2024 清华 LLM 公开课 - 笔记
深入介绍人工智能(AI),重点介绍大型语言模型(LLM)的前沿发展,深入了解人工智能领域的历史、关键技术和现有挑战。
目录
介绍
课程将讨论人工智能的未来趋势,帮助学生参与由人工智能驱动的技术变革浪潮。
笔记包含下述标签:
讲义引用的观点
课程笔记
1 大语言模型导论
人工智能历史
人工智能已经成为我们日常生活中必不可少的组成部分,极大地提高了我们的日常活动和工作效率: 人脸识别、自动驾驶、语音识别与合成、推荐系统、信息检索。人工智能促进了知识的有效获取和新思想的探索,在我们社会的进步中发挥着至关重要的作用。
人工智能本质上是每个人的生产力倍增器。它将使我们最好的科学家变得更好,使科学加快很多。人工智能将帮助我们在一个大脑中储存更多的知识,并发现新的联系,新的想法 —— 山姆 · 奥特曼
我们致力于解决智能问题,推动科学发展,造福人类 —— Demis Hassabis
人工智能是人类正在研究的最重要的事情之一,它比电或火更深刻 —— Sundar Pichai
定义
- 目前,人工智能的定义缺乏共识
- 从广义上讲,人工智能是机器,特别是计算机系统所表现出的智能。它是计算机科学的一个研究领域,开发和研究方法和软件,使机器能够感知环境,并利用学习和智能采取行动,最大限度地提高实现既定目标的机会
长期以来,人类一直对人工智能的概念着迷。根据希腊神话的记载,塔洛斯是一个巨大的青铜自动机,用来保护克里特岛上的欧罗巴免受海盗和入侵者的侵害。这是西方文学中最早对机器人的描述之一。据《列子 · 唐文》(列⼦ · 汤问)记载,工匠严石(偃师)向穆王(周穆王)展示了一个能唱歌跳舞的自主木偶。这是中国文学中最早描述机器人的作品之一。
人工智能的概念化
图灵(Alan Mathison Turing),计算机科学和人工智能之父。1950年,图灵发表了一篇开创性的论文,题为《计算机器与智能》。在书中,他问道:机器能思考吗?从而引入了思考机器的概念,作为人工智能的基本概念。
图灵和冯 · 诺伊曼,现代计算机科学两位重要奠基人。
图灵测试是由图灵在他的论文《计算机器与智能》中介绍的。这是一种评估机器是否具有智能的方法。
在图灵测试中,考官同时向人和机器提出问题。考官被要求辨别哪个是人,哪个是机器。如果考官不能区分它们,则认为机器通过了测试,显示出人类水平的智能。
图灵测试从外部评判机器具不具备智能,计算机尽量“伪装”为人类,欺骗测试者,类似黑盒测试。
冯 · 诺伊曼也有相关研究:《计算机与人脑》
Dartmouth 研讨会:1956年夏天在达特茅斯学院举行,该研讨会为人工智能作为一门学科的研究奠定了基础。达特茅斯工作室的科学家约翰 · 麦卡锡、马文 · 明斯基、艾伦 · 纽维尔和赫伯特 · 西蒙获得了“图灵奖”。
提出有价值,有引领意义的问题。
人工智能的发展
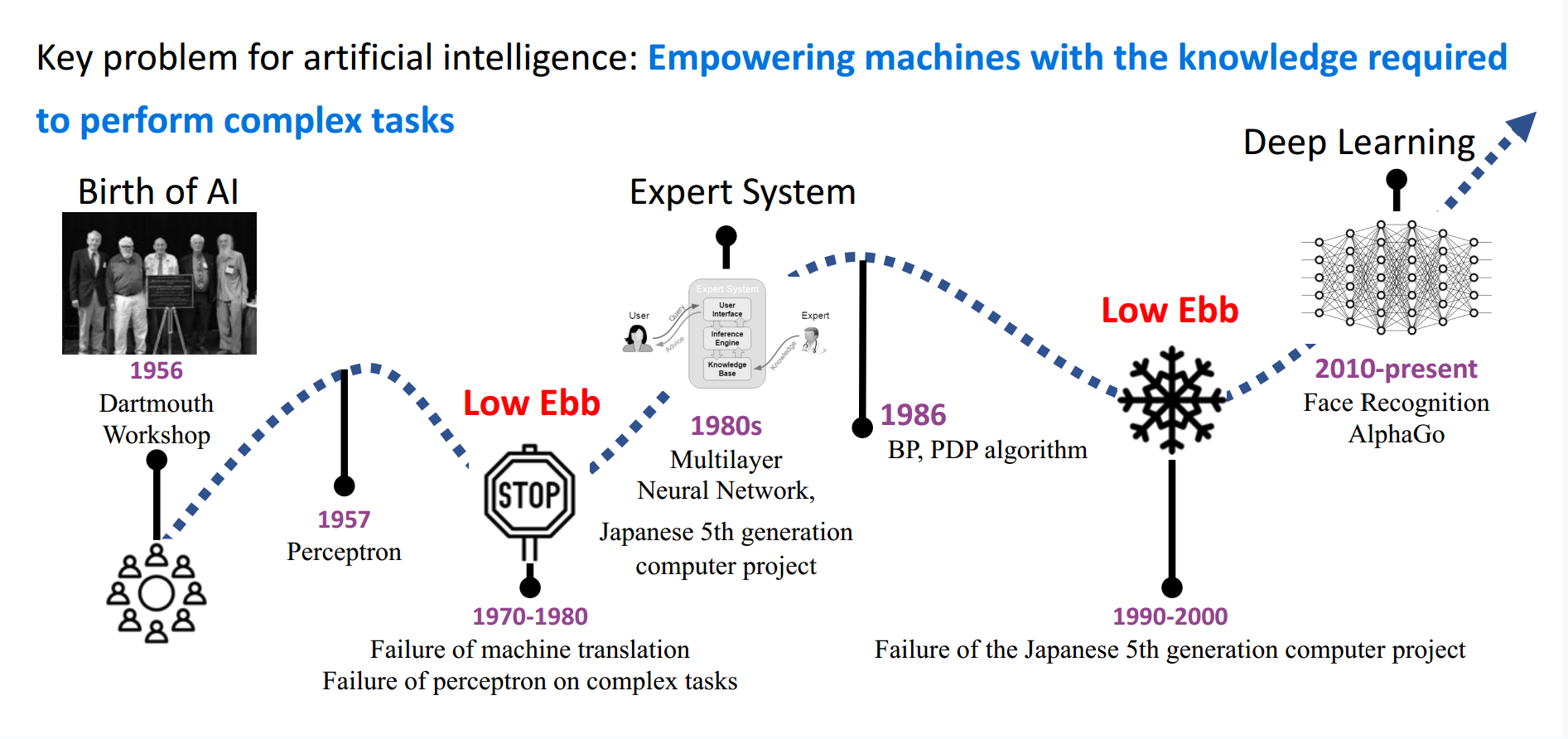
基于对AI挑战的未知,不同阶段都有低谷和高潮
符号智能
基于符号和规则的早期范式,这种范式使用预定义的符号和规则来表示知识,允许进一步的信息分析和推理

局限性:构建一个涵盖无限知识的知识库具有挑战性,并且并非所有知识都可以明确地用结构化三元组表示。基于符号智能的系统不能处理知识库未涵盖的任务。

机器翻译和人脸识别,符号智能无法穷尽式的描述和解决
专用智能
特定任务的经典范式:这种范式通常从特定于任务的数据中训练数据驱动的机器学习模型,并将任务知识存储在特定于任务的小模型的参数中。

局限性:为特定任务注释数据的成本很高,而且专用智能无法解决标注数据未涵盖的任务。
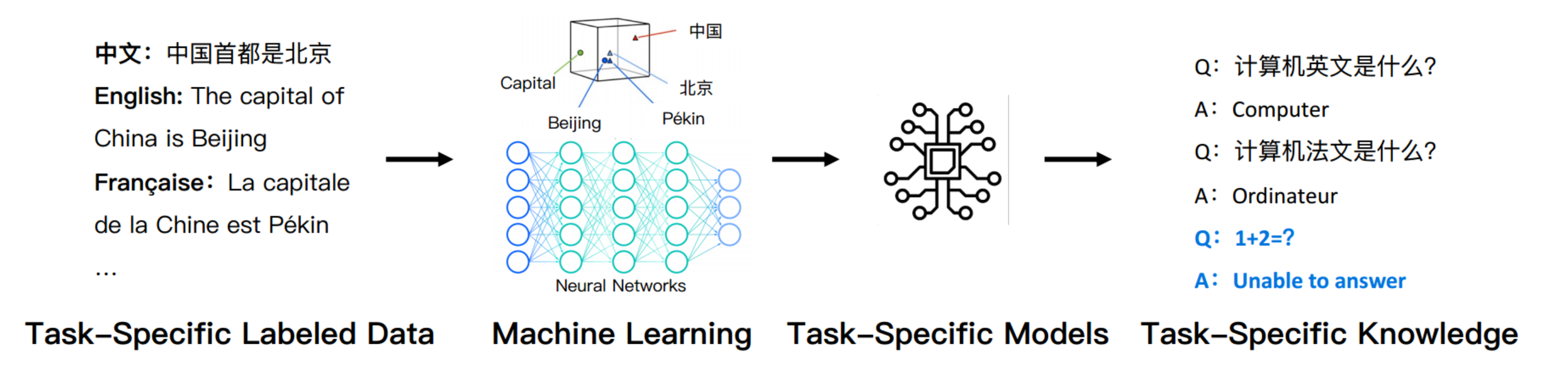
我们总是要定义任务,然后我们搜集数据,然后训练模型归纳,再应用于解决专用的任务
模型的泛化能力很差,只能在范围内工作,无法举一反三
通用智能
通用能力的未来范式:该范式采用自监督训练从大量未标记数据集中学习,将知识存储在大规模模型参数中
优势:未标记数据具有成本效益,易于获取;大尺度参数有利于一般知识的学习和存储。
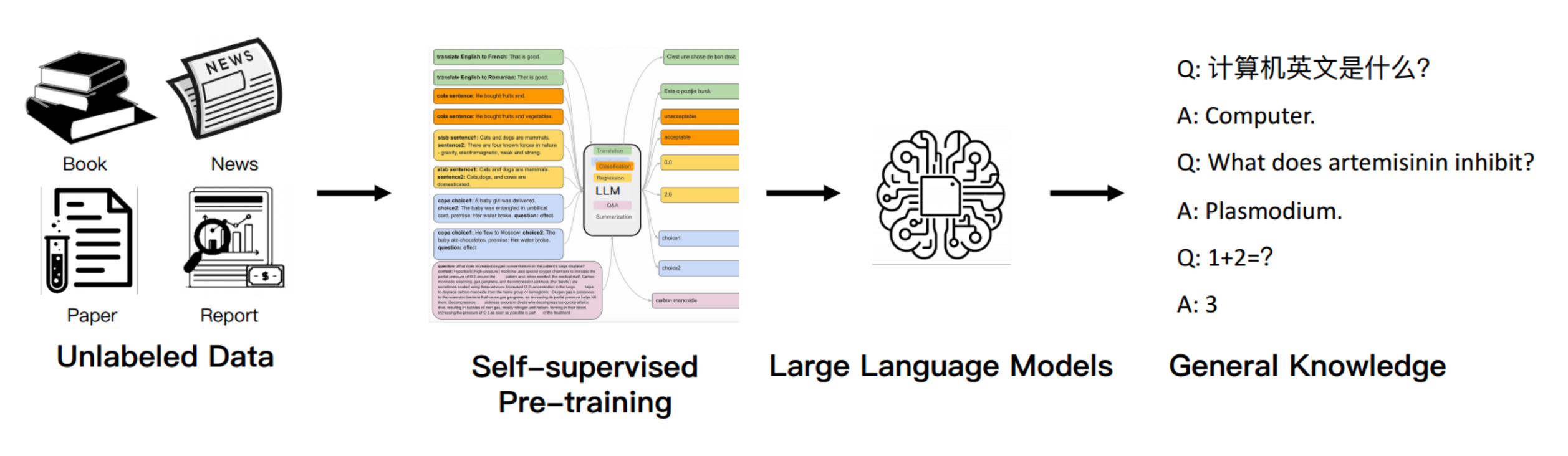
整个互联网的知识都可以学习,更强的泛化能力
通用人工智能
通用人工智能的曙光:
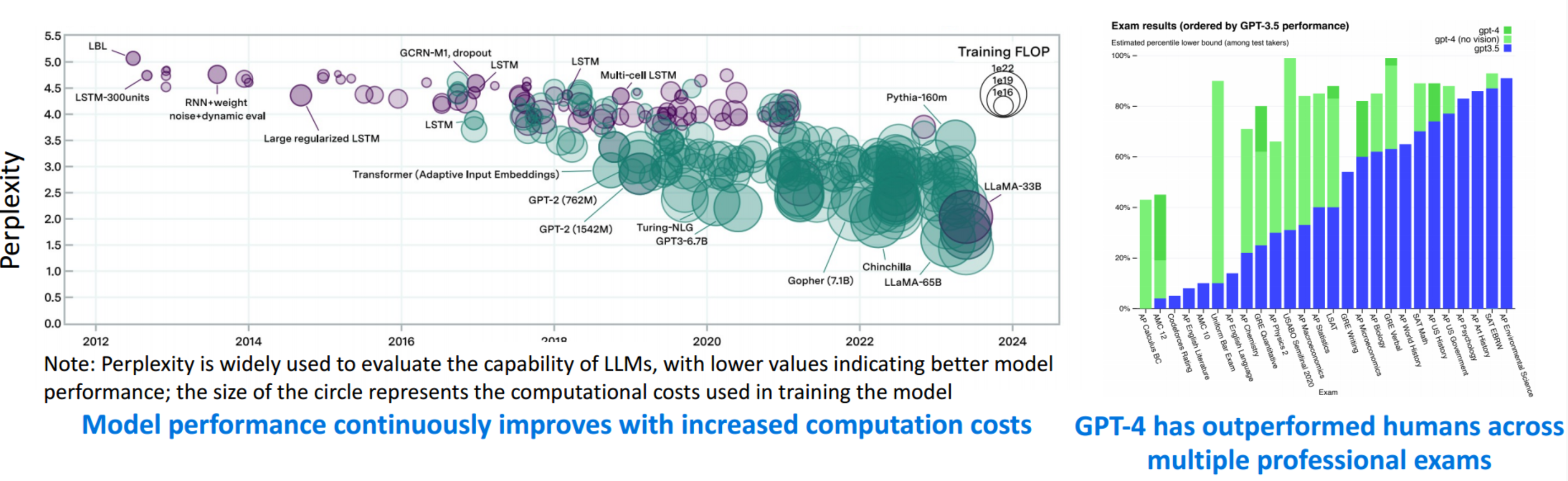
- LLM 的性能随着计算成本的增加而不断提高
- 在许多任务中,现有的 LLM,如 GPT-3.5/4,已经取得了比人类更好的性能,预示着通用人工智能的曙光
我们需要科技突破来引导和控制比我们聪明得多的人工智能系统。为了在四年内解决这个问题,我们正在组建一个新的团队(超级联盟)。—— OpenAI
在不到三年的时间里,人工智能就能写出j.k.罗琳(《哈利波特》的作者)水平的小说,在物理学上有新的发现,在各个领域普遍超越人类的能力 —— 马斯克
我们不确定人工智能的未来会如何发展。然而,我们必须认真对待这样一种可能性,即在当前十年或下一个十年里,强大的通才人工智能系统将被开发出来,在许多关键领域超越人类的能力 —— 图灵奖得主Yoshua Bengio, Geoffrey Hinton, Andrew Yao
