AMD GPU KMD 代码分析
地址:https://github.com/ROCm/ROCK-Kernel-Driver
驱动
流程示意图
flowchart TB
amdgpu_driver_load_kms --> amdgpu_device_init --> amdgpu_device_ip_early_init
subgraph amdgpu_device_ip_early_init
direction TB
amdgpu_discovery_set_ip_blocks --> amdgpu_amdkfd_device_probe
amdgpu_amdkfd_device_probe --> early_init
subgraph early_init
direction TB
uvd_v7_0_early_init --> ... --> vce_v4_0_early_init
end
end
amdgpu_device_init --> amdgpu_device_ip_init
amdgpu_device_ip_init --> sw_init
subgraph sw_init
direction TB
gmc_v9_0_sw_init --> gmc_v9_0_mc_init --> amdgpu_bo_init --> gmc_v9_0_gart_init --> vega20_ih_sw_init --> psp_sw_init --> pp_sw_init --> gfx_v9_0_sw_init --> uvd_v7_0_sw_init --> vce_v4_0_sw_init
end
amdgpu_device_ip_init --> hw_init
subgraph hw_init
direction TB
gmc_v9_0_hw_init --> psp_hw_init --> dm_hw_init --> gfx_v9_0_hw_init --> sdma_v4_0_hw_init --> vce_v4_0_hw_init
end
amdgpu_device_ip_init --> amdgpu_amdkfd_device_init --> kgd2kfd_device_init
subgraph kgd2kfd_device_init
direction TB
kfd_gtt_sa_init --> kfd_doorbell_init --> device_queue_manager_init
end
amdgpu_device_init --> amdgpu_device_ip_late_init
1 | |
队列创建
流程示意图
flowchart TB
subgraph kfdtest
direction TB
id0["HSAKMT_STATUS Create()"] --> id1["memset()"] --> id2["hsaKmtCreateQueue()
Params:
NodeId,
type,
DEFAULT_QUEUE_PERCENTAGE,
DEFAULT_PRIORITY,
m_QueueBuf->As<unsigned int*>(),
m_QueueBuf->Size(),
NULL,
&m_Resources"]
end
subgraph Thunk
direction TB
id3["handle_concrete_asic();"] --> id4["args.read_pointer_address = QueueResource->QueueRptrValue;
args.write_pointer_address = QueueResource->QueueWptrValue;
args.ring_base_address = (uintptr_t)QueueAddress;
args.ring_size = QueueSizeInBytes;
args.queue_percentage = QueuePercentage;
args.queue_priority = priority_map[Priority+3];"] --> id5["kmtIoctl(kfd_fd, AMDKFD_IOC_CREATE_QUEUE, &args)"]
end
subgraph Driver
direction TB
subgraph kfd_ioctl_create_queue
direction TB
set_queue_properties_from_user --> kfd_process_device_data_by_id --> kfd_bind_process_to_device --> pqm_create_queue
subgraph pqm_create_queue
direction TB
