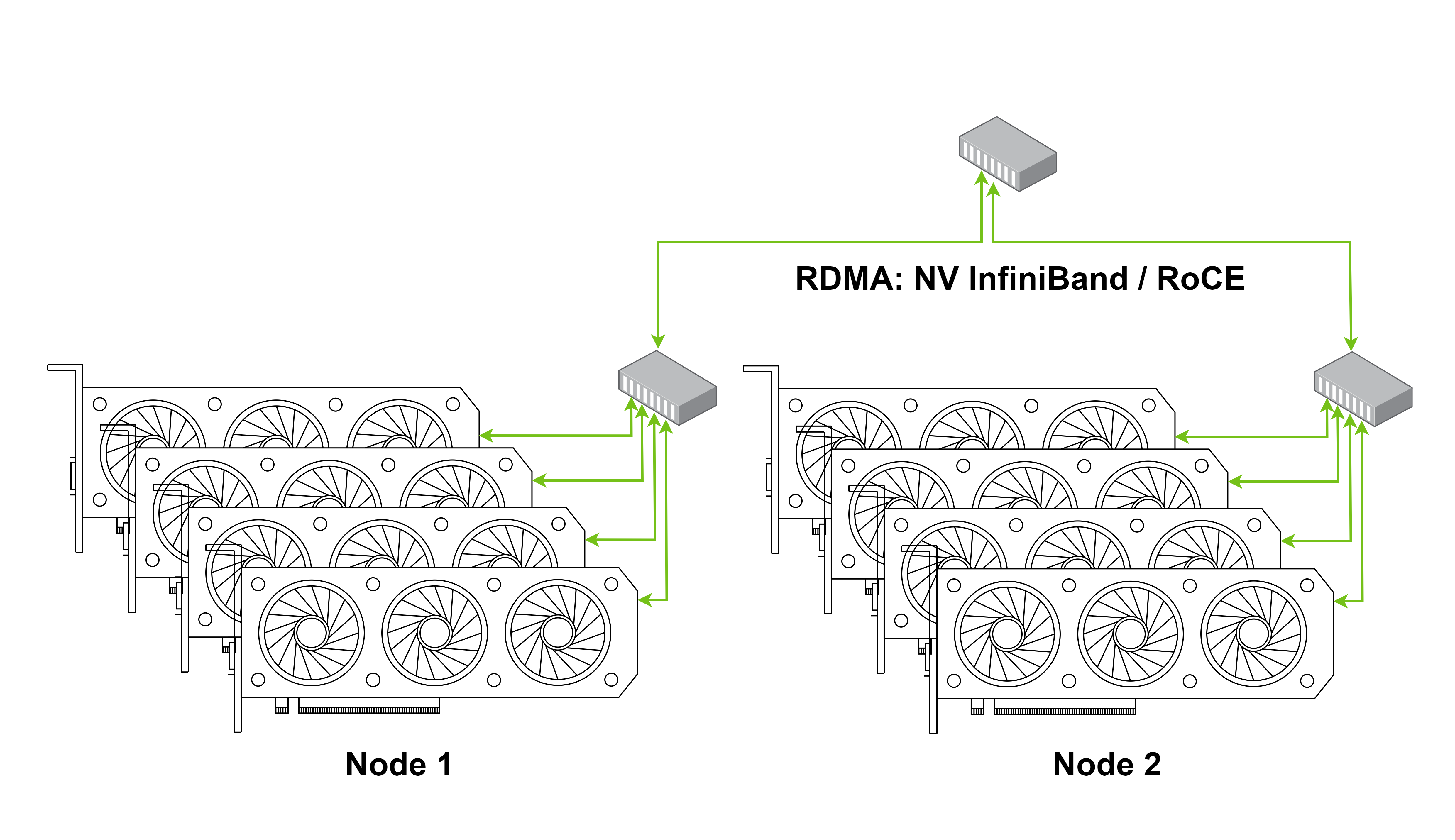
多节点
指通过 RDMA 实现节点间通信,借助 Infiniband 或者 RoCE 技术。RoCE 是在传统以太网基础上实现的 RDMA 技术。它允许在以太网环境中实施 RDMA,这意味着可以在不需要专门硬件(如 InfiniBand)的情况下,利用现有的以太网基础设施实现 RDMA 的优势。
NVLink与NVSwitch的区别
- NVLink:用于GPU之间的点对点(P2P)连接,提供高带宽、低延迟的互连。主要用于多GPU系统中的直接通信。
- NVSwitch:提供多GPU之间的全互连能力,支持更多GPU并行通信。主要用于大型GPU集群,提供更高的可扩展性和灵活性。
NVLink 与 PCIe 的区别
- 带宽:NVLink提供的带宽远高于PCIe。例如,NVLink 2.0的单链路带宽可达25 GB/s,而PCIe 4.0的单通道带宽约为16 GB/s。
- 延迟:NVLink的延迟比PCIe低,适合高性能计算和深度学习等对延迟敏感的应用。
- 拓扑结构:NVLink可以实现点对点直接连接,而PCIe通常需要通过主机桥接。