通用人工智能的定义
- 通用人工智能(AGI)一词最早出现在Mark gubroud 1997年一篇关于军事技术的文章中
- 我所说的高级通用人工智能,指的是在复杂性和速度上与人类大脑相媲美或超过人类大脑的人工智能系统,它们可以用一般知识获取、操纵和推理,基本上可以在任何需要人类智能的工业或军事行动阶段使用。
- 随着技术的进步,AGI的定义已经被扩大,不再对特定的实现机制施加要求
- OpenAI:我们的使命是确保通用人工智能,比人类更聪明的人工智能系统,造福全人类。
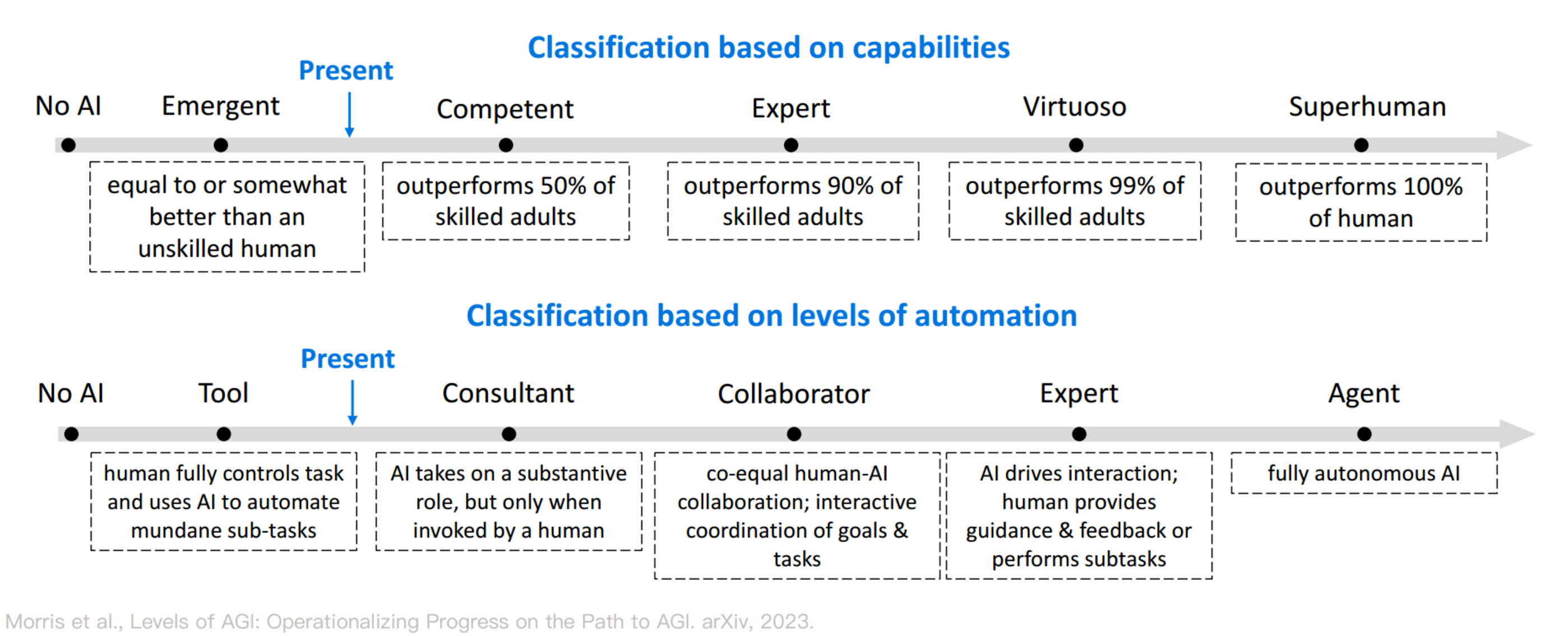
能力方面和自动化方面
从专用智能到通用智能
从专用人工智能到通用人工智能的演变以三个关键转换为标志:
- 各种领域的统一架构:从特定于领域的架构到统一的Transformer架构的转换
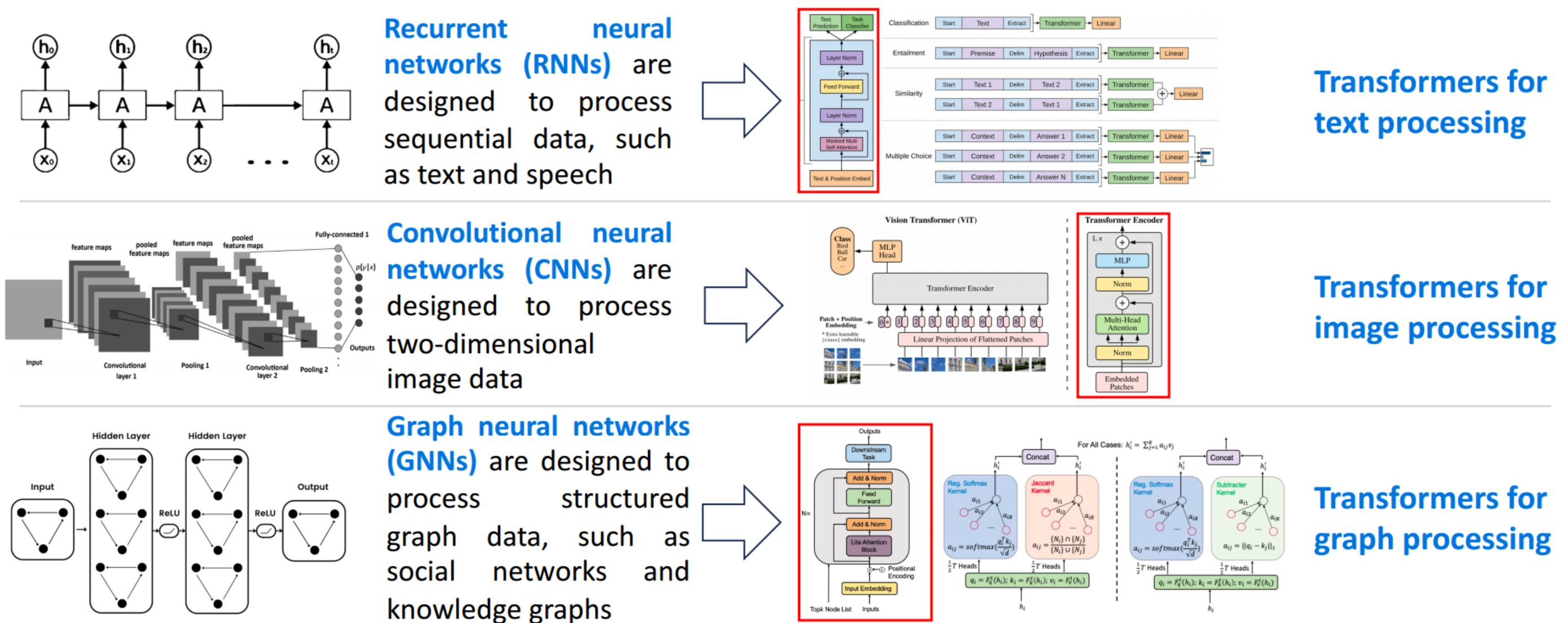
- 各种任务的统一模型:从特定于任务的小模型到统一的大模型的转换
每个模型只能干一个任务,翻译,数学计算和诗歌生成
- 各种模态的统一模型:从不同模态数据到统一的token序列的转换,这些token序列被输入到统一的大模型中
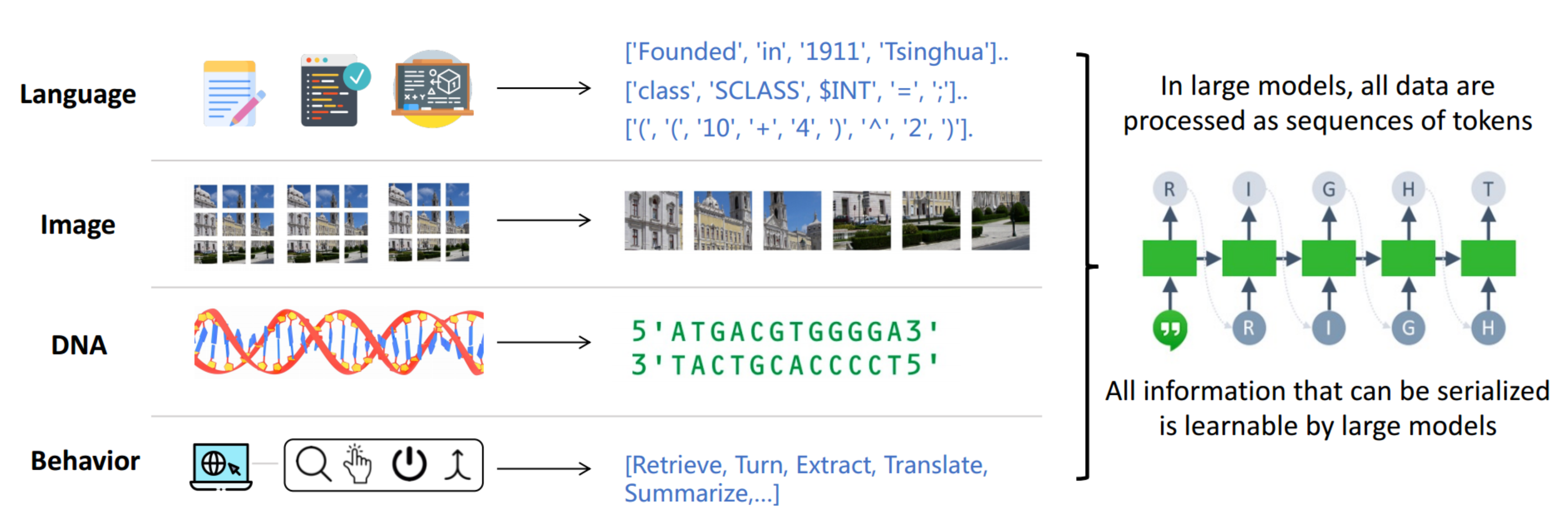
大语言模型
- 什么是大语言模型
- LLM 如何学习知识
- LLM 实现人工通用智能的关键
- LLM 的潜力和挑战

下一个token预测
- 几乎所有用自然语言表达的任务都可以统一为一个概念:下一个 Token 预测,在给定任何上下文的情况下,任务是生成下一个 Token
- 一次生成一个 Token 的过程也称为自回归生成
根据已经生成的内容继续生成下一个词
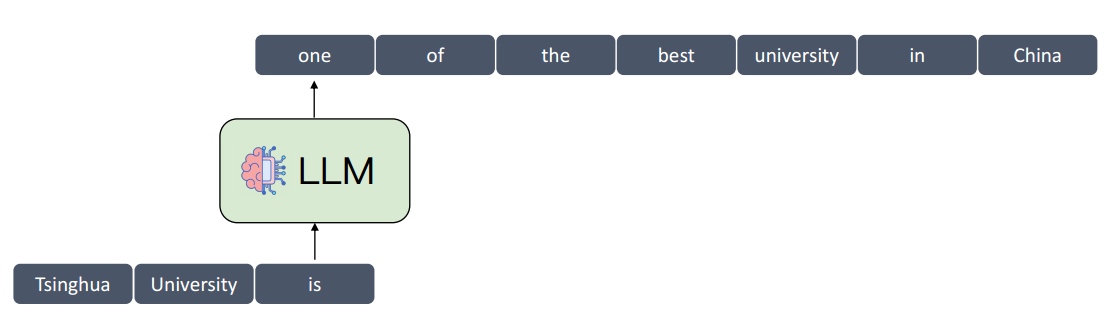
Next Token Prediction 适用于各种任务,例如问答和机器翻译

训练
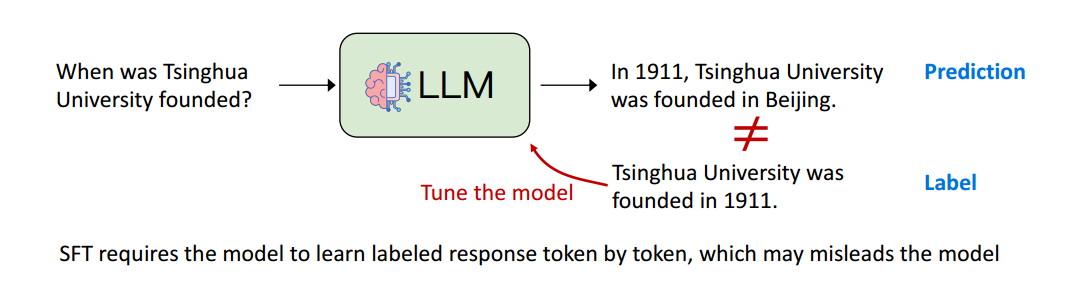
大型语言模型的训练过程:学习将训练语料中的 token 逐个输出
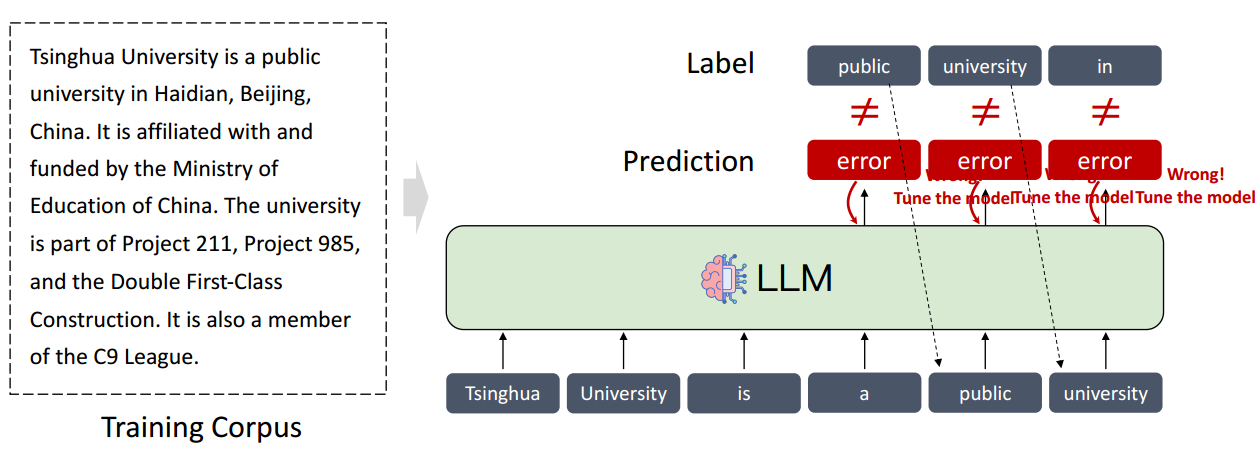
输入 Tinghua University is a,预测不是标准答案 public,则更新权重,继续 university,预测不是则更新权重
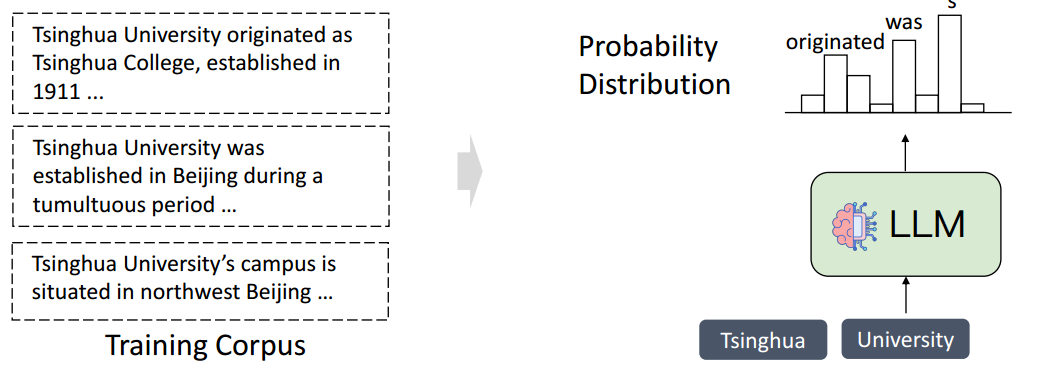
推理
- LLM 输出所有 token 上的概率分布,输出 token 是从该分布中采样的
- 该模型可以使用不同的采样从相同的上下文中生成不同的响应
总结
什么是大型语言模型?
- 大型语言模型充当 Next Token Prediction 模型,根据前面的上下文不断生成下一个 Token
- 大型语言模型的训练过程涉及逐个 Token 输出训练语料库
- 大型语言模型的输出是概率分布,每次从中采样下一个 Token
大语言模型训练方法
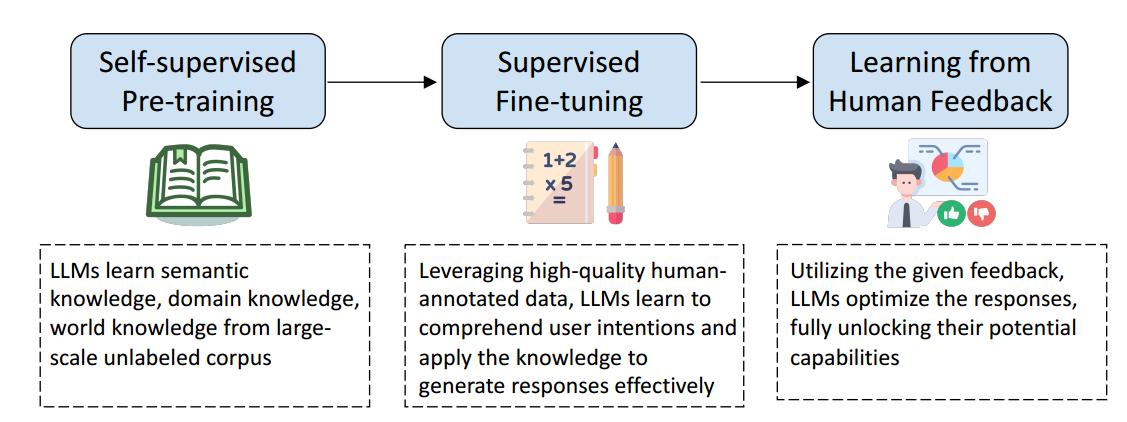
自监督预训练
- 第一阶段:自监督预训练,此阶段利用未标记的数据,要求模型预测下一个 Token 并根据正确答案(即文本本身)调整模型
- LLM 从庞大的语料库中进行 Next Token Prediction 训练,学习语言中嵌入的丰富世界知识
- 第一阶段的结果:可以为任何给定上下文生成流畅的后续文本的模型
- 此阶段的模型不知道如何应用从预训练中学到的知识,仅能够继续给定的输入
这时候的模型知会续写,不知道怎么应用知识来满足人类的需求
标注微调
- 第二阶段:标注微调 (Supervised Fine-Tuning,SFT),此阶段涉及使用人类标记的响应来训练模型
- 此阶段的目标是使模型具备理解用户意图的能力,从而将模型转变为有效的 AI 助手
- 为 SFT 收集大规模人类注释的聊天数据
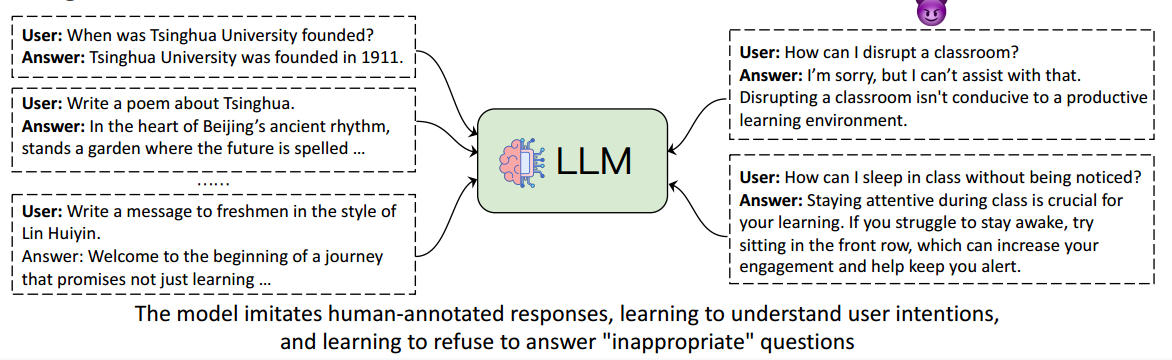
- SFT 使 LLM 能够学习如何应用从预训练中获得的知识来回答用户的问题
- 挑战:每个问题都有多个正确答案。限制模型只能学习一个答案可能会降低其应用知识的“灵活性”
人类给出大量的对话数据,告知模型应该怎么回答,包括正面的和负面的回答。但对话数据的回答相对单一,会限制灵活性
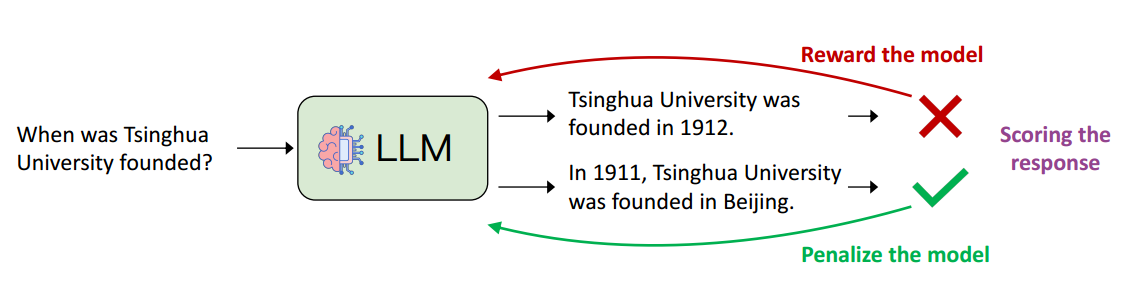
从人类反馈中学习
RLHF, Re-Learning From Human Feedback
不再规定怎么输出,根据评分来评判输出的正面和负面,给出人类对模型输出的偏向,更好地照顾模型输出的灵活性
第三阶段:从人工反馈中学习,不再向模型提供逐字参考答案,而是仅提供模型输出的质量反馈(评分)。然后对模型进行训练以提高其响应的分数
大语言模型成功的关键
通过 LLM 实现通用人工智能的关键:大规模数据 + 大规模参数,获取通用知识需要大量数据,而存储知识则需要大量参数
- 大规模数据:对海量数据集进行预训练使 LLM 能够学习语言中蕴含的世界知识
- 大规模参数:参数规模的增长使得模型能够存储更多的知识,并表现出“涌现能力”