kfd_get_process_device_data --> init_user_queue --> kfd_process_drain_interrupts --> create_queue --> create_queue_cpsch
subgraph create_queue_cpsch
direction TB
allocate_doorbell --> init_mqd --> list_add --> increment_queue_count --> execute_queues_cpsch --> deallocate_doorbell
end
end
end
end
kfdtest --> Thunk
Thunk --> Driver
style id2 text-align:left
style id4 text-align:left
execute_queues_cpsch 流程
flowchart TB
subgraph execute_queues_cpsch
direction TB
subgraph unmap_queues_cpsch
direction TB
pm_send_unmap_queue --> pm_send_query_status --> amdkfd_fence_wait_timeout --> pm_release_ib
end
subgraph map_queues_cpsch
direction TB
subgraph pm_send_runlist
direction TB
pm_create_runlist_ib --> kq_acquire_packet_buffer --> pm_runlist_v9 --> kq_submit_packet
end
end
unmap_queues_cpsch --> map_queues_cpsch
end
1 | |
初始化
MEC,又称 Ucode,或者microcode,是 CP 的重要 firmware。
在AMD GPU的初始化过程中,CP(Command Processor)模块的初始化是一个关键步骤,它涉及加载和配置微代码(microcode)以支持指令调度、命令解析、DMA(Direct Memory Access)以及图形和计算任务的管理。以下是该流程的详细介绍,包括KMD(Kernel Mode Driver)如何将Ucode写入CP模块的步骤。
CP模块初始化概述
CP模块是AMD GPU的一个重要组件,主要负责以下任务:
- 管理和调度指令(包括图形和计算命令)
- 处理和解析命令流(Command Stream)
- 协调硬件调度单元(Hardware Scheduler)
- 管理上下文切换和线程预处理(Thread Preemption)
在初始化时,CP模块需要被配置好其微代码,以便正确解析和调度由内核驱动(KMD)或用户驱动(UMD)发送的指令流。
微代码(Microcode)的作用
微代码是CP模块执行的固件程序,它定义了CP模块如何解释并调度各种图形和计算任务。微代码通常包含以下几类指令:
- 图形指令解析和调度逻辑
- 计算指令和DMA传输的管理
- 上下文切换(Context Switching)和优先级调度策略
在KMD初始化CP时,通常会先通过驱动程序将微代码加载到GPU的内存中,然后通过特定寄存器配置微代码的执行位置。
CP模块的初始化流程
以下是一个典型的AMD GPU CP模块初始化流程:微代码加载:
- 驱动程序会将微代码文件(例如
gfx_cp.bin)加载到系统内存中。这个文件通常通过KMD或固件接口(Firmware Interface)进行获取,包含预编译好的指令集合。
- 驱动程序会将微代码文件(例如
微代码传输到GPU内存:
- 驱动程序通过MMIO(Memory-Mapped I/O)或PCIe访问机制,将微代码从系统内存传输到GPU的内存(通常是显存或CP模块本地存储器中)。
CP微代码配置:
- 驱动程序通过配置CP的寄存器来指定微代码的位置和大小。例如,通过以下寄存器进行配置:
- CP_MEC_ME1_UCODE_ADDR:指定CP微代码的加载地址。
- CP_MEC_ME1_UCODE_DATA:逐字节或逐段将微代码数据写入指定地址。
- 在配置时,通常需要先指定微代码基地址(例如显存或本地寄存器的地址),然后循环地写入微代码内容。对于CP模块,微代码加载通常采用单字(32-bit)或双字(64-bit)方式。
- 驱动程序通过配置CP的寄存器来指定微代码的位置和大小。例如,通过以下寄存器进行配置:
微代码加载确认和校验:
- 驱动程序在完成微代码写入后,会配置相关寄存器标志位以启动微代码。例如:
- 设置 CP_MEC_CNTL 寄存器的启动位(start bit)来触发CP模块执行微代码。
- 驱动程序会通过读取寄存器状态(如检查校验和寄存器)来确认微代码是否加载成功。
- 驱动程序在完成微代码写入后,会配置相关寄存器标志位以启动微代码。例如:
命令处理配置:
- 一旦微代码被成功加载和校验,CP模块会被配置为接收和解析来自KMD的图形或计算命令流。此时,KMD会配置相应的调度策略和上下文切换策略。
KMD如何写入微代码(Ucode)
KMD(Kernel Mode Driver)在进行CP模块的微代码初始化时,会采用以下具体步骤:获取微代码数据:
- 从驱动中定义的静态数组(或从设备固件库中)获取微代码的数据。微代码通常以二进制格式存在于驱动程序中,文件名可能是
gfx_cp.bin或者通过加载固件接口(Firmware Loader)动态获取。
- 从驱动中定义的静态数组(或从设备固件库中)获取微代码的数据。微代码通常以二进制格式存在于驱动程序中,文件名可能是
设置CP微代码写入地址:
- 配置
CP_MEC_ME1_UCODE_ADDR或CP_ME_RAM_WADDR等寄存器,以指向CP模块内部RAM或GPU内存中微代码的目标写入地址。
- 配置
逐字写入微代码数据:
- 使用循环结构逐字(word by word)地将微代码数据写入
CP_MEC_ME1_UCODE_DATA或CP_ME_RAM_DATA寄存器。每次写入后,地址指针会自动递增。
1
2
3
4for (i = 0; i < microcode_size; i++) {
WREG32(CP_ME_RAM_WADDR, i); // 设置CP RAM的写入地址
WREG32(CP_ME_RAM_DATA, microcode_data[i]); // 写入微代码数据
}- 使用循环结构逐字(word by word)地将微代码数据写入
启动微代码执行:
- 配置
CP_RB_CNTL或CP_MEC_CNTL寄存器,以启动CP模块开始执行微代码。
- 配置
校验加载状态:
- 驱动程序通过读取
CP_ME_STATUS或类似的状态寄存器来确认微代码是否正确启动和执行。
- 驱动程序通过读取
关键寄存器的说明
在CP模块微代码加载过程中,以下寄存器通常需要配置:- CP_ME_RAM_WADDR:指向微代码在CP模块中的起始地址。
- CP_ME_RAM_DATA:用来写入微代码的具体数据。
- CP_MEC_CNTL:控制CP模块的启动和停止。
- CP_RB_CNTL:用于配置Ring Buffer和命令调度策略。
- CP_MEC_ME1_UCODE_ADDR / CP_MEC_ME1_UCODE_DATA:配置MEC(Micro Engine Controller)微代码的加载地址和数据。
AMD GPU的CP模块初始化涉及复杂的微代码加载和配置过程。KMD通常通过内核模式驱动程序将微代码从系统内存传输到GPU内存中,再通过配置相关寄存器来启动微代码的执行。正确的微代码加载和配置对于GPU指令解析和任务调度至关重要。在实际开发中,可以使用调试工具(如amdgpu-pro或gdb)来检查CP模块的寄存器状态,以确保微代码正确加载并成功运行。
1 | |
内存管理
常见概念介绍:
1 | |
struct amdgpu_gmc 是 AMDGPU 驱动中用于表示 AMD GPU 全局内存控制器(Global Memory Controller, GMC)配置的结构体。该结构体主要负责管理 GPU 内存的各种配置和状态,包括 VRAM(视频内存)、GART(图形地址重映射表)、AGP(加速图形端口)等。每个字段都有其特定用途,用于处理 GPU 内存分配、访问、和故障管理等任务。
- 内存孔径字段(Aperture Fields):
- aper_base 和 aper_size:
- 代表从 CPU 角度看到的帧缓冲区(Frame Buffer, FB)孔径的物理地址和大小。这与 GPU 视角的地址不同,后者由
vram_start/vram_end表示。
- 代表从 CPU 角度看到的帧缓冲区(Frame Buffer, FB)孔径的物理地址和大小。这与 GPU 视角的地址不同,后者由
- vram_start 和 vram_end:
- 定义 GPU 本地 VRAM 的起始和结束地址。
- fb_start 和 fb_end:
- 描述 Frame Buffer 区域的起始和结束地址。在多 GPU 设置中(例如 XGMI 集群),该区域覆盖所有 GPU 的显存,每个 GPU 可能会有不同的偏移量。
- agp_start、agp_end、agp_size:
- 指定 AGP(加速图形端口)孔径,主要用于早期 GPU 或集成 APU 的内存访问。
- gart_start、gart_end、gart_size:
- 描述 GART(图形地址重映射表)孔径,用于访问分页的系统内存(例如在虚拟内存场景下)。
- aper_base 和 aper_size:
- 内存大小和属性字段:
- mc_vram_size:
- 指定从内存控制器(Memory Controller, MC)视角看到的 VRAM 大小。
