LLM 算法分析
一文了解 GPT 推理原理。
AI演化趋势
AI模型规模越来越庞大,越来越简洁,人工参与度要求越来越低,和硬件发展相匹配。


- 2020s大语言模型兴起, 得益于GPU与AI相互促进发展
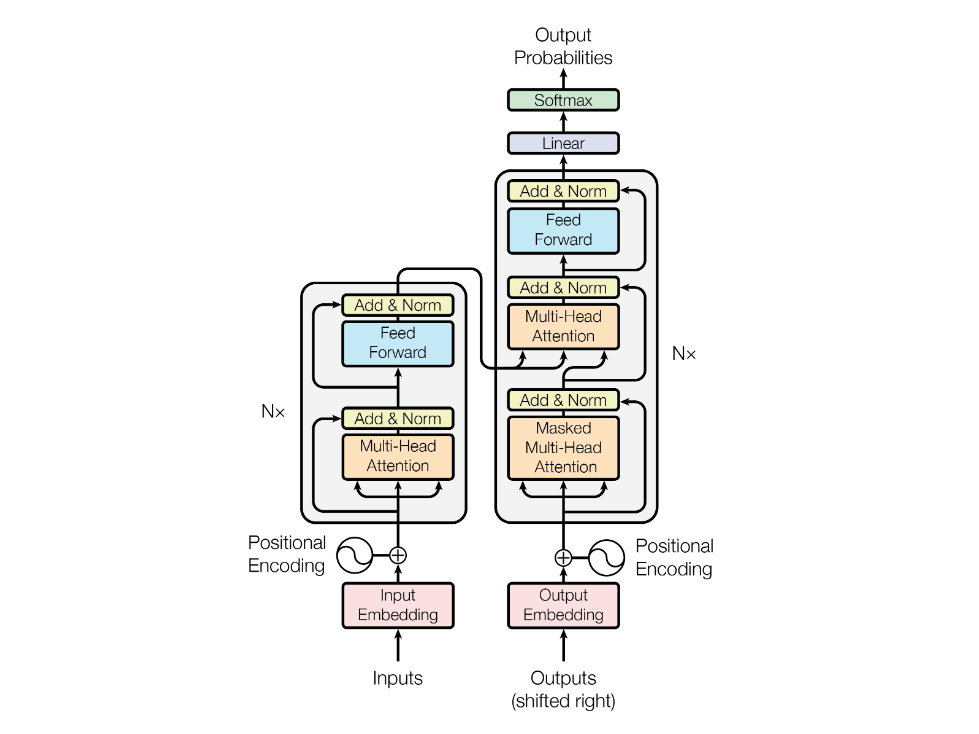
- 2017 Attention is all you need
- 2018 GPT/BERT
- 2022 chatGPT
- 矩阵乘,残差网络,LayerNormalization,Attention