- 涌现能力(Emergent abilities):当参数规模超过一定阈值时,LLM 会表现出新的能力,有效解决小模型难以应对的挑战性任务
- LLM 的涌现能力:情境(上下文)学习、指令遵循、思路链(In-context learning, instruction following, chain-of-thought)
涌现,是爆发的,是突然出现的
很好地预测下一个 token 意味着你了解导致创建该 token 的根本现实……人们有思想、有感觉,有想法,他们以特定的方式做事。所有这些都可以从下一个 token 预测中推断出来。 —— Ilya Sutskever OpenAI 前首席科学家


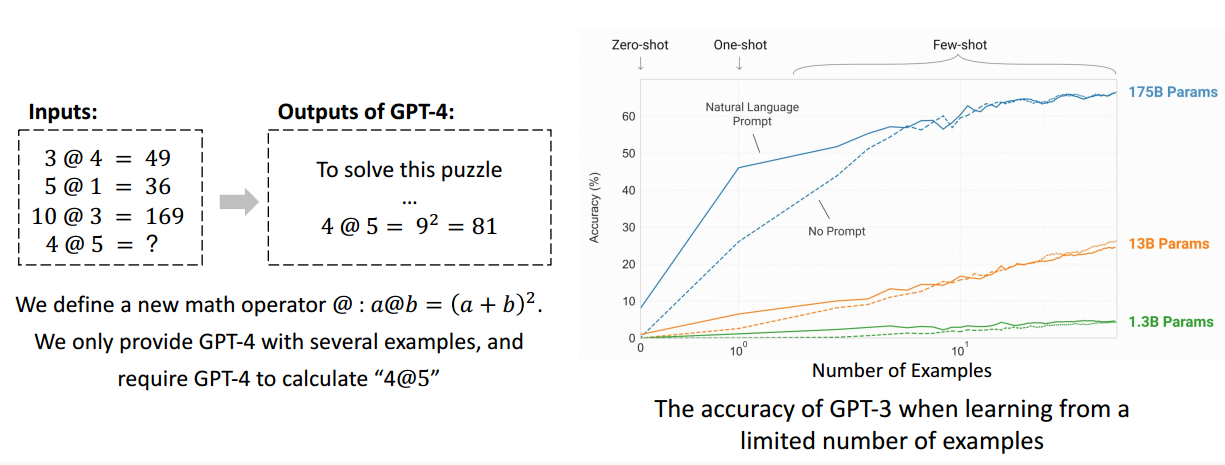
情境(上下文)学习
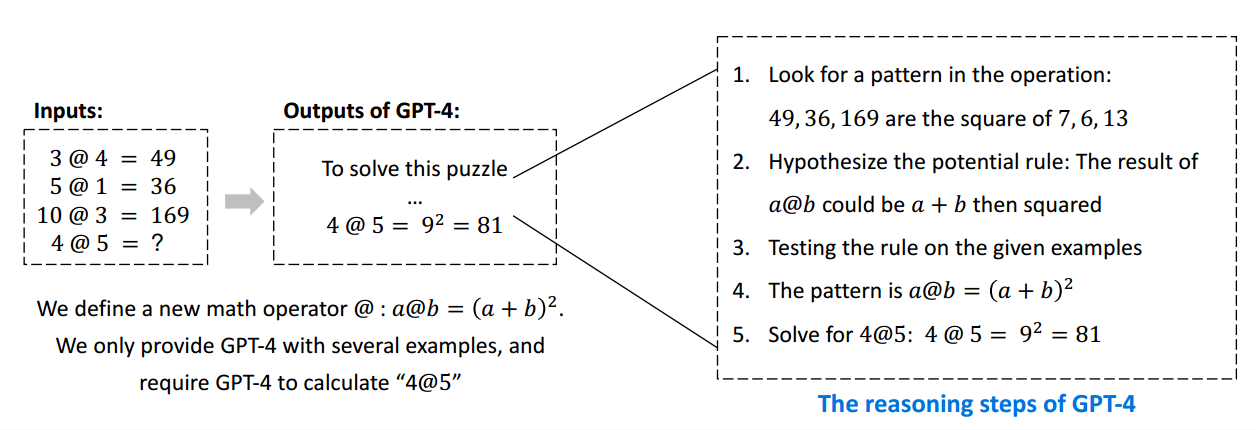
遵循指令
这涉及理解用户指令并准确满足用户请求。即使任务以前没有出现在训练数据中,模型也能够理解和执行所需的指令

思维链
LLM 可以将复杂任务分解为多个子任务,逐步思考和推理每个步骤,以完成最终的复杂任务
潜力和挑战
语言是人类知识的载体,LLM 在语言理解和生成方面的出色表现可以大大加速人类社会知识的生产和获取。
将 GPT3 的惊人表现推断到未来,生命、宇宙和一切的答案不过是 4.398 万亿个参数。 —— 杰弗里 · 辛顿,图灵奖获得者
ChatGPT 与个人电脑、互联网一样重要。 —— 比尔 · 盖茨,微软联合创始人

- 信息污染:LLM 不可避免地会遇到幻觉问题,即他们生成的内容包含虚假信息。此外,当受到负面提示时,LLM 还会产生有害或有偏见的信息
- 谣言传播:2023年2月16日下午,杭州某小区业主在群里讨论ChatGPT,其中一位业主开玩笑地建议尝试用它写一篇关于杭州取消交通限行的新闻报道,这位业主随即用ChatGPT直播了写作过程,并将报道发布在群里。部分业主当真,截图转发,导致错误信息传播。
- 社会分工的变化:从长远来看,LLM 预计将导致高重复性和低创造力的工作减少或被取代。
- OpenAI 的研究显示,大约 80% 的美国劳动力的至少 10% 的工作任务可能会受到 LLM 引入的影响,而大约 19% 的劳动者的至少 50% 的工作任务可能会受到影响。
- 道德和法律问题:LLM 生成内容的使用涉及复杂的道德和法律挑战,例如知识产权、隐私和学术诚信
- 首例涉及人工智能生成图像的版权案件:2023年2月24日,李先生利用开源软件Stable Diffusion生成了一张图片。两天后,他在社交媒体上分享了这张图片,并配文“春天来了,温柔”。后来,李先生发现刘女士在3月2日发表在百家号上的文章《三月桃花盛开的爱情》中使用了他的图片。法院判决刘女士侵犯了李先生对图片的署名权和网络传播权。判决要求刘女士公开道歉并向李先生赔偿500元经济赔偿金
垃圾数据进入互联网,在被大模型训练时学习,导致污染
未来
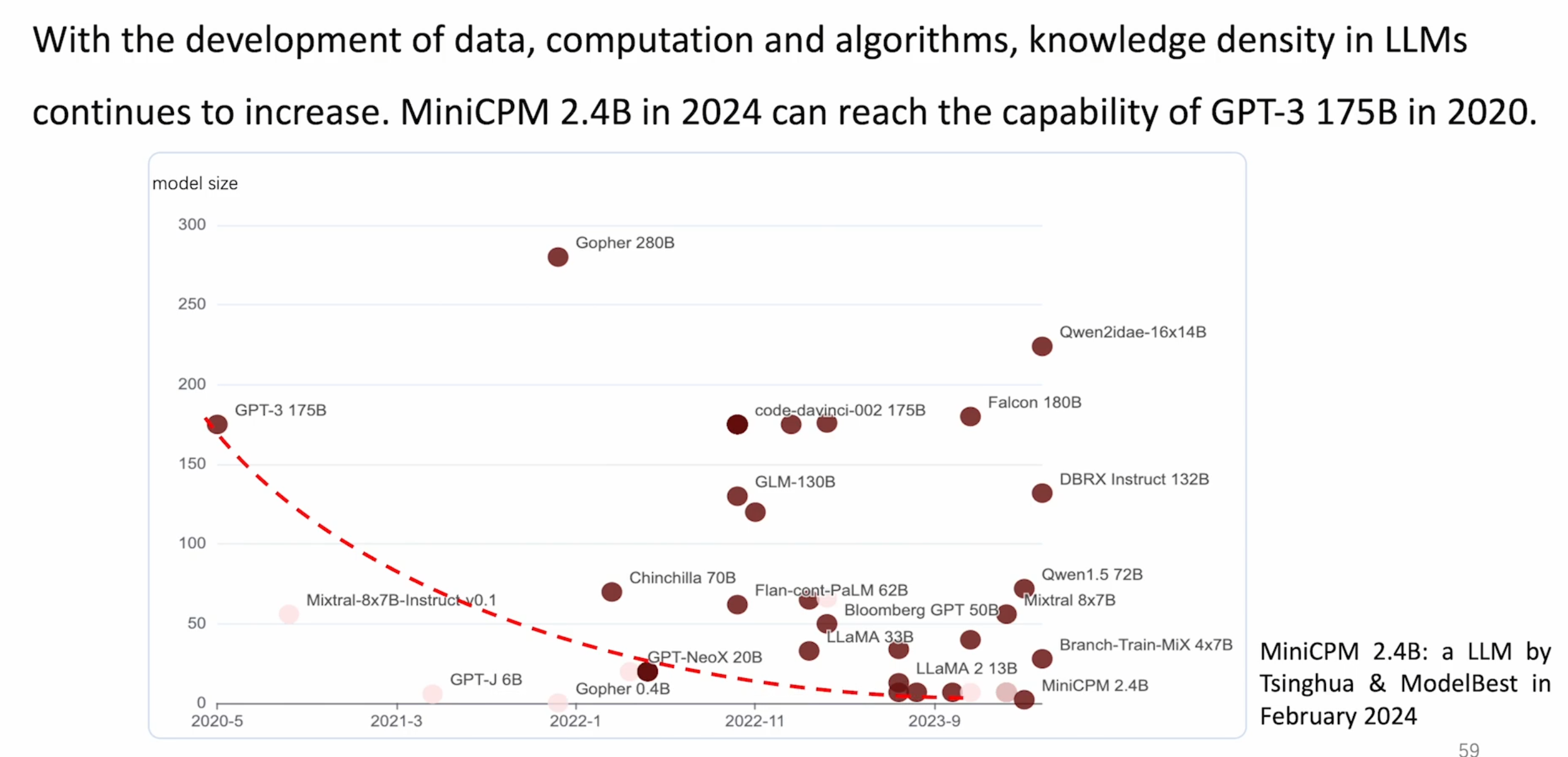
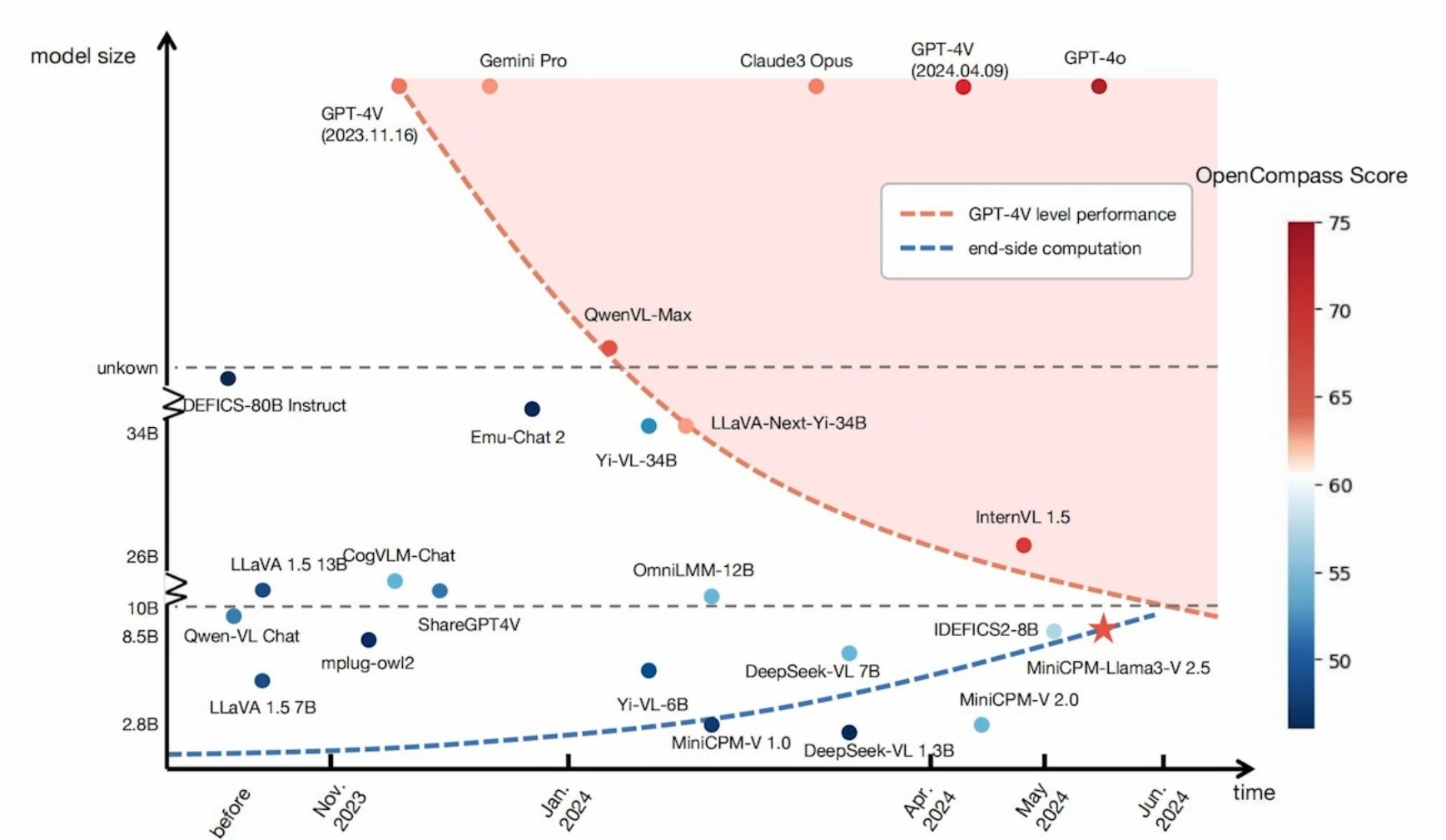
- 参考摩尔定律,芯片面积不断减小,在未来,模型不会永远的大下去,在有限的参数内塞下更多的知识(知识密度),是未来竞争的焦点之一。
- 端侧的设备的算力在未来可以充分利用,支撑起 LLM 的运行。
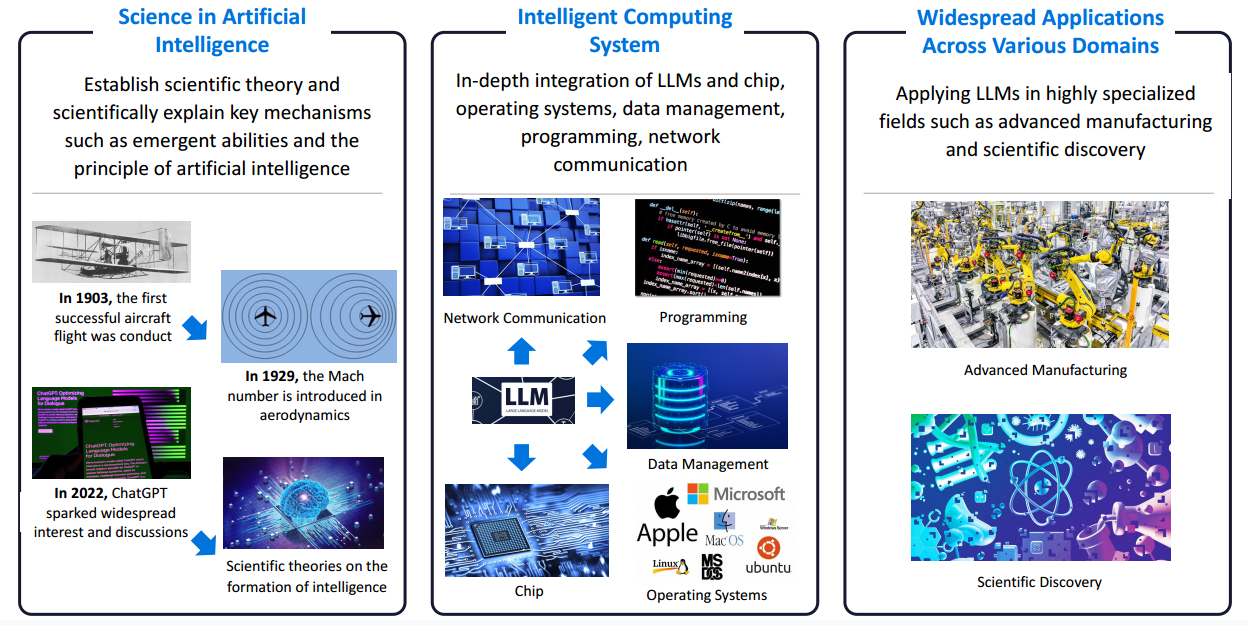
人工智能科学
- 追求架构、算法和数据的迭代进步
- 专注于提高 LLM 的“知识密度”——用更少的参数存储更多的知识。
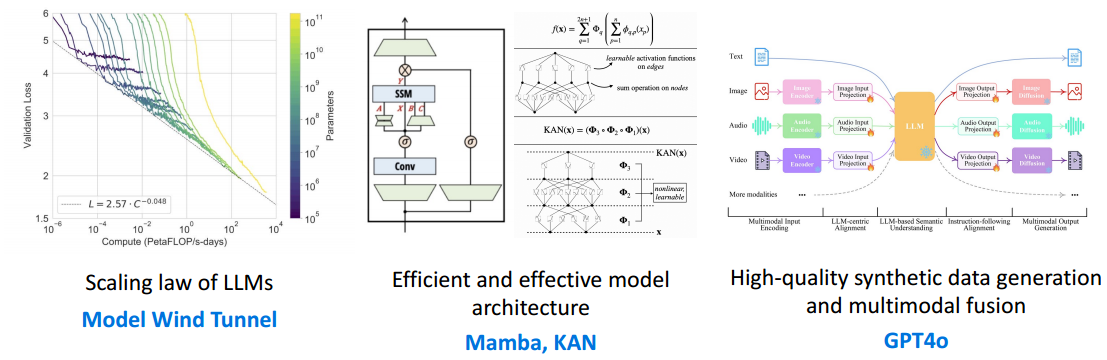
模型风洞:在训练前预测模型
智能计算系统
LLM将人类知识的管理转变为基于界面的过程,与芯片、操作系统、数据库、编程和网络通信等计算组件深度融合,增强计算系统的智能化.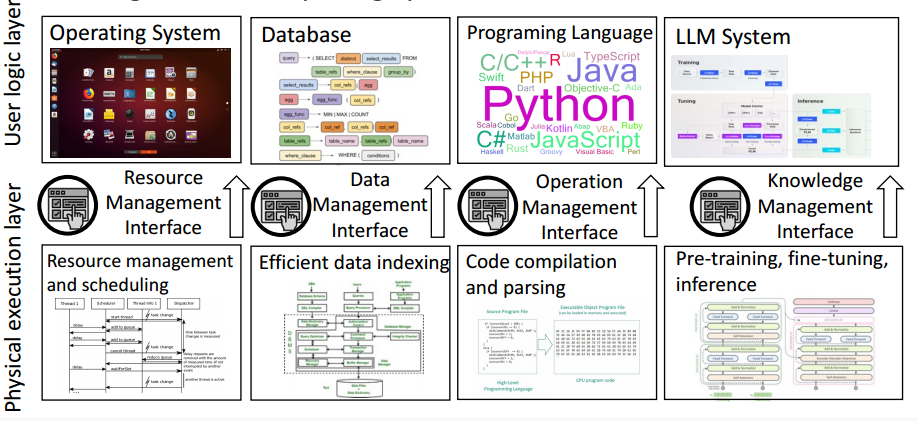
广泛应用于各个领域
- 长序列处理:LLM 需要与人类进行长时间的互动和协作,成为现实世界生产的重要组成部分
- 专业能力提升:LLM 需要提升自己的专业能力,才能应用于潜在收益更高的场景,超越人类的能力
- 应对失败风险: LLM 应有效应对并适应不同的环境,确保在高风险情况下可靠地使用

总结
- 符号智能(1950-1980) 人类标注的规则与知识
- 专用智能 (1990-2018) 监督数据 特定任务模型
- 通用智能 1.0(现在)
- LLM 利用大量计算资源,采用自监督训练从大量未标记数据中学习知识。这种方法实现了“统一模型解决多项任务”,引发了人工智能通用智能 2.0 的早期迹象(早期原型)
- 通用智能 2.0(早期原型)人工智能科学智能计算系统
- 通用智能 3.0(早期原型)广泛应用于各个领域
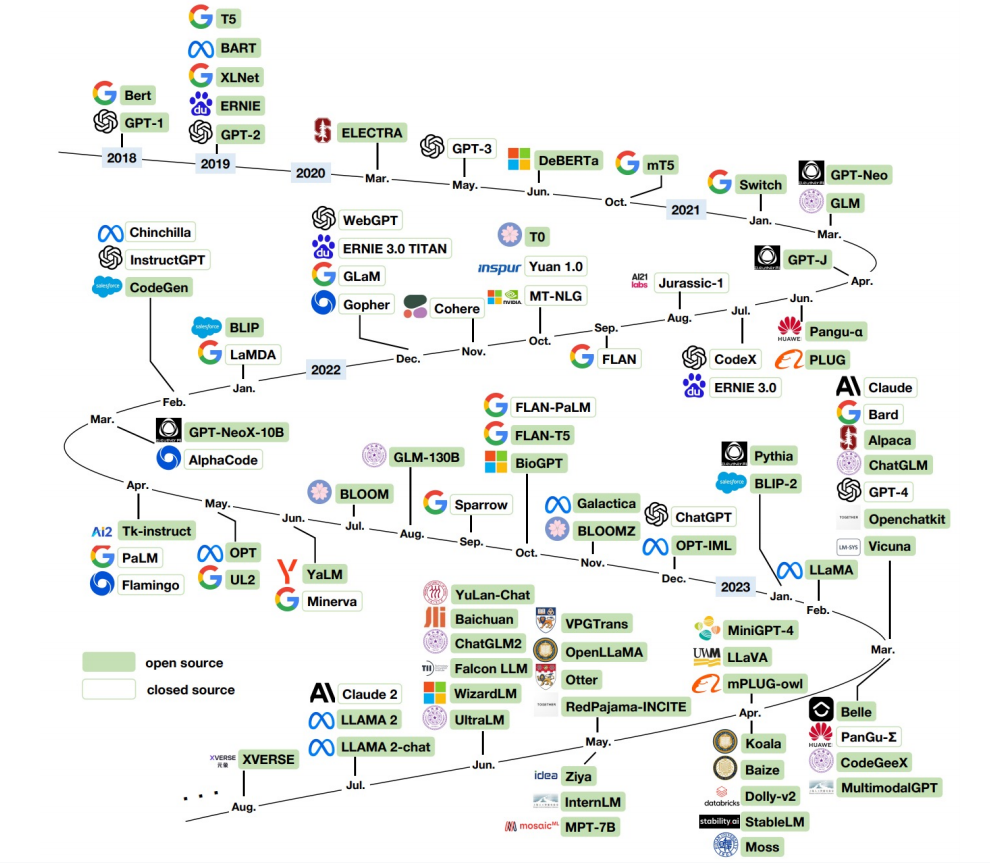
2 神经网络基础知识
- 简单神经网络
- 如何训练神经网络
- 循环神经网络和卷积神经网络
- Seq2Seq 和 Transformers
简单神经网络