- visible_vram_size:
- 定义 CPU 可见的 VRAM 大小,这可能小于或等于
mc_vram_size。
- 定义 CPU 可见的 VRAM 大小,这可能小于或等于
- real_vram_size:
- 表示 GPU 实际可用的 VRAM 总大小。
- vram_width:
- 表示 VRAM 的总宽度(位宽),影响显存带宽。
- mc_vram_size:
- 故障处理(Fault Handling)字段:
- vm_fault:
- 描述虚拟内存(VM)故障的来源。
- vm_fault_info 和 vm_fault_info_updated:
- 存储虚拟内存故障的详细信息,并跟踪故障信息的更新。
- fault_ring:
- 用于记录和处理 GPU 内存故障的环形缓冲区。
- vm_fault:
- 孔径共享和地址转换字段:
- shared_aperture_start 和 shared_aperture_end:
- 多设备共享的孔径范围,用于 XGMI 等多 GPU 互联场景。
- private_aperture_start 和 private_aperture_end:
- 该设备独有的孔径范围。
- translate_further:
- 布尔类型,指示地址转换是否需要进一步进行。
- shared_aperture_start 和 shared_aperture_end:
- 固件和配置信息:
- fw 和 fw_version:
- 指向 MC 固件和固件版本号。
- ecc_status:
- 记录 ECC(错误纠正码)状态,用于检查显存中是否发生了位错误。
- tmz_enabled:
- 指示是否启用了 TMZ(受信内存区),这是一种用于保护特定内存区域的安全功能。
- fw 和 fw_version:
- 锁和同步字段:
- invalidate_lock:
- 自旋锁,用于保护内存无效化操作的并发访问。
- invalidate_lock:
- 页表配置字段:
- vmid0_page_table_block_size 和 vmid0_page_table_depth:
- VMID0 页表的配置设置,决定页表的粒度和深度。
- vmid0_page_table_block_size 和 vmid0_page_table_depth:
- 多 GPU 和互联支持字段:
- xgmi:
- 表示 XGMI(高速 GPU 互联)结构体,用于管理多 GPU 的互联配置和状态。
- xgmi:
- 其他字段:
- sdpif_register:
- SDPIF(串行数据处理接口)寄存器,用于与其他组件通信。
- noretry 和 noretry_flags:
- 内存事务重试机制的控制字段。
- sdpif_register:
amdgpu_gmc 结构体被设计用于详细描述 AMD GPU 内存的各个部分,包括显存、系统内存和地址重映射表的配置。它可以管理不同 GPU 之间的内存地址空间,并为不同内存类型分配特定的地址范围。此外,它还包含故障处理字段以记录内存访问错误,并且支持多 GPU 的内存地址转换和互联配置。这些字段确保 GPU 内存管理的高效性和可靠性,是实现高性能计算和图形处理的基础。
DRM 是 Linux 内核中的一个子系统,负责管理图形硬件设备。它为图形处理器(GPU)和显示设备提供低级别的图形资源管理和硬件加速支持。主要用于显示服务器(如 X11 或 Wayland)和图形库(如 Mesa 3D)与 GPU 之间的交互。
- 内存管理:
- DRM 管理 GPU 使用的显存(VRAM)和系统内存(GTT)。它处理内存的分配、映射和释放,确保 GPU 和 CPU 可以高效地共享和使用内存资源。
- 上下文管理:
- DRM 支持图形上下文的创建和管理,使多个图形应用程序可以同时运行并独立渲染其内容。这对于多任务处理和确保应用程序之间的隔离至关重要。
- 图形硬件控制:
- DRM 直接与图形硬件(如 GPU、显示控制器)交互,执行低级别操作,如显示模式设置(Mode Setting)、 Frame Buffer 管理(Framebuffer Management)、硬件加速命令的排队和执行等。
- 安全和访问控制:
- DRM 提供了对图形硬件的安全访问控制,确保只有授权的应用程序能够访问 GPU 资源。这在多用户环境中非常重要。
- 显示管理:
- DRM 包含了显示管理的功能,包括管理多个显示器、设置显示模式(分辨率、刷新率等)、处理热插拔事件等。它为图形栈中的更高级别组件(如 X Server 或 Wayland Compositor)提供了统一的接口。
DRM 的组件
- DRM 驱动程序:
- 这是特定于硬件的内核模块,负责与特定的 GPU 和显示硬件交互。每个支持 DRM 的 GPU 都有一个相应的 DRM 驱动程序,例如