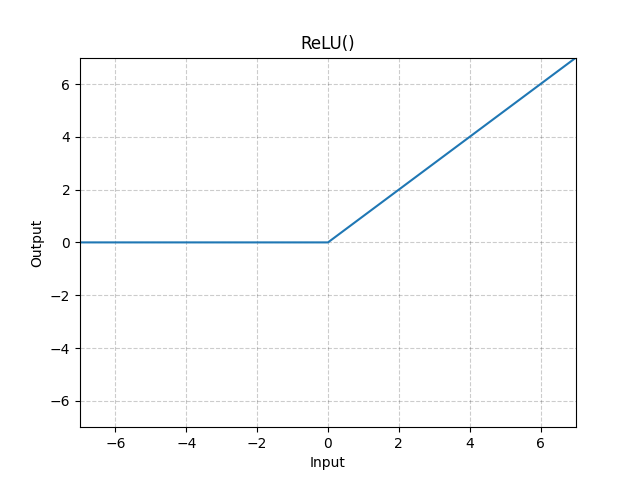
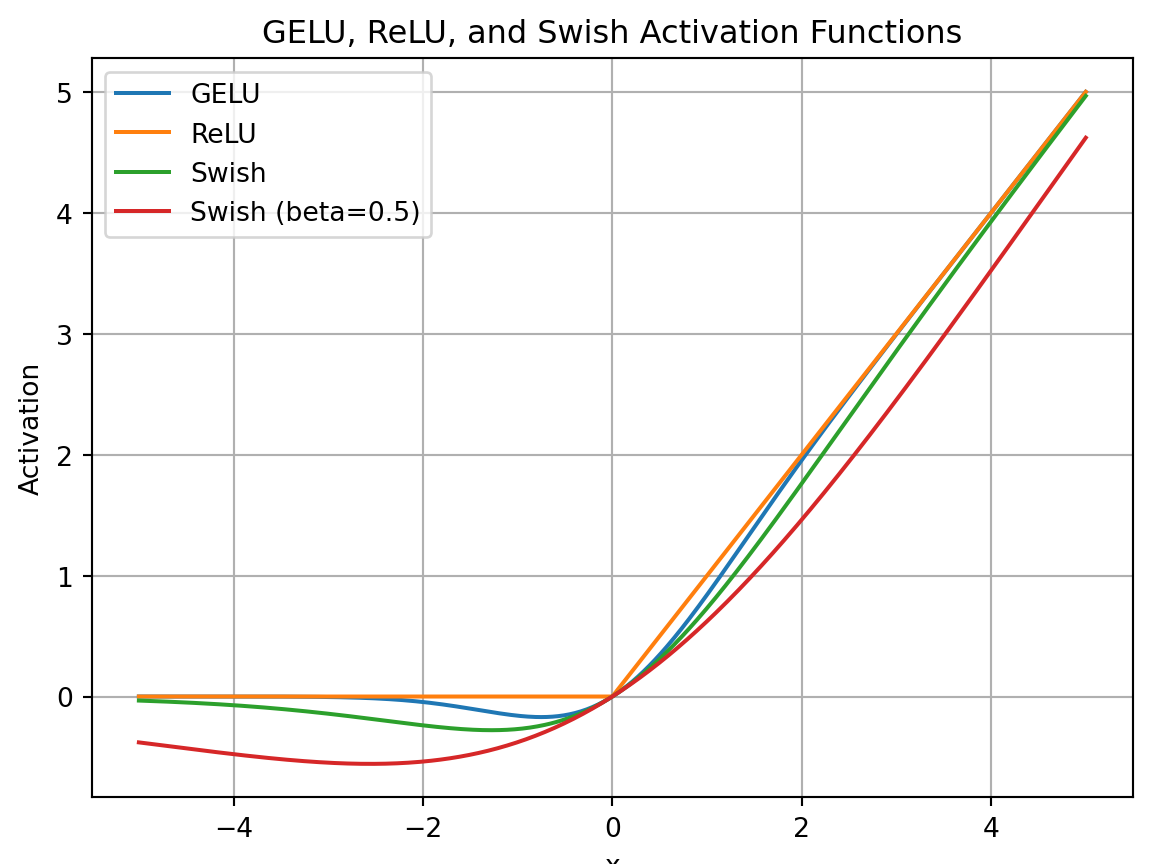
- Elementwise 非线性激活函数
- 基于 Transformer 结构
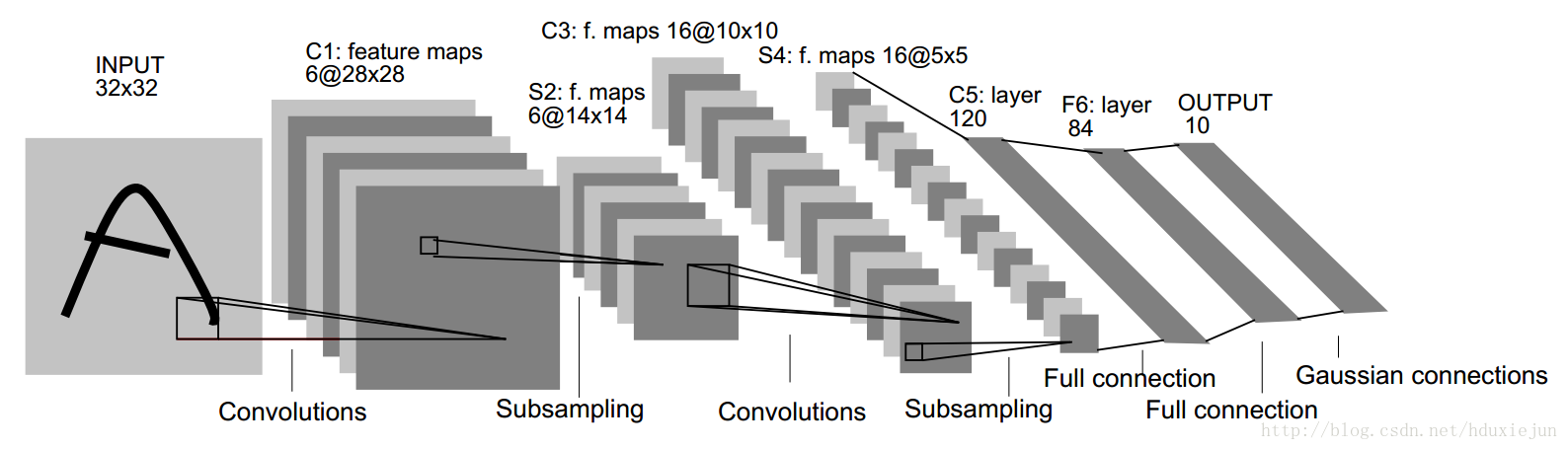
神经网络简介
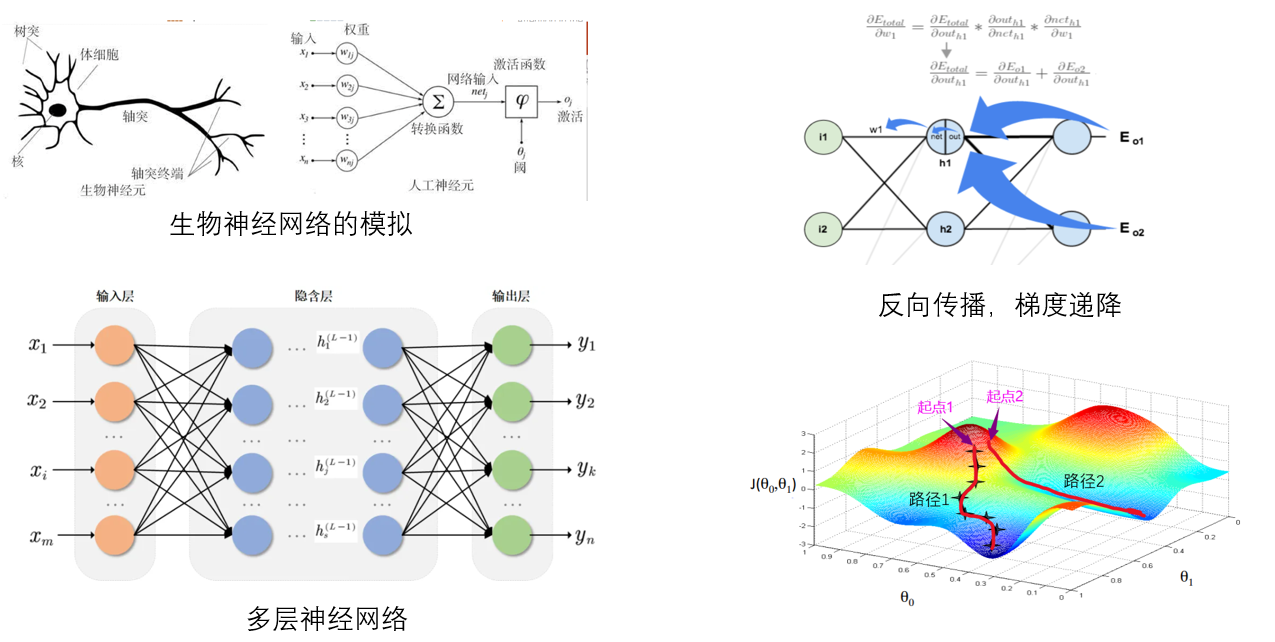
残差神经网络
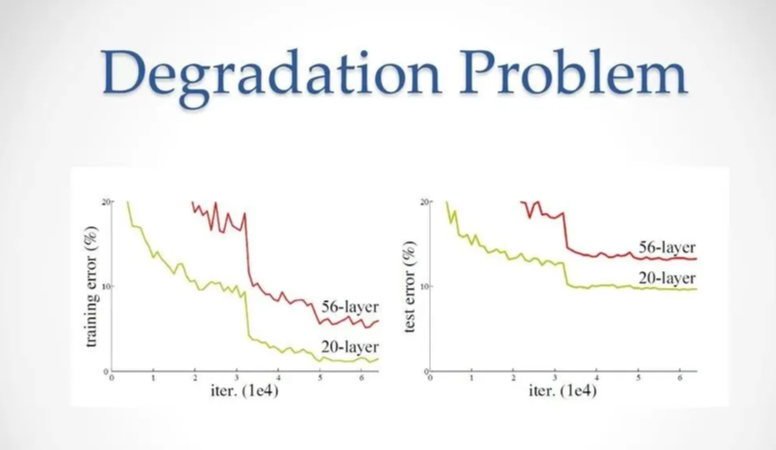