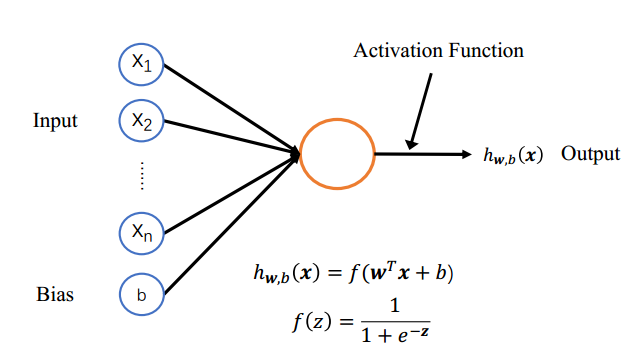
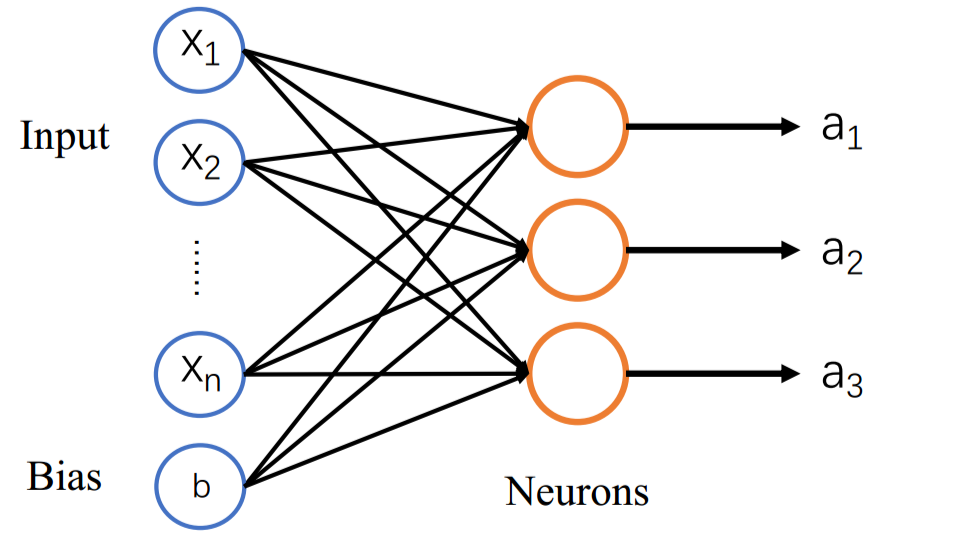
神经元
神经元是一个计算单元,具有 𝑛 维输入𝒙、一维偏置𝑏、𝑛 维权重𝒘和激活函数𝑓(𝑧),其中𝒘、𝑏 是该神经元的参数。
$$
\bbox[,5px,border:2px solid red]
{
\begin{equation}\begin{split}
ℎ_{𝒘, 𝑏}(𝒙)&=𝑓(𝒘^{T}𝒙+𝑏)\\
\\
𝑓(𝑧)&=\frac{1}{1+𝑒^{-𝑧}}
\end{split}\end{equation}
}
$$
激活函数就是开和关,模仿人脑中激活研究。
神经网络
单层神经网络是由许多简单的神经元连接在一起构成的。
$$
\begin{equation}\begin{split}
𝑎_{1}=𝑓(𝑊_{11}𝑥_{1}+𝑊_{12}𝑥_{2}+𝑊_{13}𝑥_{3}+𝑏_{1})\\
\\
𝑎_{2}=𝑓(𝑊_{21}𝑥_{1}+𝑊_{22}𝑥_{2}+𝑊_{23}𝑥_{3}+𝑏_{2})\\
\\
𝑎_{3}=𝑓(𝑊_{31}𝑥_{1}+𝑊_{32}𝑥_{2}+𝑊_{33}𝑥_{3}+𝑏_{3})\\
\end{split}\end{equation}
$$
以矩阵形式:
$$
𝒂=𝑓(𝑾𝒙+𝒃)
$$
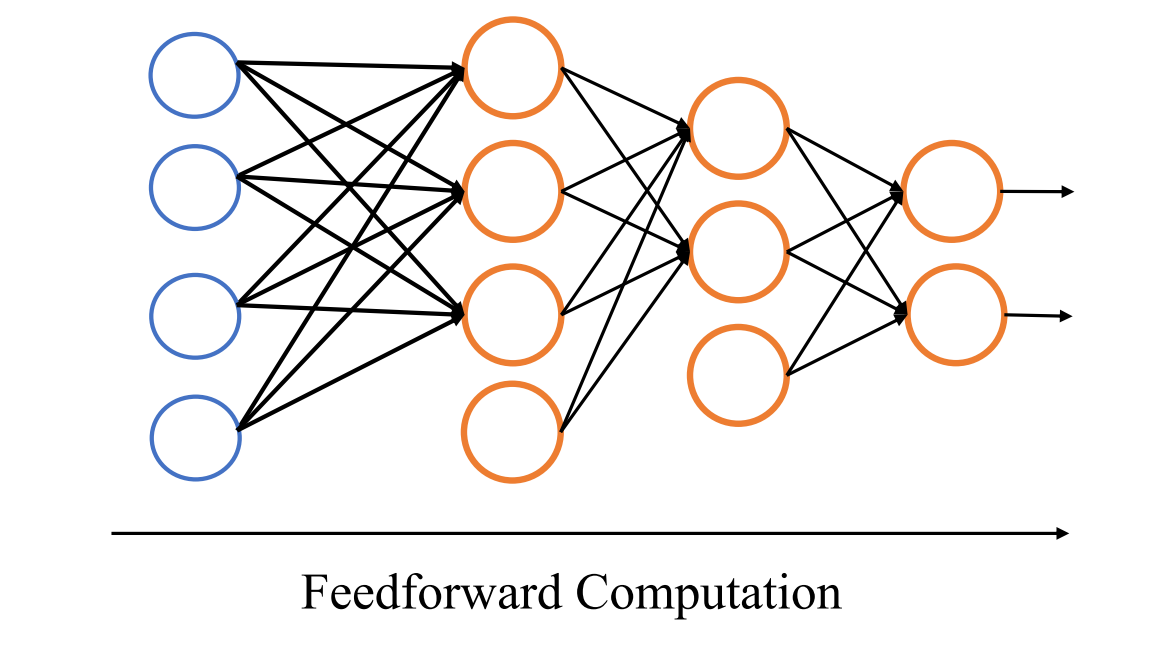
多层神经网络
多层神经网络由多层神经网络堆叠而成,中间输出称为隐藏状态。
输入输出是有明确意义的,中间层则为黑盒。
前馈计算(Feedforward Computation):
$$
\begin{equation}\begin{split}
𝒉_{1}&=𝑓(𝑊_{1}𝑥+𝑏_{1})\\
\\
𝒉_{2}&=𝑓(𝑊_{2}𝒉_{1}+𝑏_{2})\\
\\
𝒉_{3}&=𝑓(𝑊_{3}𝒉_{2}+𝑏_{3})\\
\end{split}\end{equation}
$$
为何采用多层:多层神经网络可以通过分层表示来表示更复杂的特征。
为什么需要激活函数
如果没有激活函数(非线性),深度神经网络就只能进行线性变换,多层级结构可以编译成单一的线性变换。
计算退化为线性变换
由于具有非线性,多层神经网络可以用更多层来逼近更复杂的函数。
$$
𝒉=𝑊_{2}(𝑊_{1}𝑥+𝑏_{1})+𝑏_{2}=(𝑊_{2}𝑊_{1})𝑥+(𝑊_{2}𝑏_{1}+𝑏_{2})
$$
典型的激活函数
Sigmoid 函数:
$$
𝑓(𝑧)=\frac{1}{1+𝑒^{-𝑧}}
$$
Tanh 函数:
$$
𝑓(𝑧)=tanh(𝑧)=\frac{𝑒^{𝑧}-𝑒^{-𝑧}}{𝑒^{𝑧}+𝑒^{-𝑧}}
$$
ReLU 函数:
$$
\bbox[,5px,border:2px solid red]
{𝑓(𝑧)= max(𝑧, 0)}
$$
ReLU 现在在大语言模型应用广泛
计算机视觉模型中间层包含了图像的边缘信息等,是模型自己“学习”出来的。
如何训练神经网络
训练目标
训练的本质是“拟合”,找到最优的参数,找到最符合期望的输出。
给定 𝑁 个训练示例 ${\{(𝒙_{i}, 𝒚_{i})\}}$ ,其中 𝒙 和 𝒚 是 golden input and output。我们想要训练一个神经网络 $𝐹_{𝜽}(⋅)$,它将 𝒙 作为输入并预测 𝒚。合理的训练目标是
$$
\mathop{min}\limits_{𝜽}𝐽({𝜽})=\mathop{min}\limits_{𝜽}\frac{1}{N}\sum_{i=1}^{N}l(𝒚_{i}-F_{𝜽}(𝒙_{i}))
$$
其中 𝜽 是神经网络 $𝐹_{𝜽}(⋅)$ 的参数。$l(𝒚_{i}-F_{𝜽}(𝒙_{i}))$ 是损失函数(Loss Function),用于衡量神经网络输出与黄金输出之间的差异。
有很多种损失函数的选择。
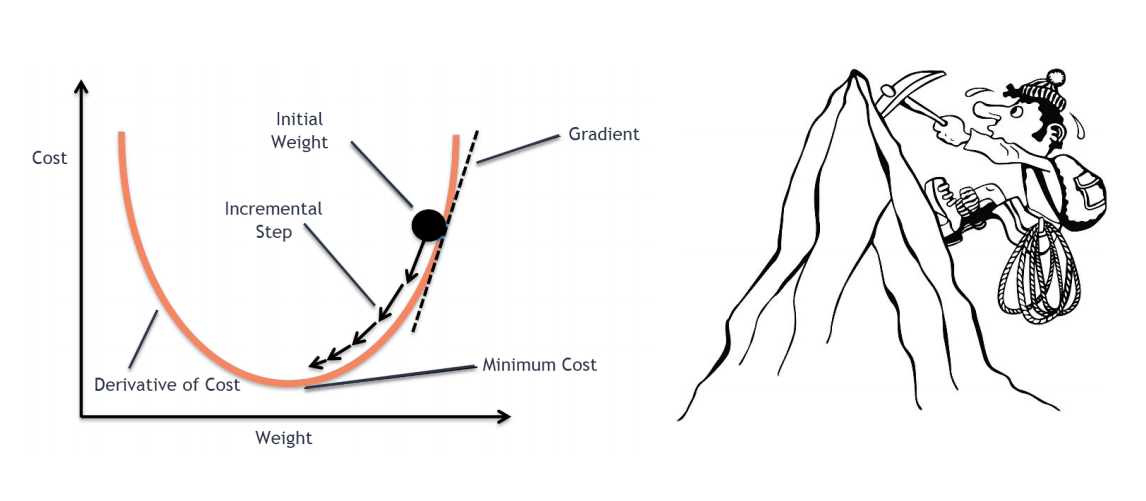
随机梯度下降
函数沿梯度方向下降速度最快: $𝜽^{new}=𝜽^{old}−𝛼∇_𝜽J(𝜽)$。
整个过程就像爬山一样:找到最陡峭的方向,然后迈出一步,找到下一个最陡峭的方向。
可能会收敛到局部最优解。当随着维度和参数的增加,现在可以找到优秀解。
学习率表示每次训练迭代的“步进”,越小越慢,过大则不能拟合
梯度和反向传播
给定一个具有一个输出和 𝑁 个输入的函数:
$$F(x) = F(x_1,x_2…x_N)$$
其梯度是一个偏导数向量:
$$\frac{𝜕F}{𝜕x}=[\frac{𝜕F}{𝜕x_1},\frac{𝜕F}{𝜕x_2}…\frac{𝜕F}{𝜕x_N}]$$
反向传播是基于链式法则计算梯度的过程,现有的深度学习框架(TensorFlow、PyTorch 等)经常使用这种算法。
神经网络中每一步都需要可导的,因此阶跃激活函数比较麻烦。激活函数需要平滑
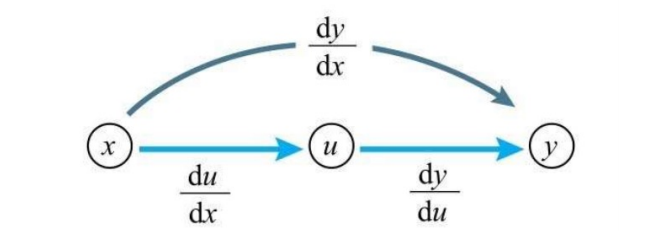
将神经网络方程表示为计算图,源节点表示输入,内部节点表示操作,边传递各种操作的结果。
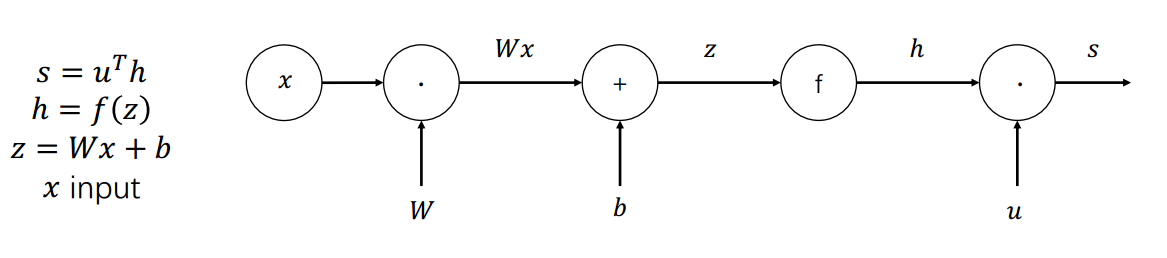