amdgpu(AMD GPU)、i915(Intel GPU)、nouveau(NVIDIA 开源驱动)等。
- 这是特定于硬件的内核模块,负责与特定的 GPU 和显示硬件交互。每个支持 DRM 的 GPU 都有一个相应的 DRM 驱动程序,例如
- GEM (Graphics Execution Manager):
- 这是 DRM 的一部分,负责内存对象的管理,特别是图形缓冲区的分配、映射和释放。
- KMS (Kernel Mode Setting):
- KMS 是 DRM 的一个子系统,用于在内核中设置显示模式(分辨率、颜色深度、刷新率等),而不是由用户空间应用程序设置。KMS 确保显示管理的安全性和稳定性,尤其是在多用户系统中。
DRM 的实际应用
在 Linux 系统中,DRM 是现代图形栈的核心组成部分。它提供了 GPU 资源的底层管理,支持 OpenGL、Vulkan 和其他图形 API 的硬件加速,确保图形应用程序能够高效运行。显示服务器如 X11 和 Wayland,图形库如 Mesa 3D,都依赖于 DRM 提供的功能来与 GPU 进行交互。
TTM 一个内存管理子系统,最初由 Tungsten Graphics 开发,目的是为 Linux 内核中的图形设备提供统一的内存管理。TTM 主要处理显存(VRAM)和系统内存(GART 或者系统RAM)之间的数据交换。它可以动态地管理和分配这些内存区域,支持显卡的高效使用。TTM 具有以下几个关键功能:
- 内存管理:为图形硬件分配内存,支持在显存和系统内存之间的动态切换。
- 分页:在显存不足的情况下,TTM 允许将一些内存页面从显存转移到系统内存,从而腾出显存空间。
- 地址映射:通过使用页表和其他映射技术,TTM 可以将物理内存映射到 GPU 可访问的虚拟地址空间。
GEM 是 Linux 内核中用于图形内存管理的一个框架,特别是用于与图形处理单元(GPU)交互。GEM 主要由 Intel 为其 i915 DRM 驱动程序开发,但后来被其他驱动程序采用或借鉴,用于管理 GPU 上的图形内存。
- 图形内存对象管理:
- GEM 负责分配、管理和释放 GPU 使用的图形内存对象。这些对象可以包括缓冲区(例如 Frame Buffer )、纹理、顶点缓冲区等,这些都是 GPU 进行图形渲染的基础。
- 内存映射:
- GEM 允许用户空间程序将 GPU 内存映射到 CPU 地址空间。这意味着用户空间程序可以直接访问和修改 GPU 内存内容,例如更新纹理数据或将渲染结果从 GPU 传输回 CPU 进行后续处理。
- 同步与缓冲区共享:
- 在一个系统中,多个进程或线程可能需要访问同一块 GPU 内存。GEM 提供了同步机制,确保这些访问是安全且有序的。
- GEM 还允许共享缓冲区对象,这意味着不同的进程或 GPU 阶段可以共享和重用相同的图形内存对象,提高资源利用率和性能。
- 用户空间接口:
- GEM 提供了一组 ioctl(输入输出控制)接口,供用户空间程序调用。这些接口包括内存对象的创建、销毁、映射和同步操作等,使得用户空间程序能够与内核中的 GEM 模块交互,管理 GPU 内存。
- 调度与执行管理:
- GEM 在某些情况下也负责调度图形命令的执行,确保 GPU 可以高效地处理多个渲染任务。它通过管理图形命令流和确保内存对象的可用性来优化 GPU 的使用。
GEM 的引入极大地简化了 GPU 内存管理,使得图形应用程序可以更容易地管理 GPU 资源。通过提供一个通用的内存管理框架,GEM 使得不同的 GPU 驱动程序可以更一致地管理内存,减少了在不同硬件和驱动程序之间进行移植时的复杂性。在 Linux 内核中,除了 GEM 之外,还有其他用于 GPU 内存管理的机制,例如 TTM(Translation Table Maps)。TTM 是另一个内存管理框架,主要由 AMD 开发,并在一些开源驱动中使用。
- GEM vs. TTM:
- GEM:较简单,适用于较轻量级的图形内存管理任务,特别是在资源管理需求较低的环境中。
- TTM:更复杂,支持更高级的功能,如内存分页和交换,更适合需要大量内存管理的高性能图形应用程序。
一些 GPU 驱动程序可能会基于这两者的组合来实现最优的内存管理方案。
ROCm 中的 SVM 实现主要存在于 Thunk 中的用户模式下。分配内存时,Thunk 使用 mmap (…, PROT_NONE, …) 为内存分配虚拟地址空间。GPU 可以处理 48 位虚拟地址。缓冲区应映射到主机(如果它是主机可访问的缓冲区)和所有适用 GPU 上的该虚拟地址。
KFD 内存分配 ioctl 有一个用于虚拟地址的参数 kfd_ioctl_alloc_memory_of_gpu_args.va_addr。也就是说,Thunk 应该在要求 KFD 分配内存之前分配虚拟地址空间。KFD 在分配时将虚拟地址与内存关联起来。内存的未来映射应该使用该虚拟地址。如果适用,主机映射由 Thunk 使用 mmap(va_addr, …, MAP_FIXED, …) 完成,在第一个参数中指定先前分配的虚拟地址。