解决退化问题
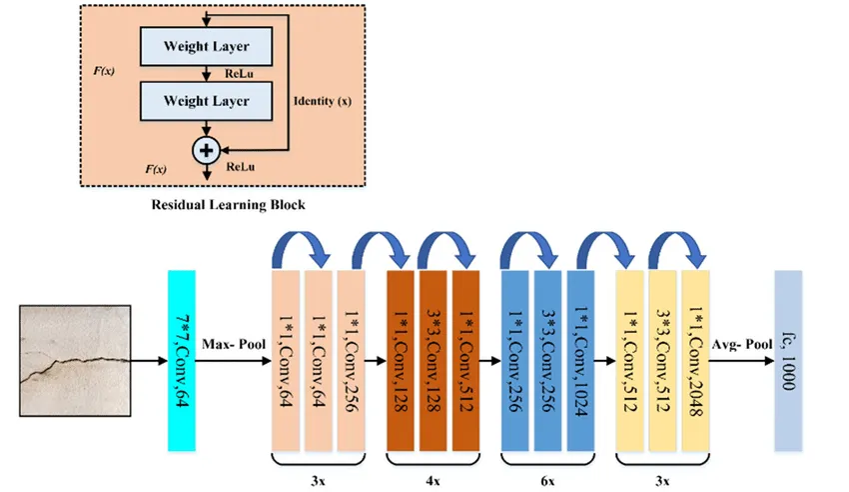
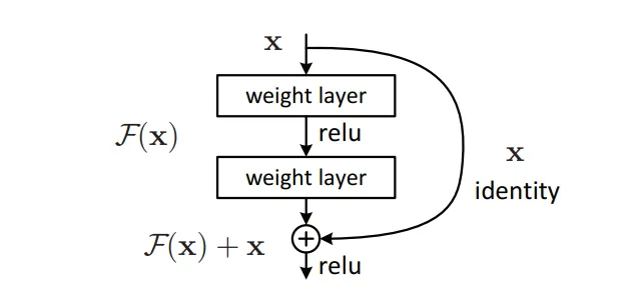
计算残差:
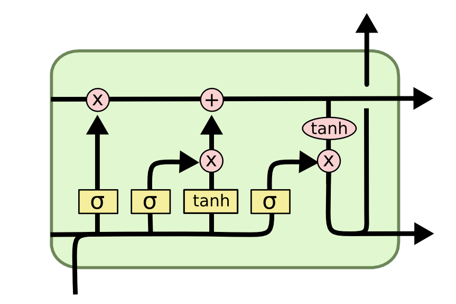
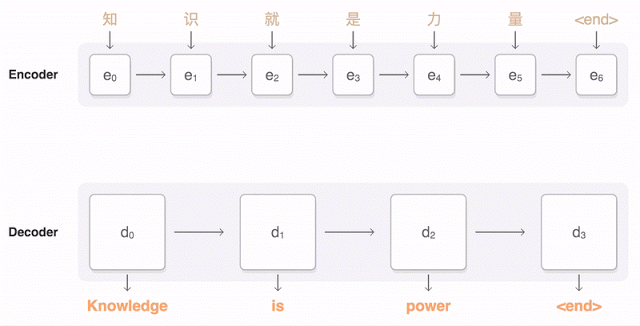
编码器与解码器
Seq2Seq : RNN, LSTM, Transformer
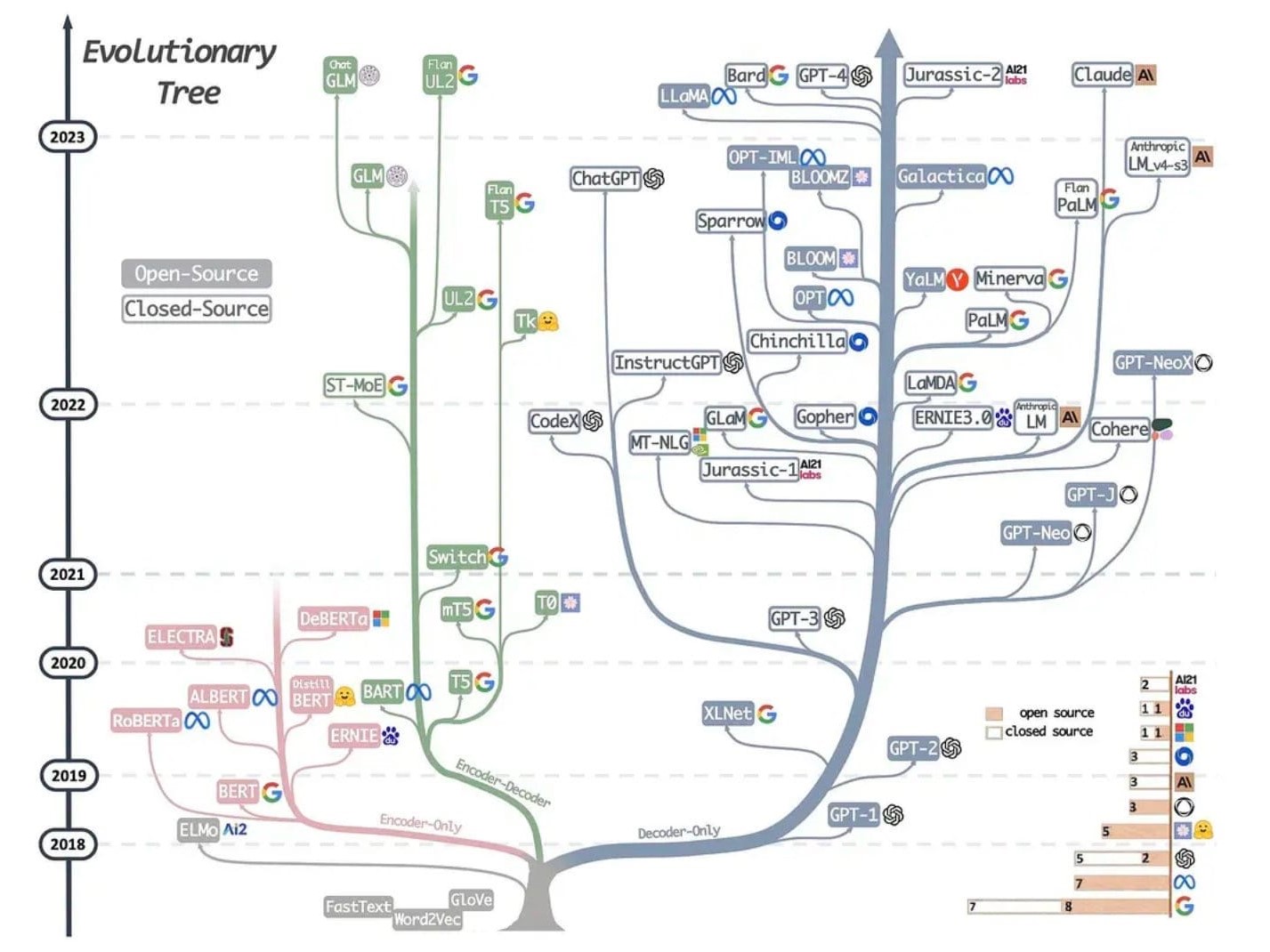