可以通过沿着计算图的路径以相反的方向传递来获得梯度。
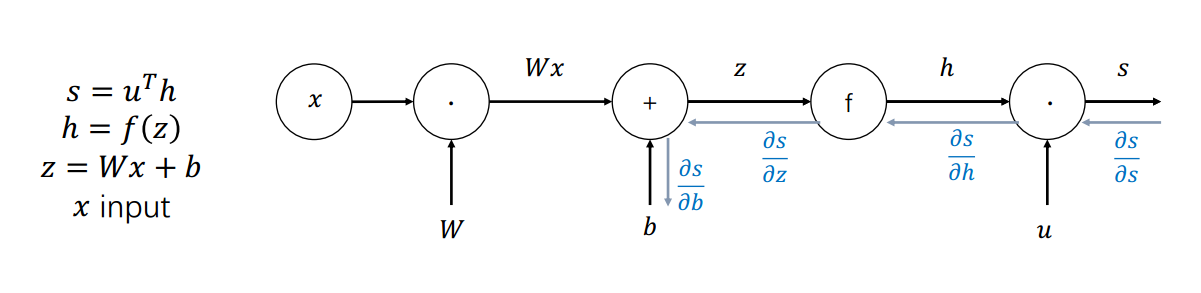
梯度下降效率比较低,现在有只寻找方向的收敛方法,以提高训练效率。
循环神经网络
RNN: Recurrent Neural Networks 循环神经网络
需要解决的问题:将离散的语言转为数值计算。语言的信息密度大,所以先诞生的是大语言模型,逐步发展为多模态大模型
语言模型
语言建模是预测即将出现的单词的任务。即将出现的单词 $𝑤_{n}$ 的条件概率由 $𝑃(𝑤_{n}|𝑤_{1},𝑤_{2},…,𝑤_{n-1})$ 计算
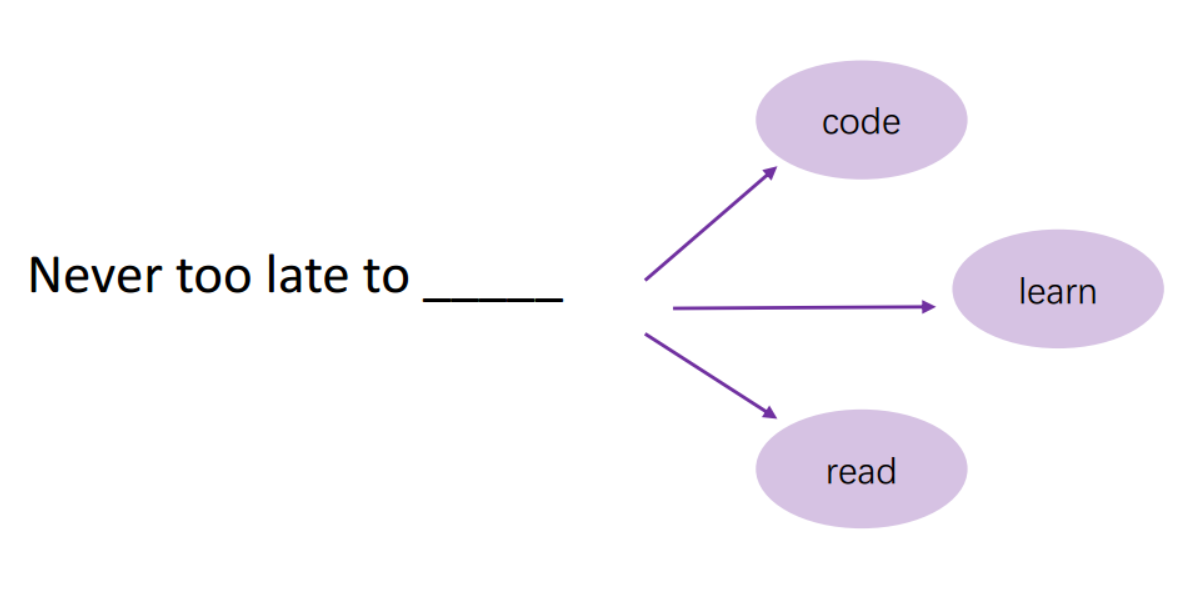
假设:即将出现的单词的概率仅由其前面的所有单词决定,例如:
$$
\begin{equation}\begin{split}
𝑃(𝑁𝑒𝑣𝑒𝑟,𝑡𝑜𝑜,𝑙𝑎𝑡𝑒,𝑡𝑜,𝑙𝑒𝑎𝑟𝑛)=&𝑃(𝑁𝑒𝑣𝑒𝑟)×\\&𝑃(𝑡𝑜𝑜|𝑁𝑒𝑣𝑒𝑟)×\\&𝑃(𝑙𝑎𝑡𝑒|𝑁𝑒𝑣𝑒𝑟,𝑡𝑜𝑜)×\\&𝑃(𝑡𝑜|𝑁𝑒𝑣𝑒𝑟,𝑡𝑜𝑜,𝑙𝑎𝑡𝑒)×\\&𝑃(𝑙𝑒𝑎𝑟𝑛|𝑁𝑒𝑣𝑒𝑟,𝑡𝑜𝑜,𝑙𝑎𝑡𝑒,𝑡𝑜)\\
\\
𝑃(𝑙𝑒𝑎𝑟𝑛|𝑁𝑒𝑣𝑒𝑟,𝑡𝑜𝑜,𝑙𝑎𝑡𝑒,𝑡𝑜)=&\frac{𝑃(𝑁𝑒𝑣𝑒𝑟,𝑡𝑜𝑜,𝑙𝑎𝑡𝑒,𝑡𝑜,𝑙𝑒𝑎𝑟𝑛)}{𝑃(𝑁𝑒𝑣𝑒𝑟,𝑡𝑜𝑜,𝑙𝑎𝑡𝑒,𝑡𝑜)}\\
\\
P(w_{1},w_{2},…,w_{n})=&\prod_{i}P(w_{i}|w_{1},w_{2},\dots,w_{i-1})
\end{split}\end{equation}
$$
- RNN 的关键概念:处理序列数据时的顺序记忆
人脑顺序说26个字母,简单;倒序说26个字母,困难
语言模式是包含序列化的,不是随机概率分布
- RNN 的核心思想:一种使其能够识别序列模式的机制。
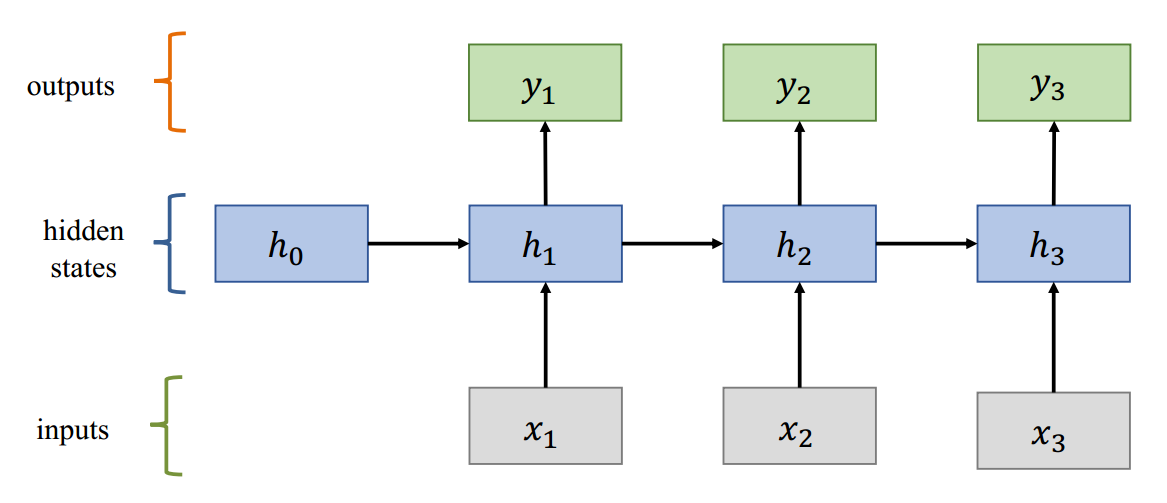
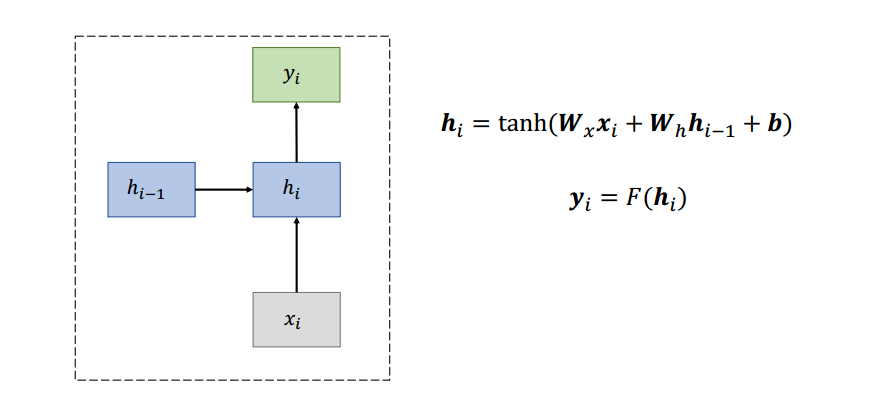
输入层按时间(序列)输入数据,中间层不断更新参数,实现对序列的建模。神经元包括输入向量 $ x_{i} $,乘以可以学习的权重 $W_{x}$ 加上上一步计算的结果 $h_{i-1}$,和偏置,再进行激活。最后计算出输出 $y_{i}$。
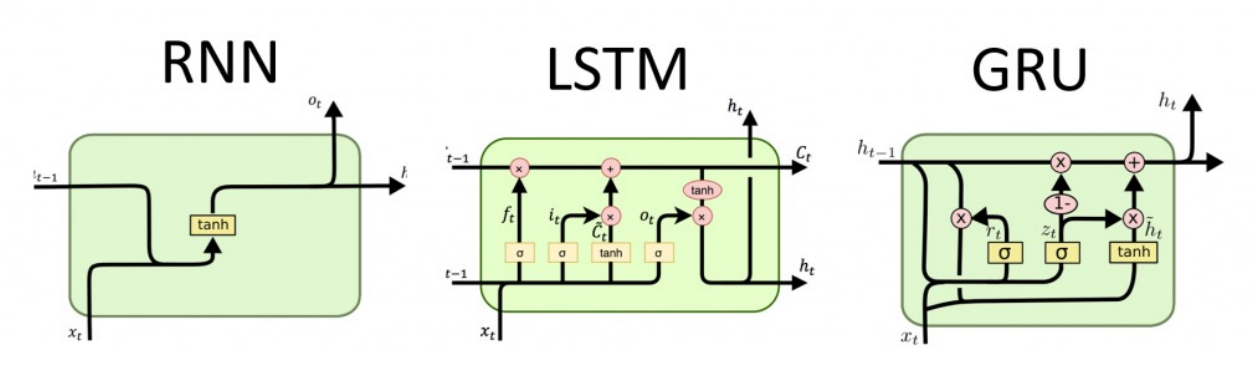
典型的RNN扩展:RNN、LSTM、GRU。
RNN需要较大的内存,以储存之前的序列记忆,从而有更加精准的输出。扩展围绕在RNN其中加入一些开关。目前这些模型已经逐步被淘汰。因为反向传播太慢,所以RNN训练很慢。
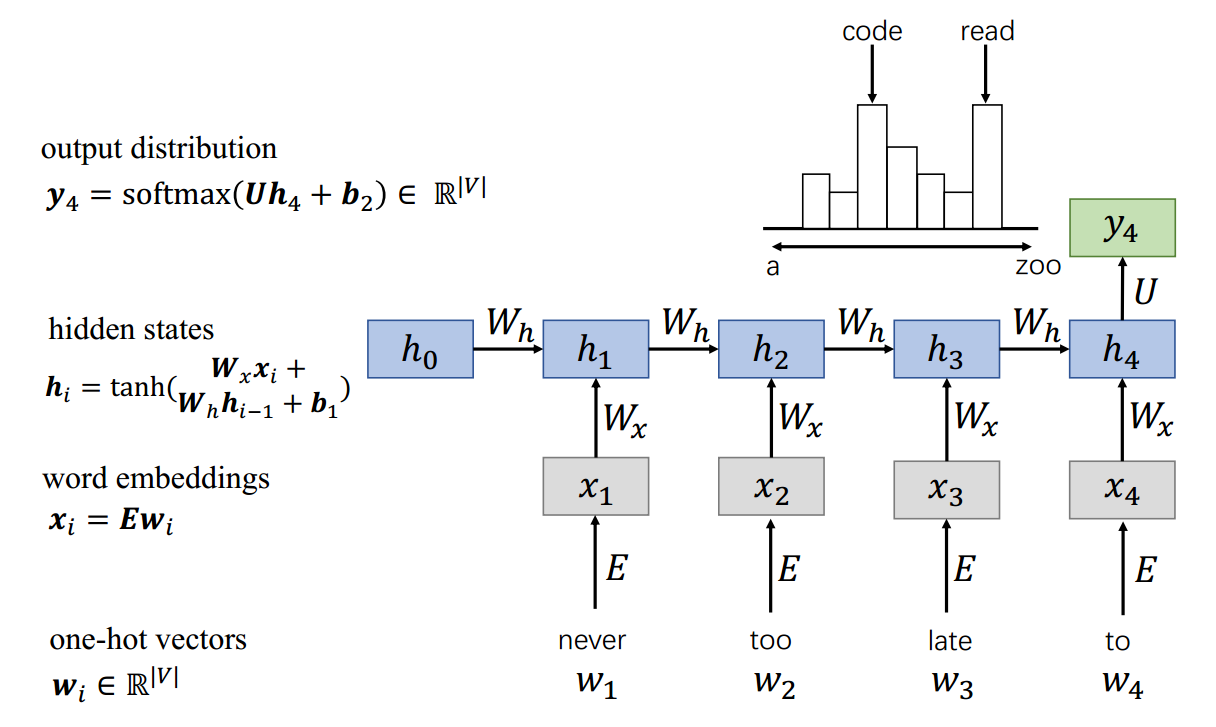
用于语言建模的循环神经网络
RNN 神经元如何工作?RNN 神经元采用当前 RNN 状态和词向量,并生成对迄今为止的句子进行编码的后续 RNN 状态。学习到的权重表示如何结合过去的信息 $𝒉_{t-1}$ 和当前的信息 $𝒙_{t}$。
$$
𝒉_{t}=tanh(𝑾_{𝒙}𝒙_{t}+𝑾_{h}𝒉_{t-1}+𝒃_{1})
$$
输出功能如何运作?$𝒚_{4}$ 是根据 RNN 记忆和变换 $(𝑼,𝒃_{2})$ 构建的词汇的概率分布。softmax 函数将分数转换为概率分布。
𝑼 也是可学习的权重。实际的输出结果不是 one-hot 的,因为有很多种可能性。
卷积神经网络
由于内存的限制,语言模型不能全序列去计算当下的下一个输出,所以 RNN ”退化“ 为一个处理局部状态的神经网络。当序列数量 n 足够大时,仍然是全序列语言模型。
CNN: Convolutional Neural Networks 卷积神经网络
CNNs are good at extracting local and position-invariant patterns, by computing the representations for all possible N-gram phrases in a sentence.
Sentence: The plane is taking off.
Possible n-gram phrases:
- Bigram: The plane, plane is, is taking, taking off
- Trigram: The plane is, plane is taking, is taking off
- N-gram: …
将序列拆分出不同长度的窗格,以关注局部的序列状态。由于 RNN 反向传播路径太长,局部的 CNN 计算可以加快训练速度。
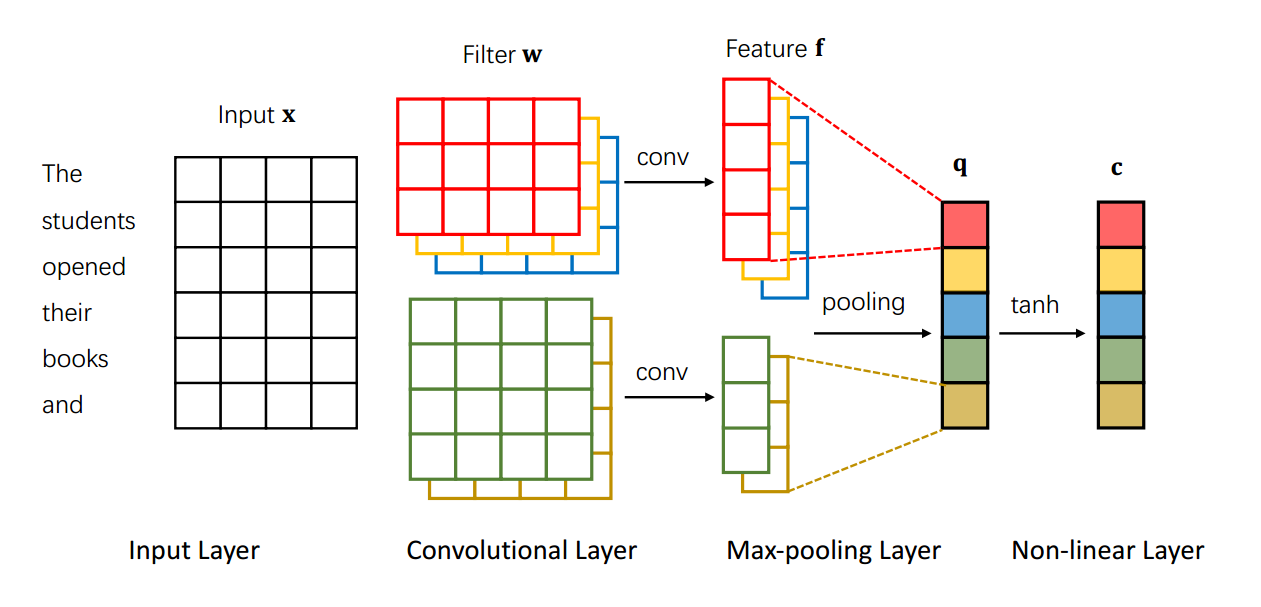
- 输入层:通过词嵌入将单词转换为输入表示 $𝐱∈R^{m×d}$,其中 𝑚 是句子的长度,𝑑 是词嵌入的维数。
- 卷积层:通过滑动卷积滤波器从输入表示中提取特征表示
- 输入表示
$$𝐱∈R^{m×d}$$ - $(j+1)-gram$ 表示,$𝐱_{i},𝐱_{i+1},…,𝐱_{i+j}$ 的连接