通过 ROCm API 分配的内存应映射到所有设备(主机和目标)上的相同虚拟地址。可以在设备上使用相同的指针来引用相同的内存。包含指针的数据结构可以在设备之间共享。
- MC 地址和 GPU 的物理地址:在为 GPU 编写驱动程序代码时,区分 MC(GPU 的内存控制器)和物理地址非常重要。GPU 物理地址从零开始,一直到最大视频内存大小。另一方面,MC 地址具有 48 位地址空间。内存孔径地址范围寄存器大多在 MC 地址空间中定义。通过定义这些寄存器的值,可以确定虚拟内存地址空间。
- F400000000 MC 地址在 VBIOS 中定义,当 GPU 自行启动时,应将该值写入寄存器 MC_VM_FB_LOCATION_BASE,驱动程序将该值读出为“系统定义值”,并且该值应该是预定义的。因此,该值不是 GPU 硬件中的硬编码值,您可以根据需要更改该值。
- 如何根据 MC 地址计算 GPU 的物理地址,可以按照以下公式计算物理地址:FB 的物理地址 = (McAddr - ‘FB aperture start address’) + PHYS_FB_OFFSET
- McAddr:在本例中为 MC 地址 F4_0000_0008。
- FB aperture start address:由寄存器 MC_VM_FB_LOCATION_BASE 定义的 F4_0000_0000
- PHYS_FB_OFFSET:它定义了 UMA 地址中视频内存的物理偏移量,因此在独立 GPU 中它应始终为 0。
- 因此,您可以得到 (F4_0000_0008) 的物理地址为 (F4_0000_0008 – F4_0000_0000) + 0 = 0x8
在填充页表的时候需要用到物理地址来组成PTE和PDE,所以了解如何计算物理地址很重要,但请注意有些寄存器是定义在MC地址中的,有些是定义在物理地址中的,不要混淆。
系统孔径(Aperture):系统孔径由两部分组成, Frame Buffer 孔径和 AGP 孔径。大多数情况下,系统孔径与 Frame Buffer 孔径一致,即“本地 Frame Buffer ”或“视频内存”。孔径由两个寄存器“mmMC_VM_SYSTEM_APERTURE_LOW_ADDR”和“mmMC_VM_SYSTEM_APERTURE_HIGH_ADDR”定义。
MC 地址布局不是固定的,它实际上取决于使用情况和不同的平台。对于 Linux,地址布局有两个孔径,系统孔径和 Gart 孔径。
- 系统孔径从 F400000000 开始,到视频内存的最大大小结束。
- Gart 孔径目前定义在系统孔径之后,但同样,这不是硬件定义的值,您可以根据需要更改布局。您可以在“孔径”以外的任何地方定义,并且不要与其他孔径重叠。
GPU MC 地址空间由两部分组成,高位部分(0xFFFF_8000_0000_0000, 0xFFFF_FFFF_FFFF_FFF),低位部分(0x0000_0000_0000_0000, 0x0000_7FFF_FFFF_FFFF),范围由 48 位地址空间第 47 位的有符号扩展定义,当第 47 位 == 0 时,可以将 0 扩展至 64 位,并应获得低位部分的上限,当第 47 位 == 1 时,可以将 1 扩展至 64 位,并应获得高位地址的下限。这两部分之间的地址称为“洞”,当 GPU 接收到洞内的任何地址时,它都是无效地址。
“Memory Address Space.xls”中引用了 Remote GPU FB 孔径,这是 VBIOS 和 SYSTEM BIOS 中额外支持在 gpu 中导出“Large-Bar”的,“Large-Bar”是指主机可以访问本地 Frame Buffer 的概念,这意味着 PCIE bar 空间是 64bit,系统可以分配一个覆盖本地 Frame Buffer 的地址空间。在这种模式下,GPU 可以通过 PCIE 相互访问,因为本地 Frame Buffer 对彼此是可见的。
GART 页表 在Linux开源驱动中,Gart表位于“可见内存”中。Gart表是一级页表。PAGE_TABLE_DEPTH定义为实际级别减一。
但有一个例外,这就是“LDS孔径”和“私有(临时)孔径”,有配置寄存器来指定这两个孔径,因此在计算着色器中,可以通过“FLAT*”指令访问这两个孔径。 分配给“LDS孔径”和“私有孔径”一部分的“洞”内的地址可以直接在“FLAT*”指令中使用,GPU可以通过该地址访问LDS或私有孔径。
GPUVM 使用模型 在 GPU 中,有 16 个称为 VMID 的 vm 域,VMID0 称为“系统域”,只有内核模式驱动程序可以使用 VMID0,它被配置为“gart 模型”,但其他 VMID 都暴露给用户模式驱动程序,从使用模型来看,VMID1 到 VMID15 是相等的。