LLM 分类
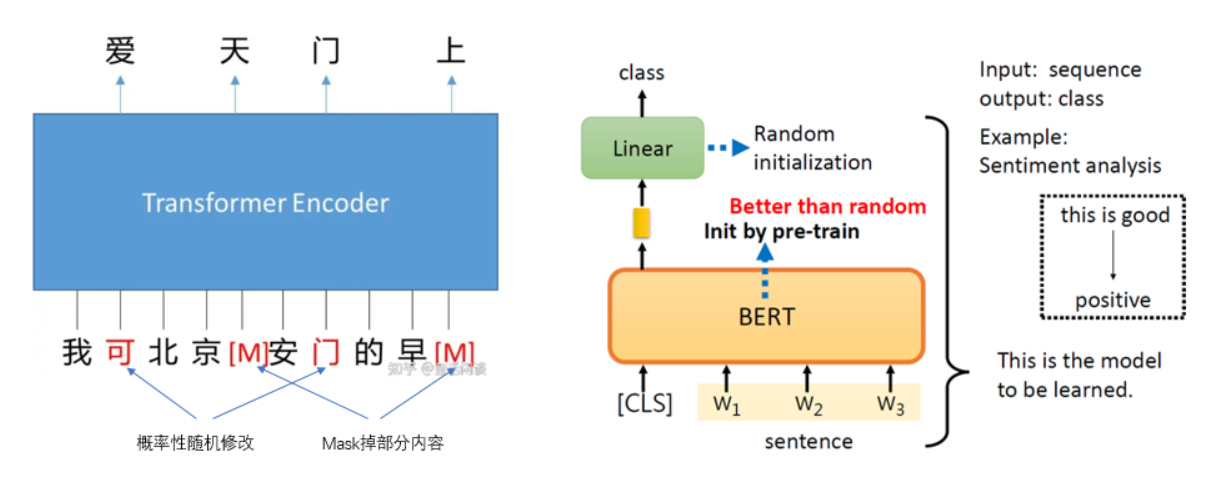
Encoder & Decoder功能对比
- Masked Language Model (BERT Training)
- Next Token Generation (GPT):我爱北京天安,计算出下一个字 “门”
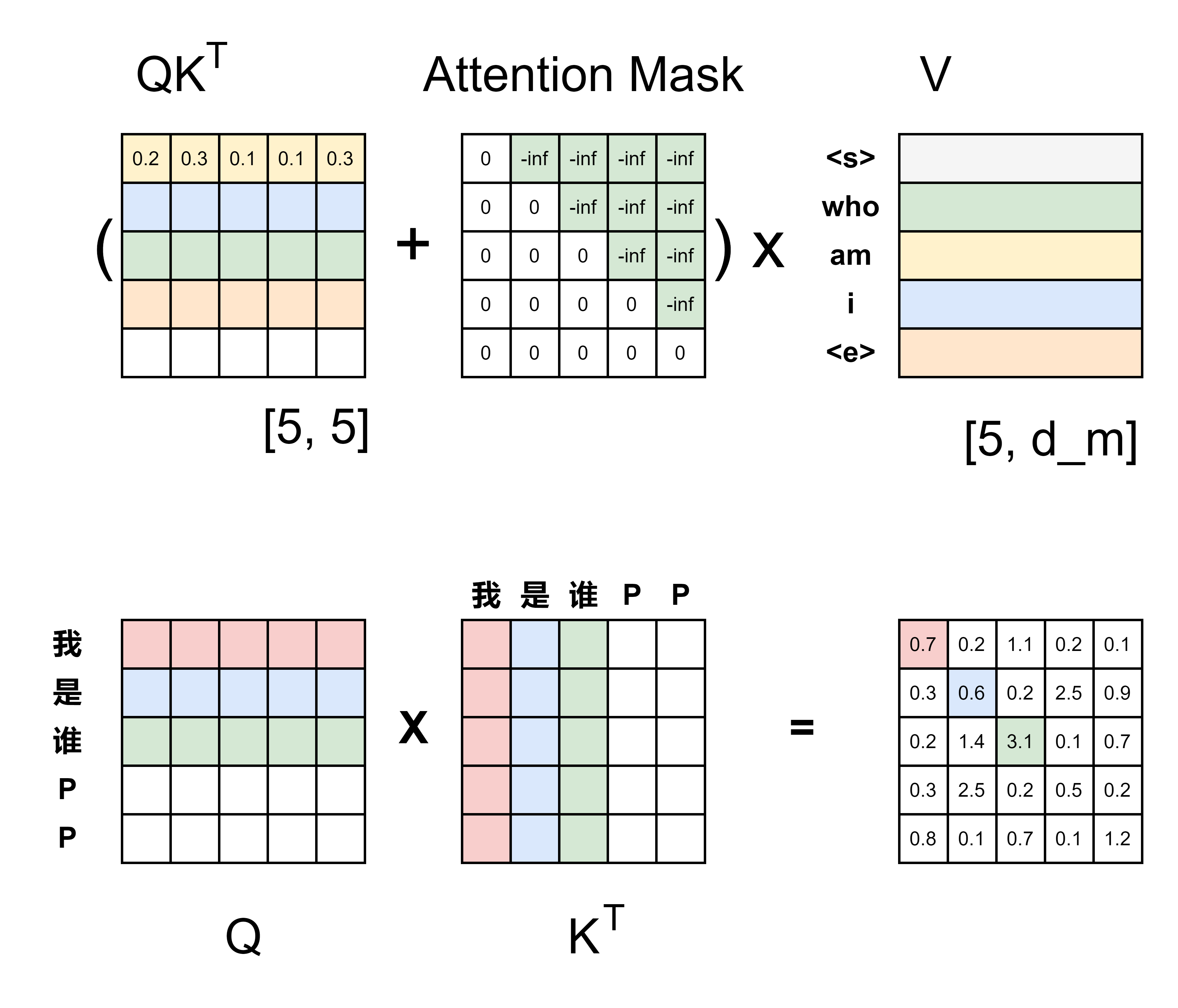
Attention 介绍
Attention is all you need!