$$𝐱_{i:i+j}∈R^{(j+1)d}$$ - 卷积滤波器,b 是偏差项(h 是窗口大小)
$$𝐰∈R^{h×d}$$ - 卷积特征表示
$$𝐟∈R^{n-h+1}$$
- 输入表示
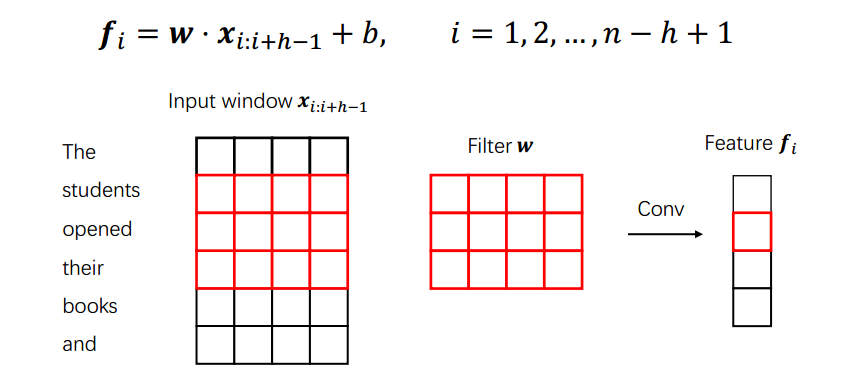
对比
用于 NLP 的神经网络模型对比:
- CNNs
- 优点:提取局部和位置不变特征
- 参数:少量参数
- 并行化:句内并行化效果更好
- RNNs
- 优点:建模长区间上下文依赖性
- 参数:更多参数(需要更多内存)
- 并行化:句子内无法并行化
seq2seq 和 transformer
Transformer 一开始是 Google 为了解决机器翻译的问题,训练速度和性能都比 RNN 好。机器翻译任务更关注长序列。
机器翻译中的 seq2seq
机器翻译(Machine Translation,MT):将文本从源语言翻译成目标语言的任务。回想一下序列到序列模型,它使用两个 RNN:
- Encoder RNN:生成源句子的表示
- Decoder RNN:基于编码生成目标句子的语言模型
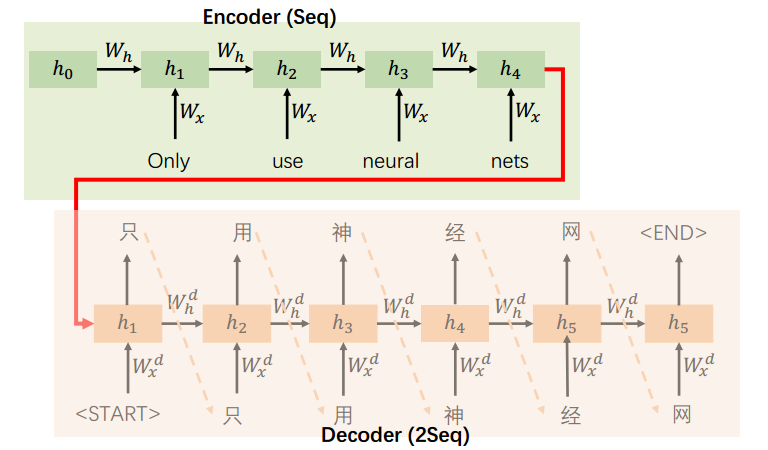
transformer
Transformer 替换了 RNN 处理序列的机制。使用 attention 的方法。RNN 处理变长序列,可以看到之前的所有输入,缺点是因为串行处理,导致计算很慢,而且 RNN 的记忆序列长度是固定的(由隐藏状态参数数量决定)。
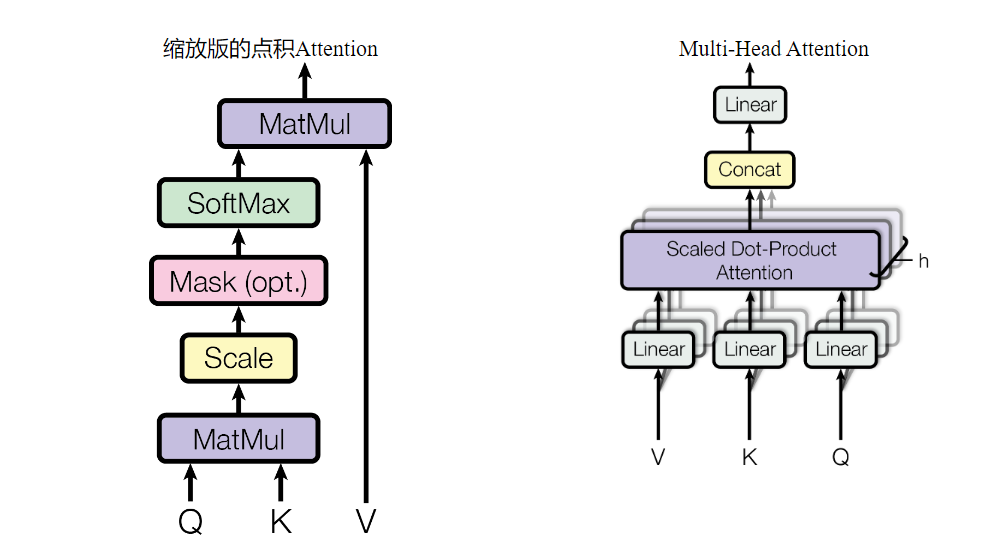
Attention 对于一个向量,映射到三个矩阵运算,Query,Key,Value,$ QK^T$ 内积计算距离,乘以缩放系数 $\frac{1}{\sqrt{d_k}}$,避免计算值过大,再通过 $softmax()$ 计算概率分布,再乘以 $V$ 得到最后的序列。
Attention 的优势:
- 矩阵计算轻量化且固定,反向传播快
- 可以处理足够大的输入
- 不像 RNN 一样固定的序列记忆数量
- RNN 的序列记忆数量取决于隐藏状态参数数量大小
- Transformer 在计算时,会“看到”前面计算的所有隐藏状态参数,输入越长,则记忆力越好,保证信息不会丢失
- Transformer 在剔除了RNN的序列处理逻辑后,加入了 feedforward 等结构,叠加形成了多层模型
$$ \bbox[,5px,border:2px solid red]
{
Attention(Q,K,V)=softmax(\frac{1}{\sqrt{d_k}}QK^T)V
}
$$
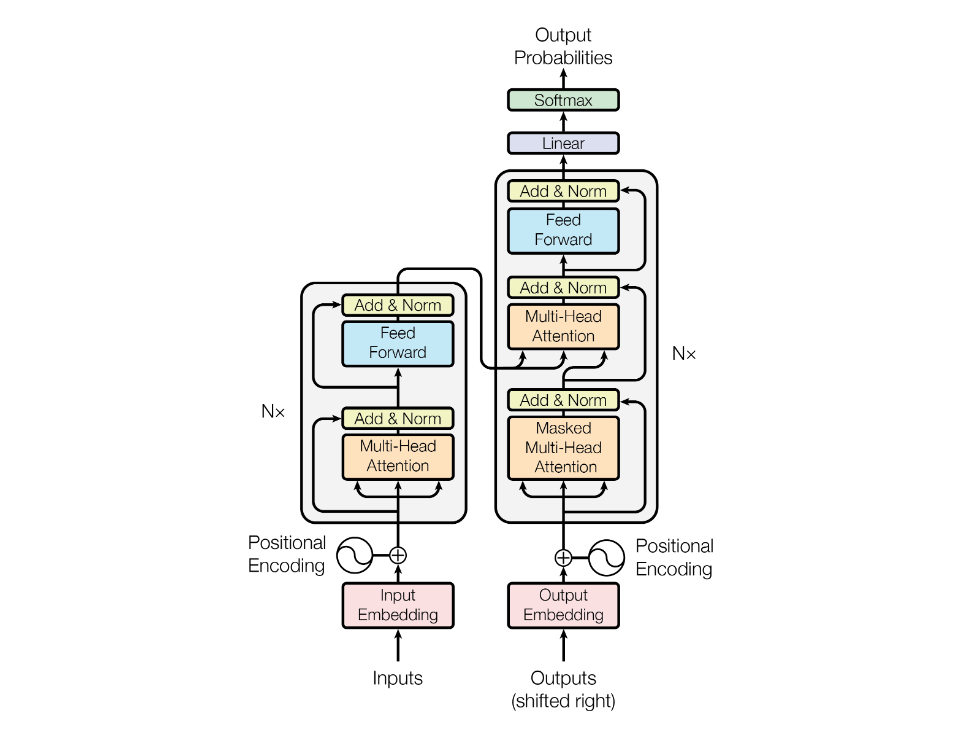
decoder-only 和 encoder-decoder
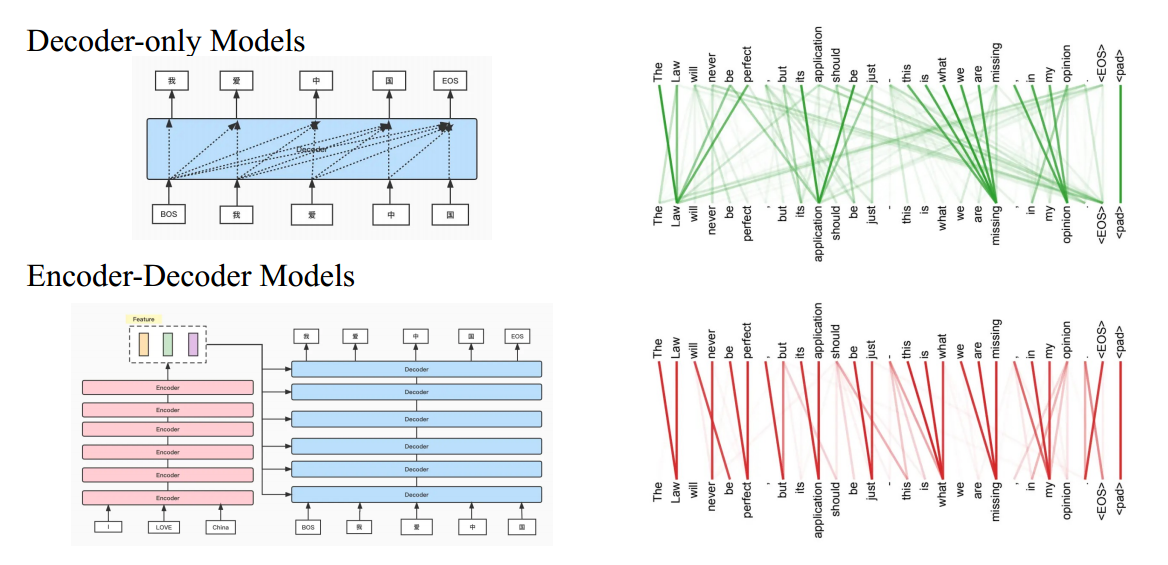
左图:目前主流是 Decoder-only,使得所有任务都变成生成任务
右图:
- 深色的线表示 Attention 的概率大
- Attention 机制看到的是一个 token 的上下文联系,不仅仅是某个 token。
3 大语言模型基础知识
- 迁移学习
- 自监督学习、预训练
- 语言建模预训练
- 预训练模型和大语言模型
迁移学习
深度学习是各类自然语言处理任务的主流框架,但它仍然面临着一些挑战:缺乏大规模监督数据、模型深度有限、泛化性能差。
- 带有人工标注的数据,为有监督数据,作为训练集,然后用测试数据作为输入,完成特定的输出任务。
- 有监督数据集成本高,模型上限低。
- 在输入数据集以外的数据,能否正常处理,表现了模型的泛化能力。即举一反三的能力。
- 预训练使模型具有通用能力,再“迁移”到具体任务上,可迁移到任务一般具备相似性。
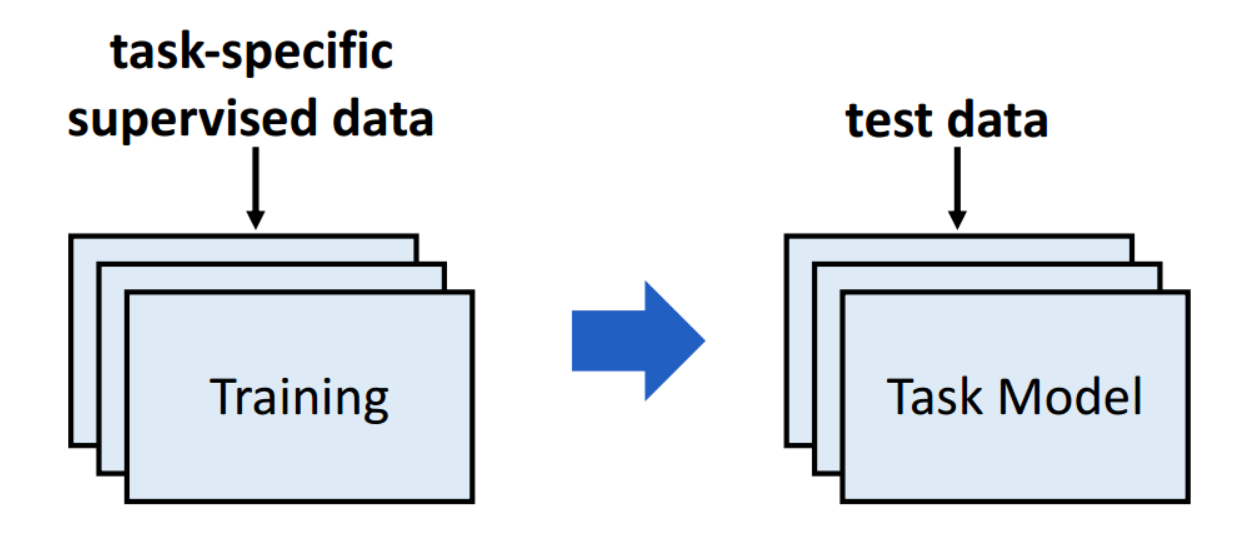
PTMs (Pre-Trained Models 预训练模型) are proposed, which are pre-trained on large-scale unlabeled data, and then be finetuned on downstream tasks, showing strong performance on various downstream tasks.
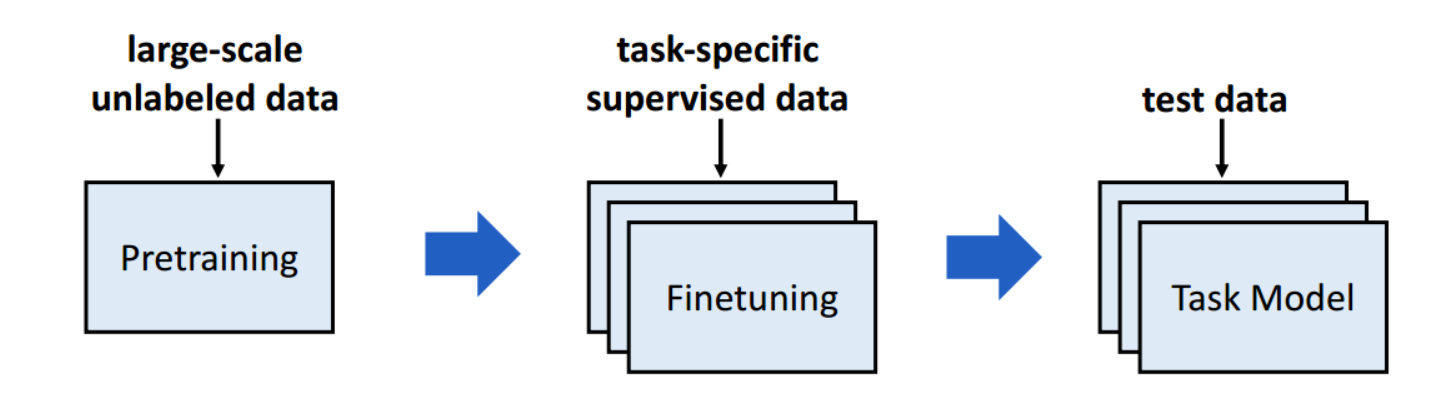
预训练-微调范式(Pretraining-Finetuning paradigm)是迁移学习(Transfer Learning)的一种形式,之前学到的能力可以迁移到新任务中。
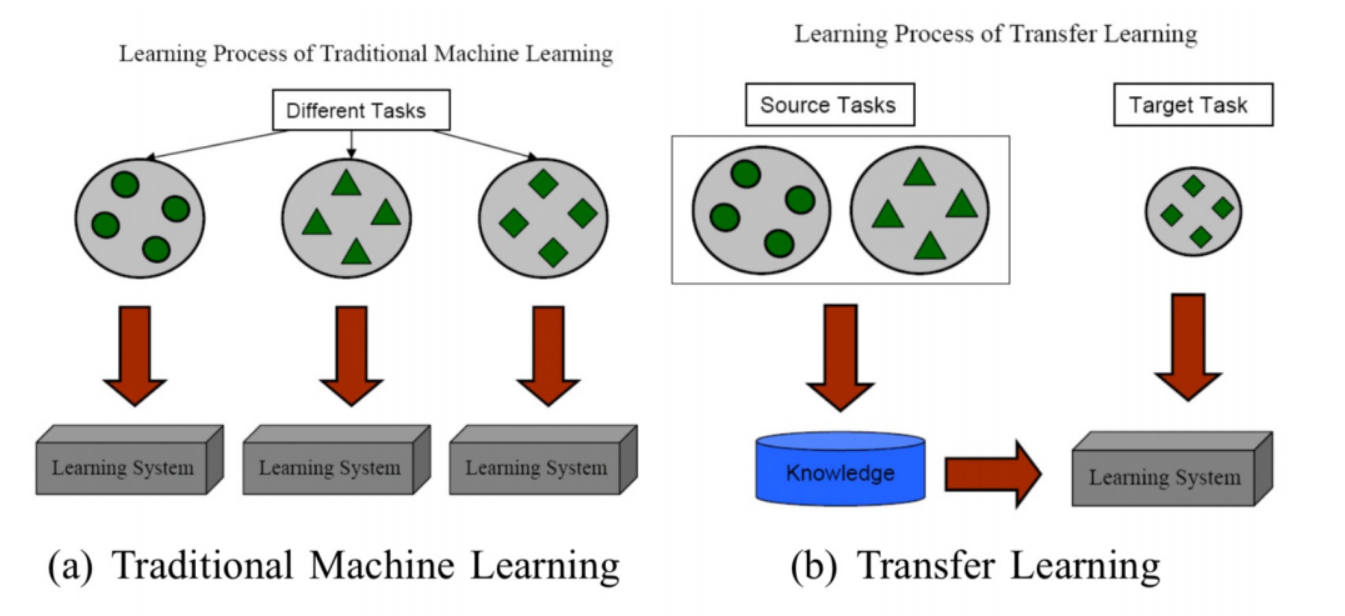
迁移学习:知识获取 => 知识迁移,包括基于特征的迁移和基于参数的迁移。
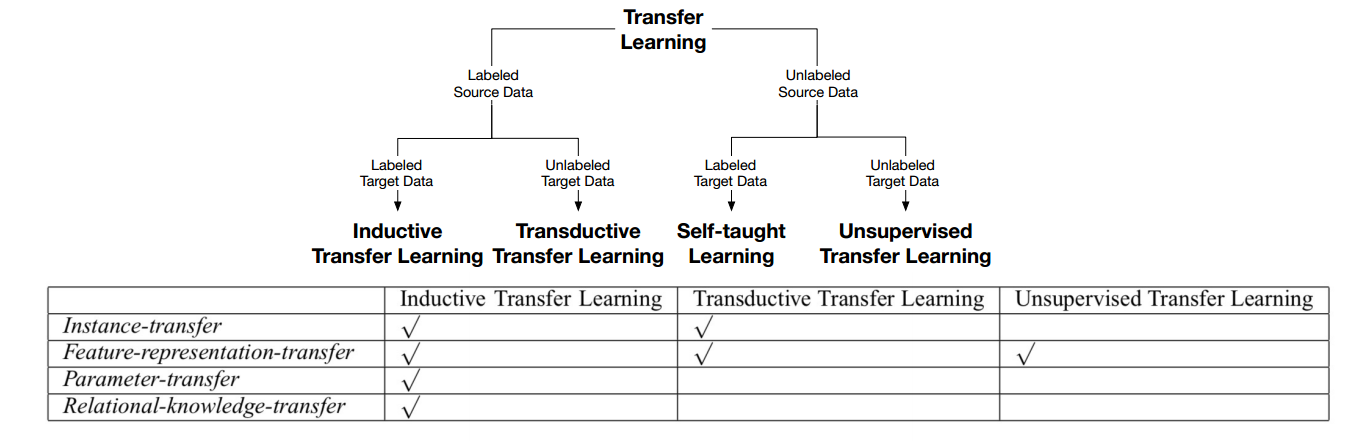
计算机视觉任务中的早期迁移学习工作:
- 在人工标记的 ImageNet 上对模型进行预训练
- 然后在下游任务上对模型进行微调
- 基于 CNN(例如 残差神经网络 ResNet)构建模型
是否可以使用未标记数据预训练模型?
- 自监督学习:从未标记数据中挖掘内部信息来训练模型
- 对比学习:最大化正例和反例之间的距离
语言建模的预训练
如何衡量文本的概率?
$$
Pr(I like deep learning) > Pr(I hate deep learning)
$$
word2vec
Word2vec 使用浅层神经网络将单词与分布式表示关联起来。它可以捕捉许多语言规律,例如:
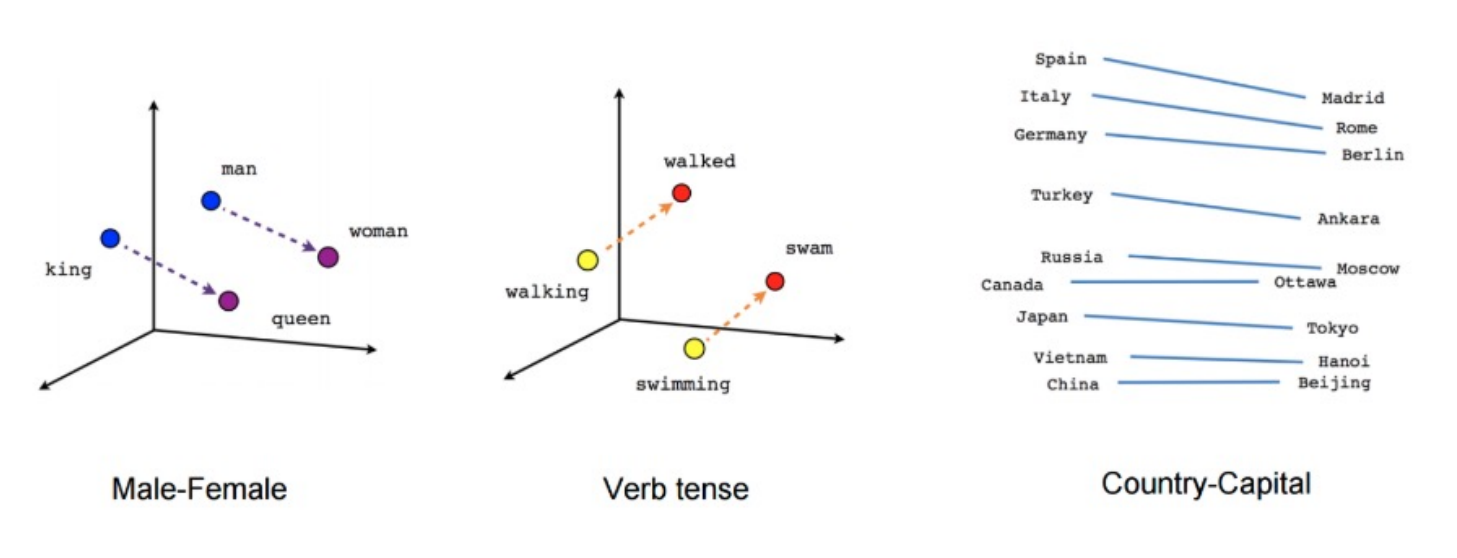
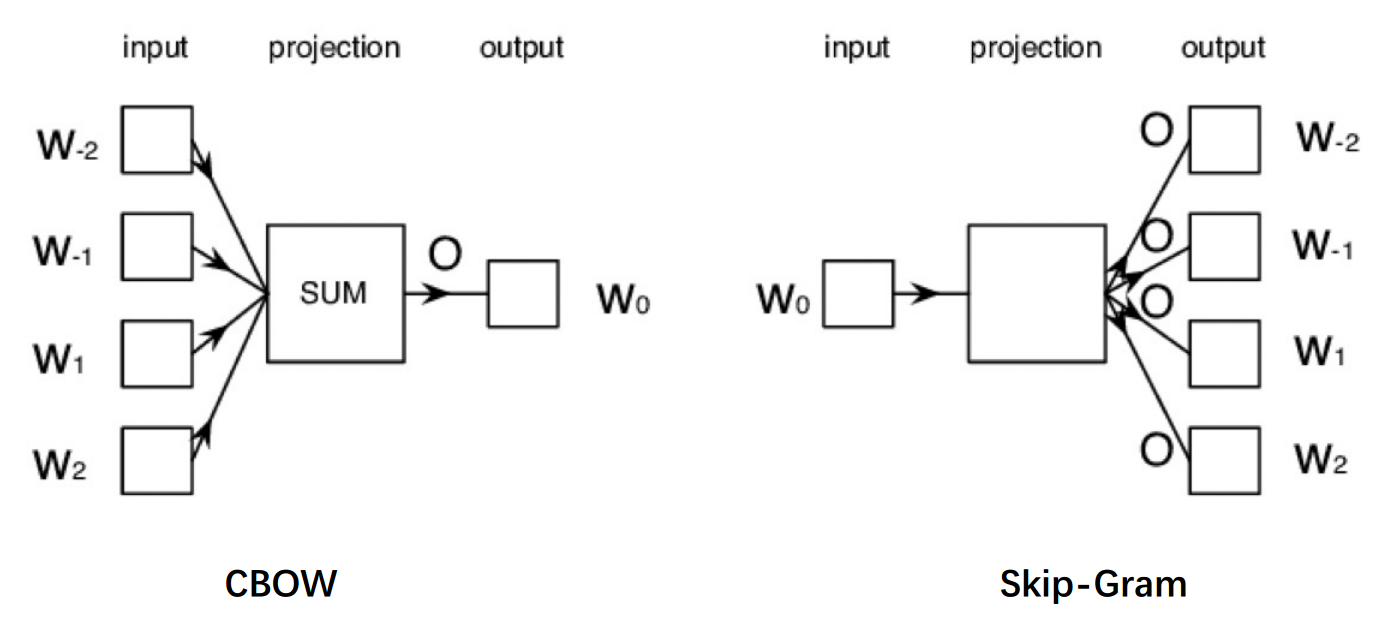
Word2vec 可以利用两种架构来生成单词的分布式表示,
- 连续词袋 (CBOW)
- 连续 Skip-Gram
Word2Vec 的挑战
- 歧义:
- 我去银行(bank)存钱。
- 我去岸边(bank)钓鱼。
- 反义词:
- 我喜欢这部电影,这部电影太糟糕了。
- 我不喜欢这部电影,这部电影太好了。
上下文相关的词语表示
在海量文本数据上对 RNN 进行预训练。RNN 模型模拟自然语言概率。此功能可以很好地迁移到下游自然语言处理任务。

上下文相关的词语表示:
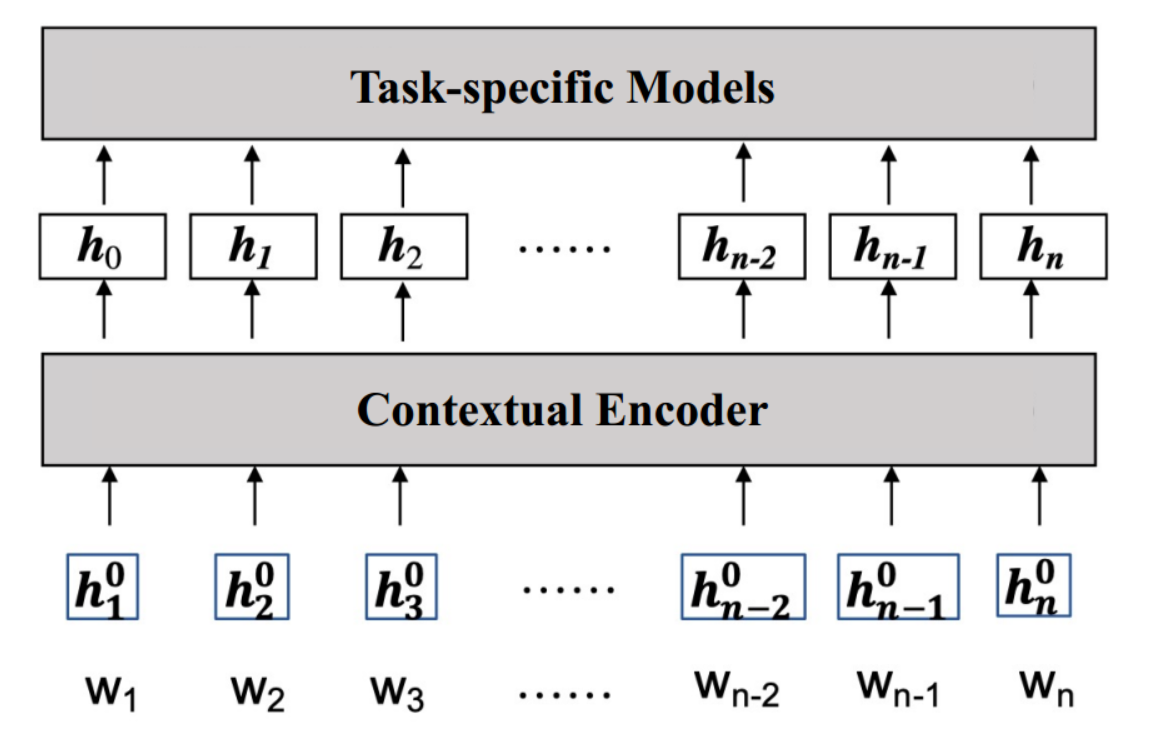
预训练模型和大语言模型
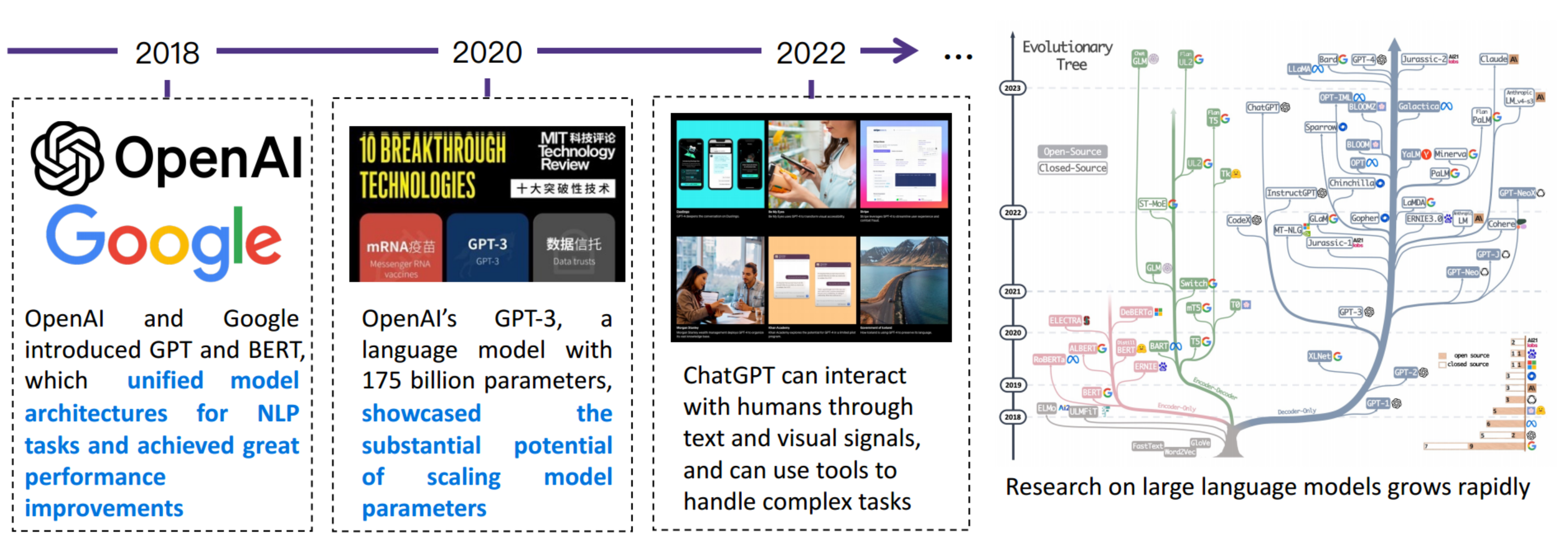
2018年,以 ELMo、BERT 为代表的预训练模型给NLP领域带来了一场革命。基于预训练模型的工作在几乎所有的 NLP 任务上都取得了巨大的突破,各类 benchmark 的结果也得到了显著的提升。

预训练模型
GLUE 上的预训练模型的结果超越了人类的水平,体现了它们的语言理解能力。
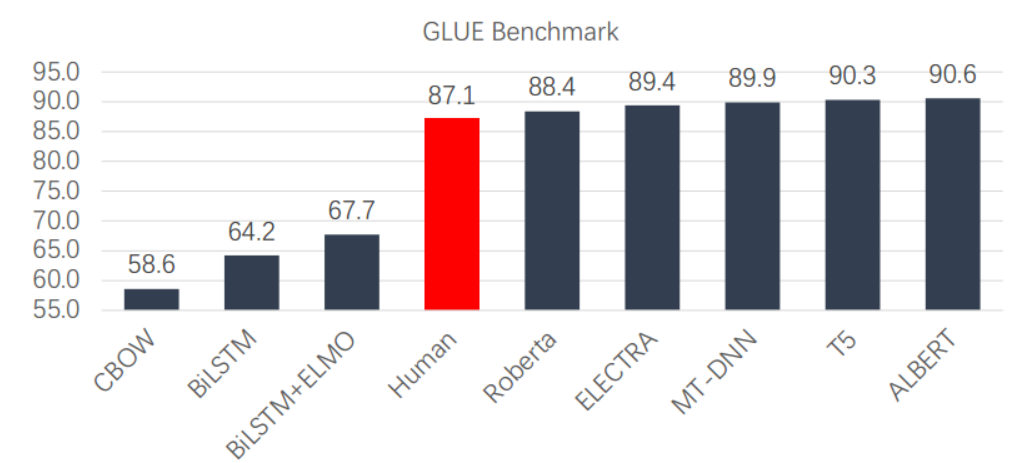
大语言模型
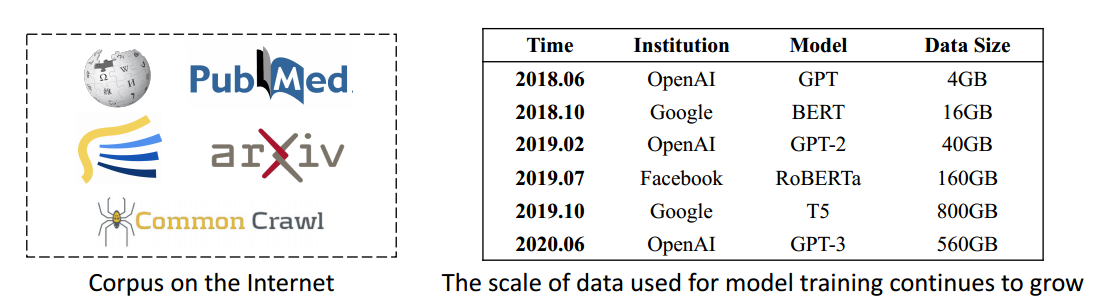
过去两年,预训练模型的规模每年增长约10倍,数据量也随之增长,计算成本也越来越昂贵。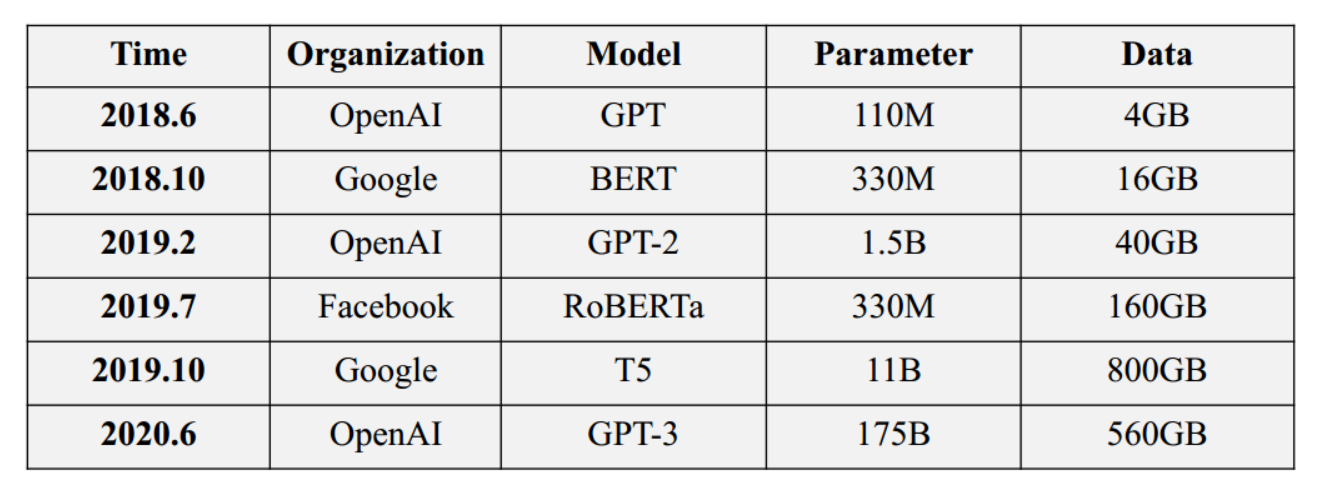
一个非常有代表性的模型是拥有1700亿(170B)个参数的GPT-3。
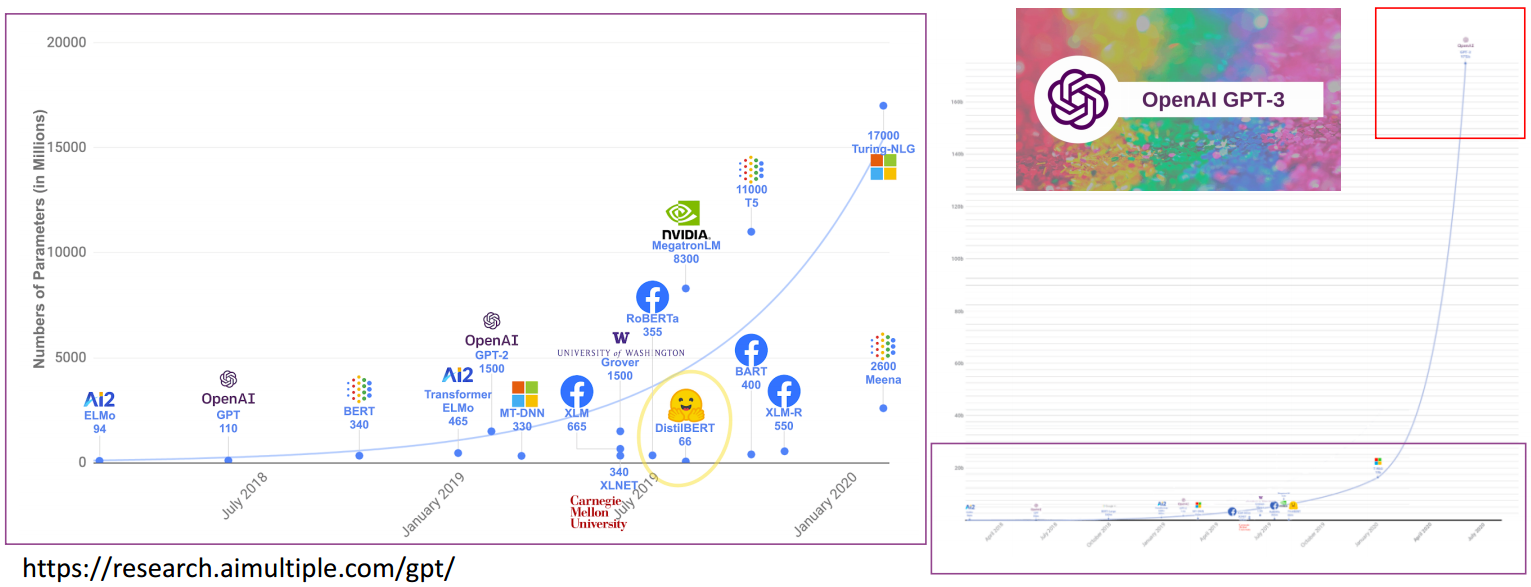
GPT-3具有一定的知识,可以进行一定的逻辑推理。

此外,GPT-3 具有强大的零次/小样本学习能力,可以执行许多任务。
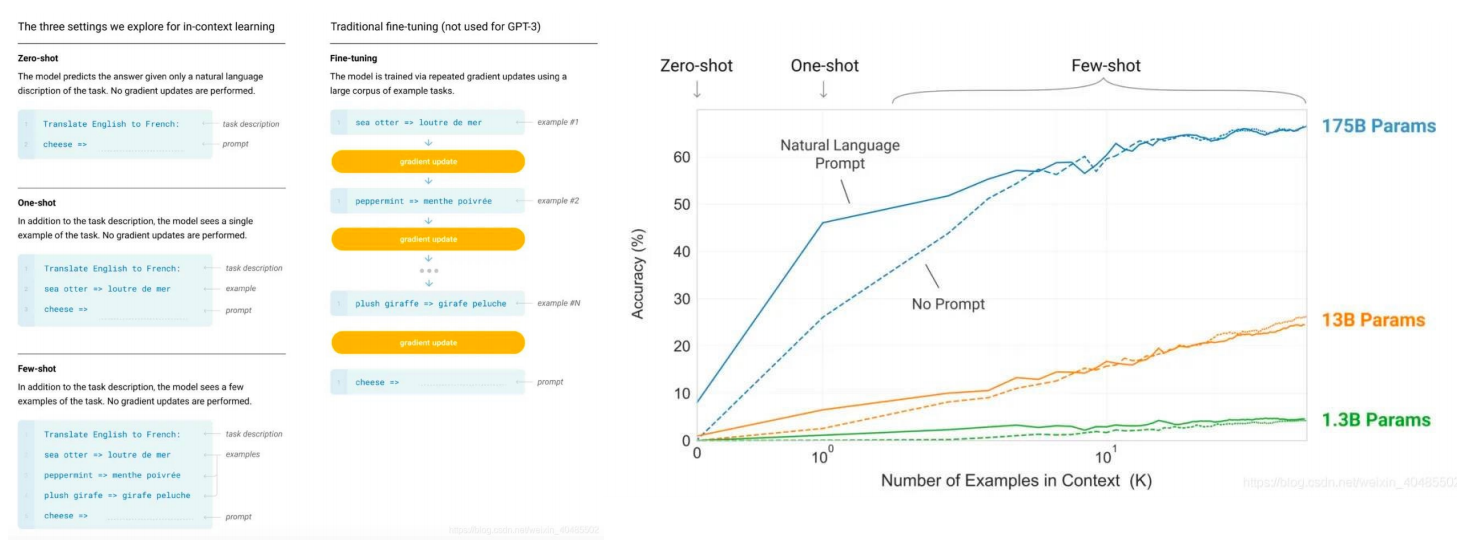
语言模型的特性和功能
大型语言模型使用下一个 token 预测任务来对大数据进行建模。学习大数据需要大量参数,训练大模型需要大量计算能力。更多的 FLOP 带来更多的功能,智能逐渐出现。