$$
Attention=Softmax(QK^𝑇)𝑉
$$
归一化,权重系数,突出主要因子
$$
Softmax([𝑣1,𝑣2,𝑣3,…,𝑣𝑛])= \frac{[𝑒^{𝑣1}, 𝑒^{𝑣2}, 𝑒^{𝑣3}, …, 𝑒^{𝑣3}]}{𝑒^{𝑣1} + 𝑒^{𝑣2} + 𝑒^{𝑣3} + … + 𝑒^{𝑣𝑛}}
$$
例如:
$$
Softmax([1,−∞,0,2,5])=[0.01704,0,0.00627,0.04632,0.93037]
$$
Decode-only: 每个 Token 都只依赖历史信息而不依赖未来信息。可以通过使用 KV-cache 极大降低generation过程计算量 – Memory Bound
更多:
- 一文讲透预训练模型的改进训练算法 ,轻松达到State of the Art
- BERT模型的详细介绍
- transformer 中: self-attention 部分是否需要进行 mask?
- 学习笔记:基于Transformer的时间序列预测模型
- Transformers源码学习
- 从self-attention到transformer的超详细的算法解析和主流论文研究分享
- This post is all you need(①多头注意力机制原理)
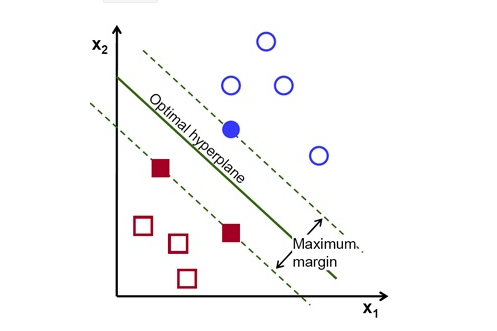
非线性激活函数

目标,通过非线性变换把的分界线拉直;更高的维度提供了更多的弯曲变换机会。
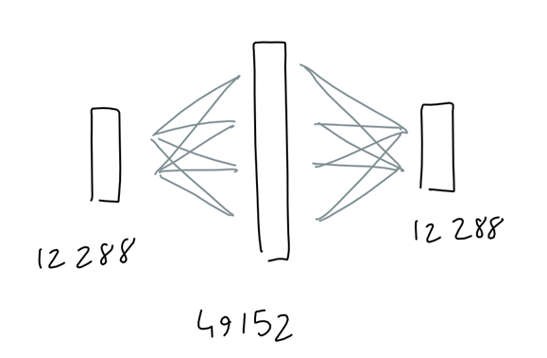
Transformer中 Feedforwad 部件,Elementwise 激活函数(Tensor中每个元素独立进行相同的非线性运算)