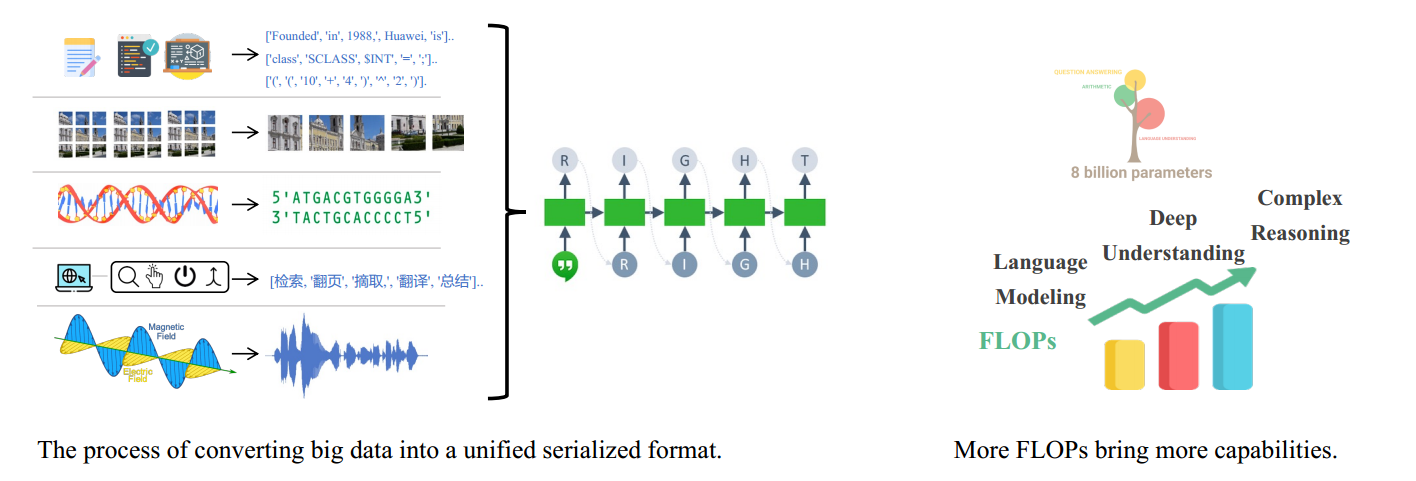
4 大语言模型的训练方法
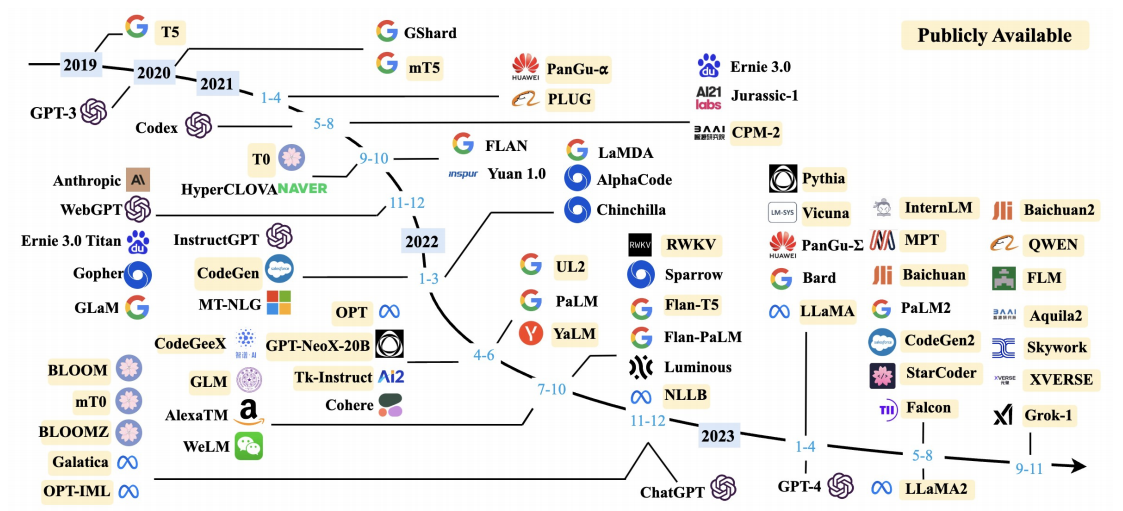
- Pre-training 预训练
- Language Modeling 语言建模
- Development of Pre-trained Language Models 预训练语言模型的开发
- Post-training 后训练
- Conventional Fine-Tuning 常规微调
- Advanced Adaptation 高级自适应
- Alignment & SuperAlignment 对齐和超对齐
大模型的普及
- 一切都可以 tokenized —— 文本、代码、图像、DNA……
- 每个 Token 都可以被学习(和推广)

tokenization
标记化将文本(或其他信息)分解为子单词(标记)
- 有多种方法来标记文本
- 标记可以通过嵌入(Embedding)进一步表示

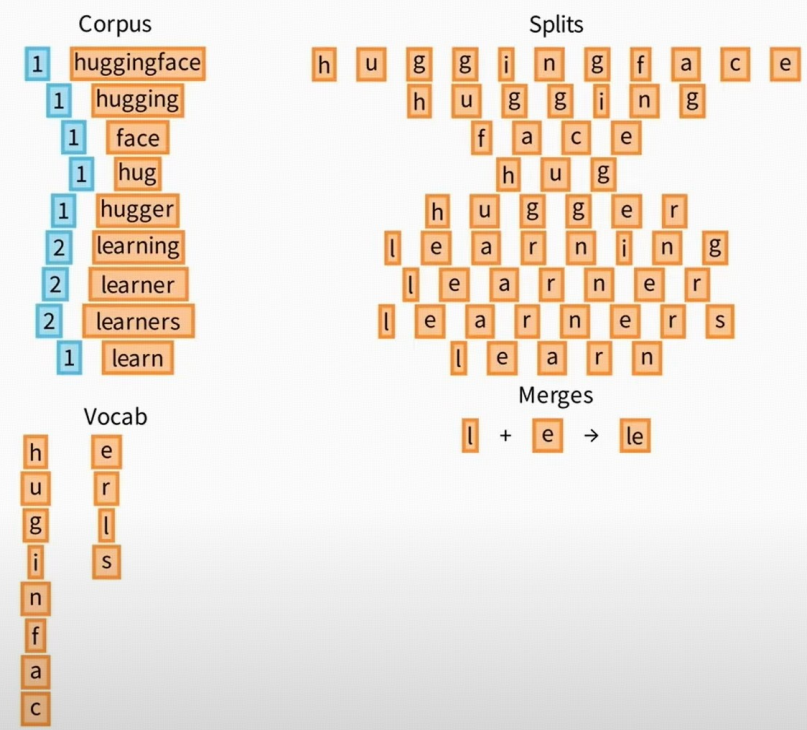
过去的预训练嵌入
- 词嵌入以上下文无关的方式应用
- 训练神经语言模型,根据句子中的前几个单词来预测下一个单词,并将其内部表示用作词向量
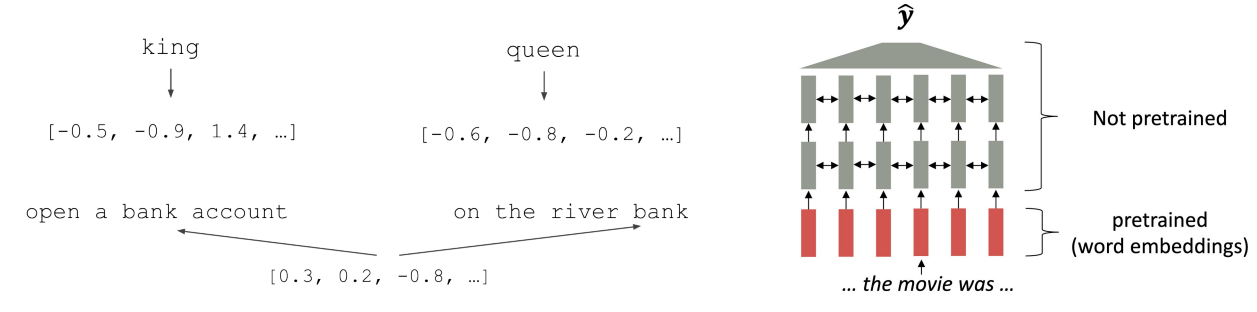
ELMo:情境化预训练从这里开始
- 架构:堆叠式 Bi-LSTM,基于 1B Word Benchmark。
- 将每层的隐藏状态组合在一起作为上下文词嵌入。
- 语境化:每个单词的表示取决于其使用的整个上下文。
- 深度:单词表示结合了深度预训练神经网络的所有层
transformer
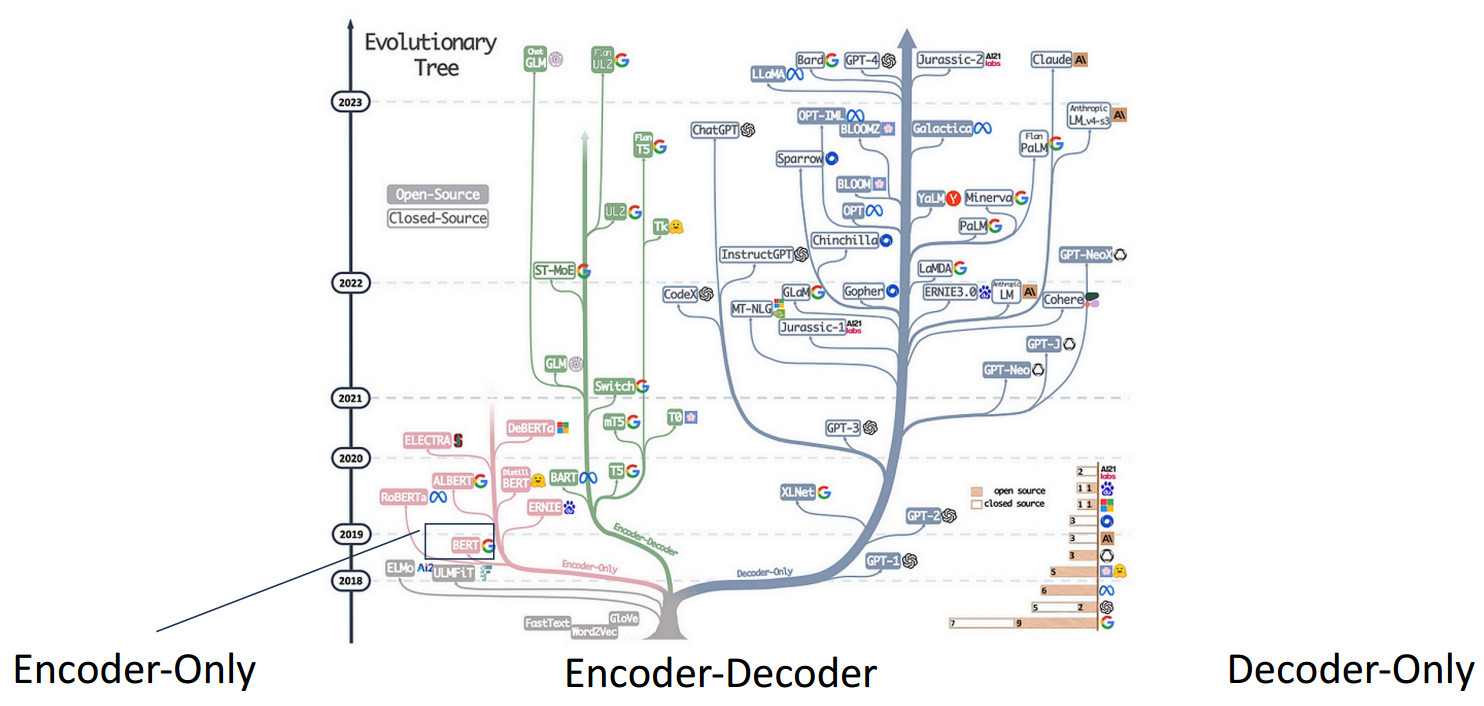
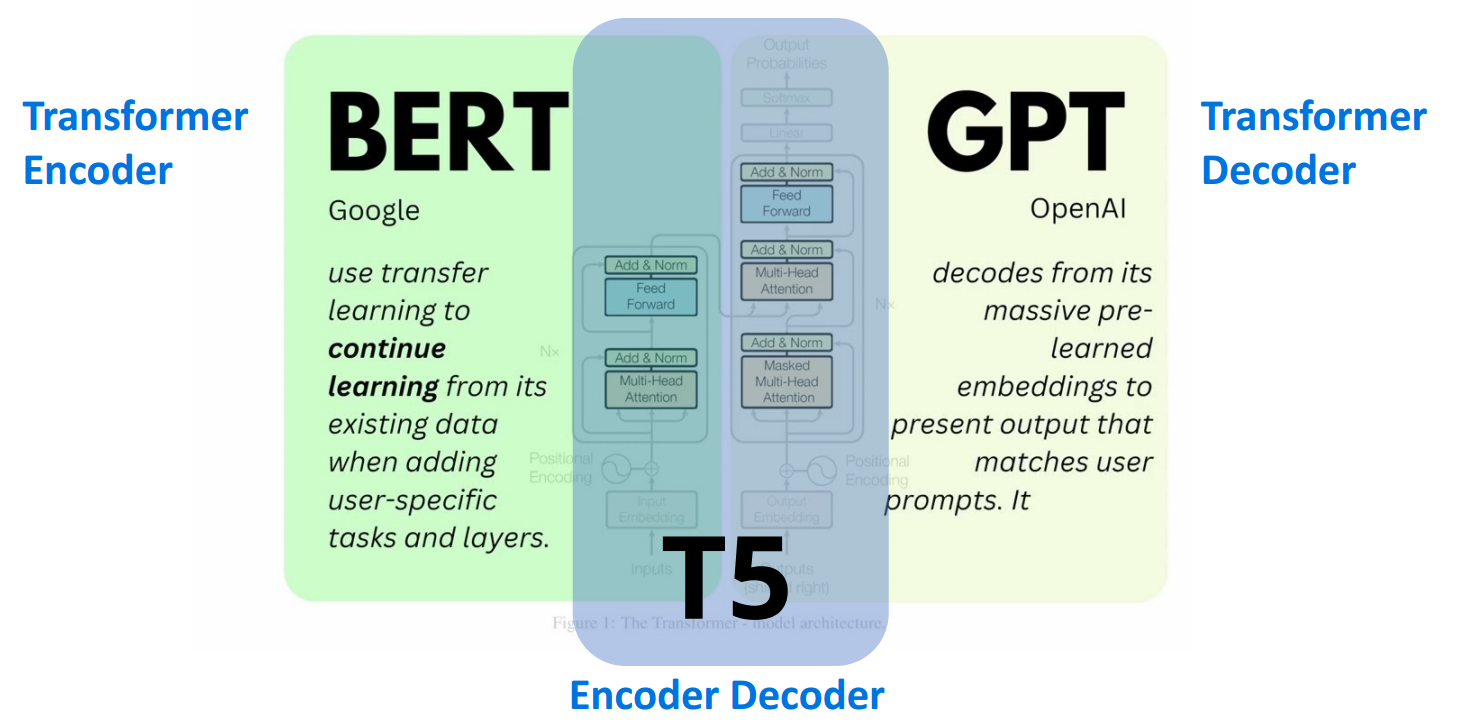
gpt
- 受到 Transformer 在不同 NLP 任务中成功的启发,GPT 是第一个基于 Transformer 预训练 PLM 的工作
- Transformer + 从左到右的 LM;对下游任务进行了微调。
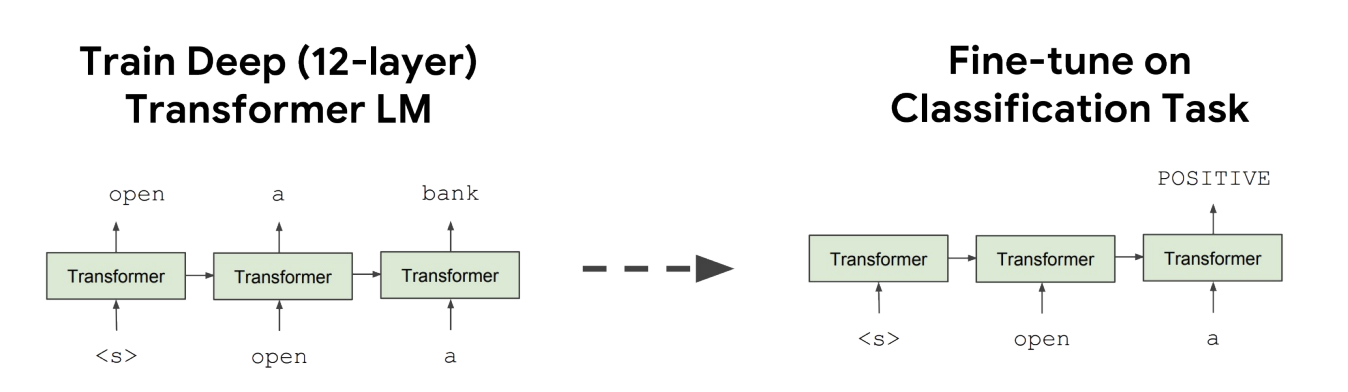
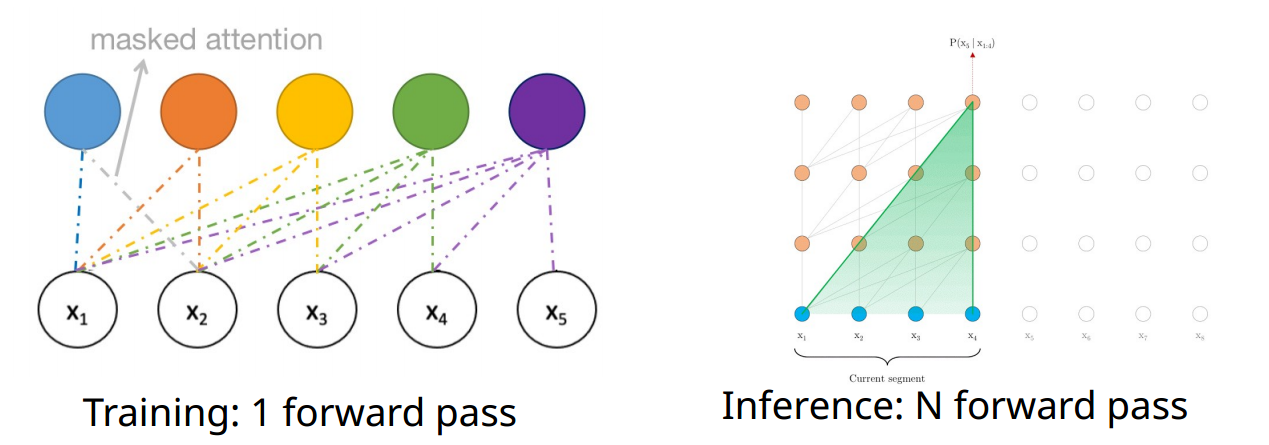
- 训练 Transformer 是高效的:我们实际上可以在一次前向传递中计算出序列中所有标记的语言建模概率。
- 注意掩码可控制哪些上下文标记在注意力计算中可见。