虽然 GPU 是可配置的,但您可以为每个 VMID 分配不同的 vm 空间,但通常情况下,您会平等地配置其余 15 个 VMID。
Frame Buffer 用于显示,并且 gart 表必须在内部可见,固件则不是,固件应在驱动程序初始化 PSP 模块时上传到专用 ROM 上。 “VF 可见 Frame Buffer ”,VF 指的是虚拟功能,这是虚拟化中的一个概念。
“HDP”代表“主机数据路径”,它是主机在不知道 Frame Buffer 中实际内存布局的情况下访问 Frame Buffer 的方式。
VMID使用及分配策略 除0以外的VMID被视为平等,在开源linux驱动中,VMID1~VMID7分配给图形使用,VMID8~VMID15分配给计算使用,但这不是硬件限制,您可以重新定义使用。
页表级别也可以从1级到4级配置,所以也取决于使用情况,在Linux开源驱动中,您可以为每个VMID分配64GB的虚拟地址,因为如果覆盖太大的虚拟空间,页表将非常大,从而消耗视频内存。
所以,综上所述,VMID0是为启用GART表而设计的系统域,页表是一级,GART空间的大小是可配置的。 VMID1~VMID15 是用户模式虚拟机,每个虚拟机都有 64GB 的虚拟内存空间,同样,这是根据使用情况可配置的,gfx 驱动中是 64GB,但是 Rocm 驱动从 rocm 2.0 开始为用户启用了整个 48 位虚拟内存空间。用户模式驱动可以分配本地 Frame Buffer 或 gart 空间,更新到 PTE 中。
页表中有两种类型的块:
- 页目录块 (PDB)
- 页表块 (PTB)
在这些类型的块中,有两种类型的条目:
- PDB 中的页目录条目 (PDE)
- PTB 中的页表条目 (PTE) 页表由一定数量的级别构成,最底层是页表块,其上每一级都是页目录块。
PDB 由一组 64 位页面目录条目 (PDE) 组成。中间 PDB(不是最顶层的 PDB)最多应有 512 个 PDE;也就是说,它们最多占用单个对齐的 4kb 内存页面。最顶层的 PDB 可以小或大,以表示所需的虚拟地址空间;最顶层的 PDB 可以占用多个 4kb 内存页面,但组成页面必须相邻。每个 PDE 指向 8 个 PDE 或 8 个 PTE 的缓存行的物理基址,具体取决于其在页表层次结构中的位置。
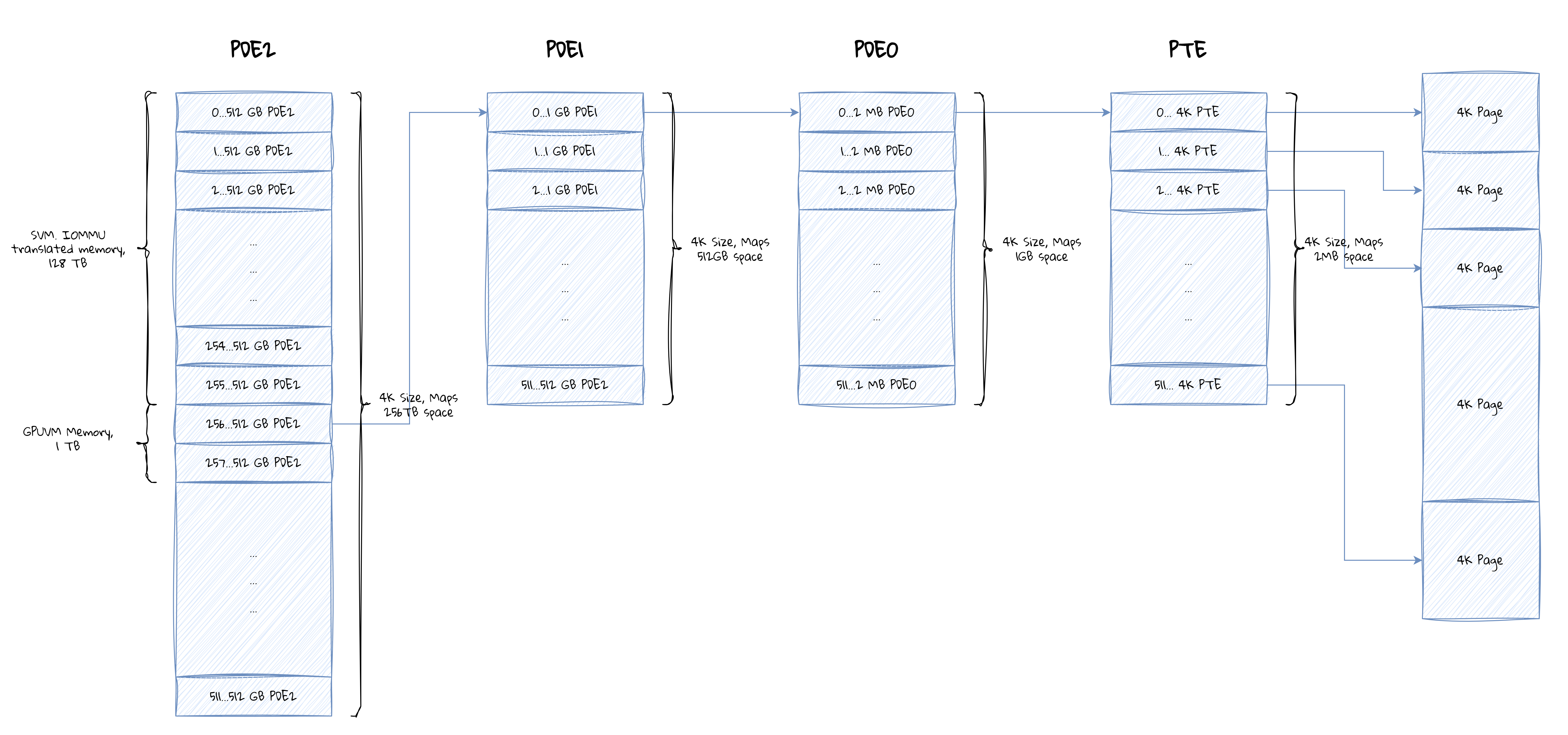
出于代码和寄存器文档命名目的,PDE 级别进一步描述如下:
- PDE0 - 指向 8 个 PTE 的起始缓存行
- PDE1 - 指向 8 个 PDE0 的起始缓存行
- PDE2 - 指向 8 个 PDE1 的起始缓存行
64 位 PDE 的格式为:
关联页表块大小为 0 的传统页表块 (PTB) 包含 512 个 64 位页表条目 (PTE),占用 4KB 内存空间。每个 PTE 指向一个 4KB 可寻址内存页,PTB 中的所有 512 个 PTE 共同寻址 2MB 内存空间(512 x 4KB = 2MB)。
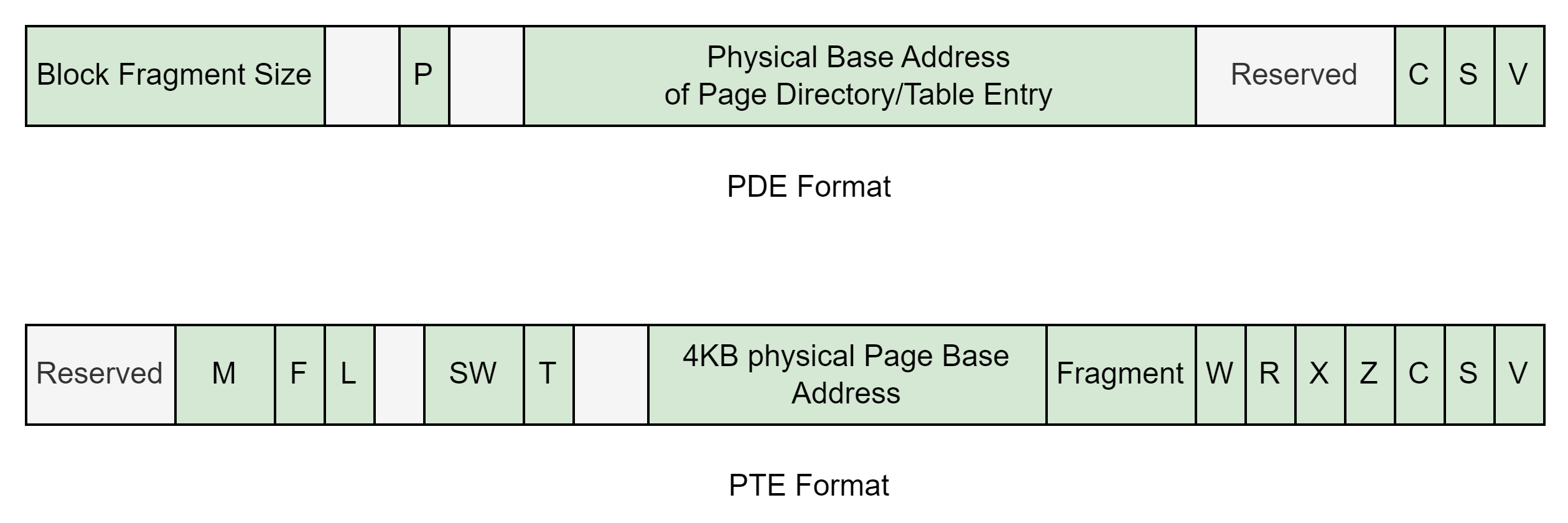
定义在:amdgpu-5.7.0-0\amd\amdgpu\amdgpu_vm.h
- M – Mtype
- F – 进一步转换
- L – 日志
- P - PTE
- SW – 软件
- T – 平铺 (PRT)
- W - 写入
- R - 读取
- X - 执行
- Z - tmZ
- C – 可缓存/监听
- S - 系统
- V - 有效
64 位 PTE 的格式为:
MTYPE 旨在控制基于描述符或指针的内存访问的 TC 缓存行为。此寄存器中指定的 Mtype 适用于没有关联描述符来指定 mtype 的内存访问。KMD 旨在根据寻址模式为非零 VMID 编程默认 mtype。对于 GPUVM32 和 64 寻址模式,KMD 应将默认 mtype 编程为 cached_NON_Coherent(NC),对于 HSA32 和 64 寻址模式,默认 mtype 编程为 Cached Coherent(CC)。VMID 0 的 Mtype 编程为 Uncached。
以下是 GPU 上的 mType 值:
- 0 - NC;缓存,非连贯
- 1 - WC;写入组合
- 2 - CC;缓存,连贯
- 3 - UC;未缓存的
V 位:V 位控制 PTE 是否为有效的 GPUVM 页面,如果将 V 位设置为 0,GPU MC 应该请求 ATC(IOMMU)进行进一步转换,因为它是主机页面而不是 GPU 页面,这用于实现共享虚拟内存。
C 位:指示内存类型是监听还是非监听。在 Linux 驱动程序中,根据页面是否缓存来设置位。
S 位:指示页面地址是否引用主机页面。在 Linux 驱动程序中,在为 GPU 访问分配主机页面时,始终在 PTE 中启用此位。
详细剖析见:
PTE(Page Table Entry,页表项)和 PDE(Page Directory Entry,页目录项)是虚拟内存管理系统中用于内存地址转换的重要概念,尤其是在 x86 架构和类似的内存管理单元(MMU)中广泛使用。在现代操作系统中,虚拟内存通过分页机制实现,将虚拟地址空间映射到物理地址空间。这种映射通常分为多级,即通过多个层次的表逐步解析虚拟地址,最终找到对应的物理地址。
PTE:
- 页表项是虚拟内存系统中最低级别的映射条目,用于将虚拟页面映射到物理页面。
- 结构:PTE 通常包含以下信息:
- 物理页框地址:指向物理内存中的一个页面的起始地址。
- 状态标志:如有效位(valid bit)、可读/可写标志(read/write bit)、用户/内核模式标志(user/kernel mode bit)等。
- 特权和缓存控制:可能包含一些关于该页面特权级别的标志和缓存控制位。
- 功能:当 CPU 需要访问某个虚拟地址时,PTE 会被查找到,以获取该地址对应的物理地址,从而进行实际的数据访问。
PDE:
- 页目录项是在多级分页结构中用于指向下一级页表的条目,通常是第一级映射。
- 结构:PDE 通常包含以下信息:
- 页表基地址:指向下一级页表的物理地址。
- 状态标志:类似 PTE,也有一些控制和状态标志,如有效位、权限标志等。
- 功能:PDE 的作用是指向页表(即包含 PTE 的数据结构)。在多级分页机制中,CPU 会先查找 PDE 来确定具体使用哪个页表,然后再通过该页表中的 PTE 找到最终的物理地址。
多级页表管理:
- 一级分页(单级页表):整个虚拟地址空间通过一个单一的页表映射到物理地址。
- 多级分页(例如两级或四级页表):虚拟地址通过多个级别的表来逐步解析。最常见的是两级或四级页表结构。
- 二级页表:包含页目录(Page Directory)和页表(Page Table)。虚拟地址首先通过页目录项(PDE)找到页表,然后通过页表项(PTE)找到对应的物理页框。
- 四级页表:进一步扩展,添加了页全局目录(Page Global Directory,PGD)和页上级目录(Page Upper Directory,PUD),用于处理更大的虚拟地址空间。
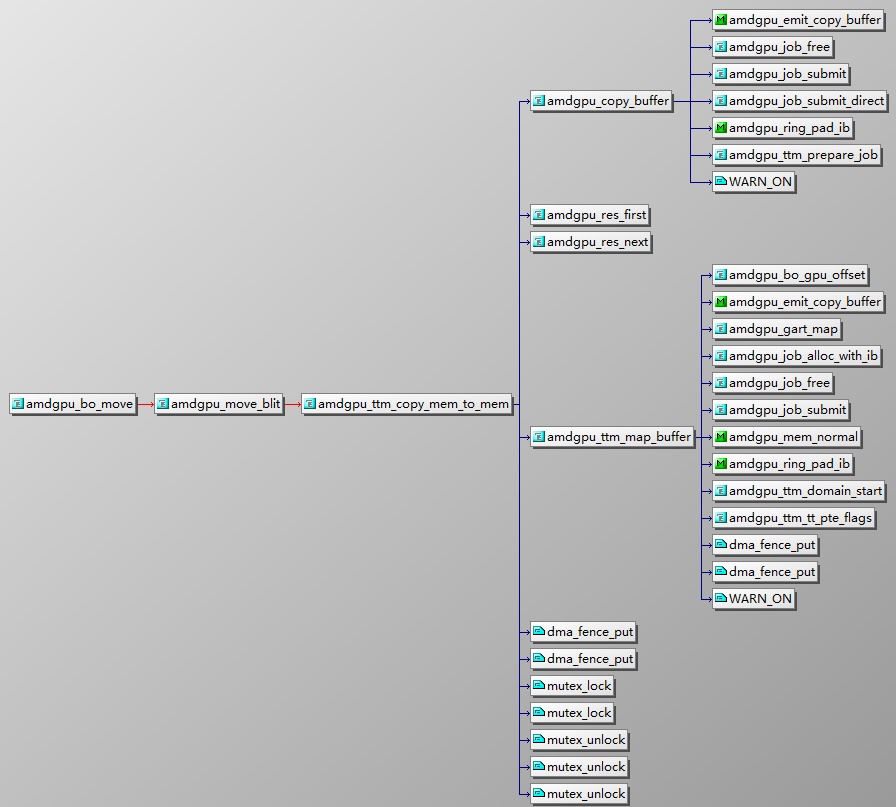
BO 是在图形驱动程序中用于管理内存缓冲区的抽象对象。在 AMD 的驱动程序中,BO 通常与图形资源(如纹理、 Frame Buffer 、顶点缓冲区等)相关联。这些缓冲区对象通过 TTM 或其他内存管理机制来管理和分配实际的内存资源。BO 具备以下特性:
- 内存分配:通过 BO 接口,图形驱动程序可以为各种图形资源分配和管理内存。
- 引用计数:BO 通常带有引用计数机制,以确保在缓冲区不再需要时可以安全地释放内存。
- 内存映射:BO 可以被映射到用户空间,使得应用程序可以直接访问这些图形资源。
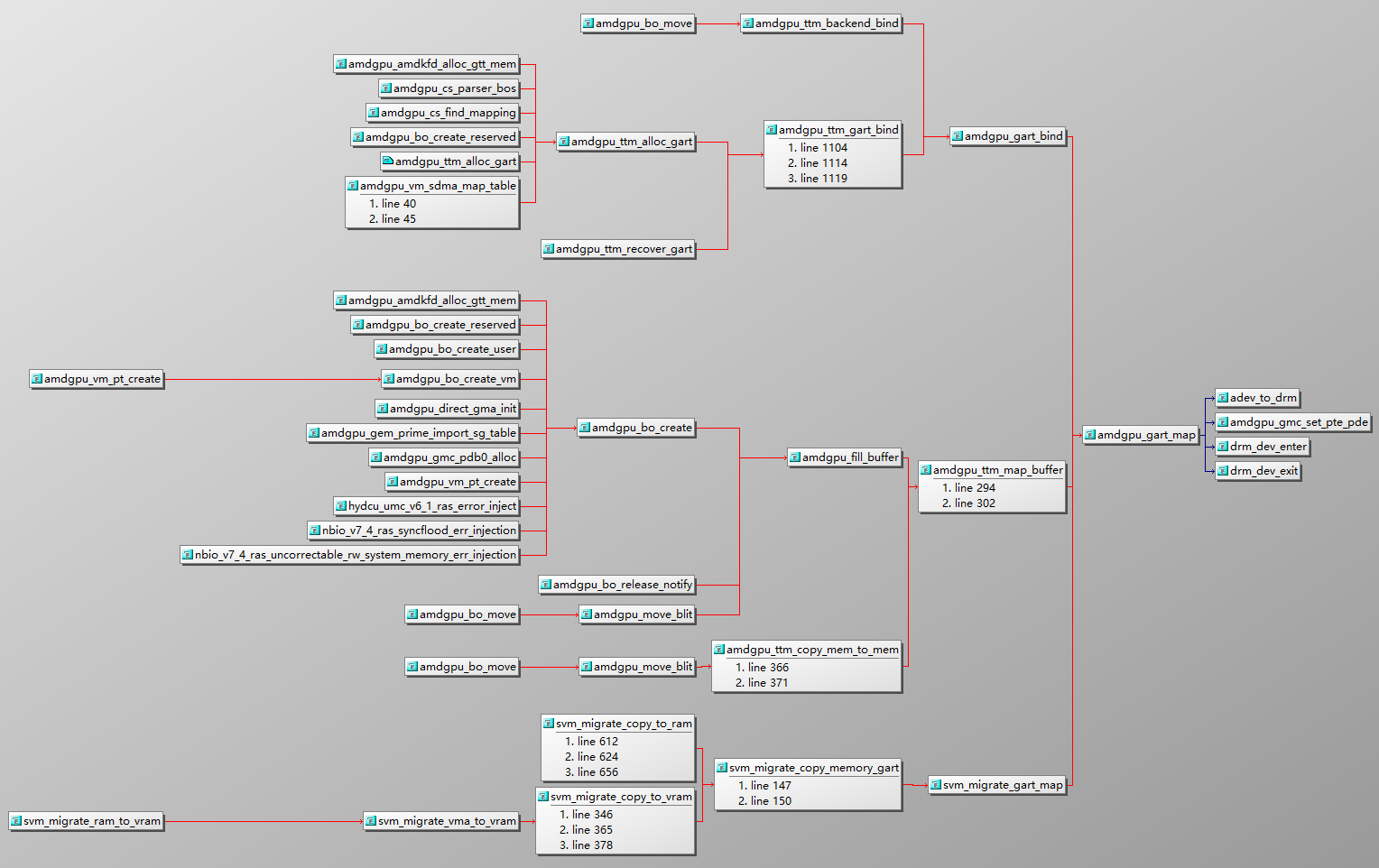
GART 是一个关键的内存管理机制,主要用于在系统内存(通常是主机的 RAM)和 GPU(图形处理单元)的地址空间之间进行地址映射和管理。
- 地址映射:
- GART 是一种内存管理单元(MMU),用于将系统内存中的物理地址映射到 GPU 虚拟地址空间(GPUVA)。这种映射允许 GPU 直接访问系统内存中的数据,而不必将所有数据都存储在有限的显存(VRAM)中。
- 通过 GART,系统内存的一部分被虚拟化为 GPU 可以访问的地址范围,从而扩展了 GPU 的可用内存空间。
- 页面调度与切换:
- GART 支持对大页面和小页面的管理,使得 GPU 能够灵活地访问系统内存中的不同大小的内存块。
- 当 GPU 需要访问不在显存中的数据时,GART 可以通过页表切换将这些数据从系统内存加载到 GPU 可访问的地址空间。
- 内存一致性与缓存:
- GART 负责确保 CPU 和 GPU 之间的数据一致性。它通过控制地址映射,确保当 CPU 修改了某些系统内存区域后,GPU 能够及时看到这些修改。
- GART 还涉及到缓存控制,确保在不同情况下正确处理缓存一致性问题。
在 AMD GPU 架构中,GART 通常用于以下场景:
- 共享内存资源:当 GPU 需要频繁访问大量的系统内存数据时,使用 GART 允许这些数据直接映射到 GPU 的地址空间,而无需不断地在 VRAM 和系统内存之间移动数据。
- 数据传输:在数据传输过程中,GART 可以有效地管理从系统内存到 GPU 地址空间的数据路径,提高数据传输效率。
用
在实际的应用场景中,GART 被用于管理那些无法全部放入 VRAM 的数据,尤其是在需要处理大量数据或当 VRAM 资源受限的情况下。例如,在大型图形应用程序或游戏中,GART 允许 GPU 访问那些需要动态加载和处理的资源,如纹理、几何数据等。
以下是具体细节的KMD代码实现分析:
内存申请
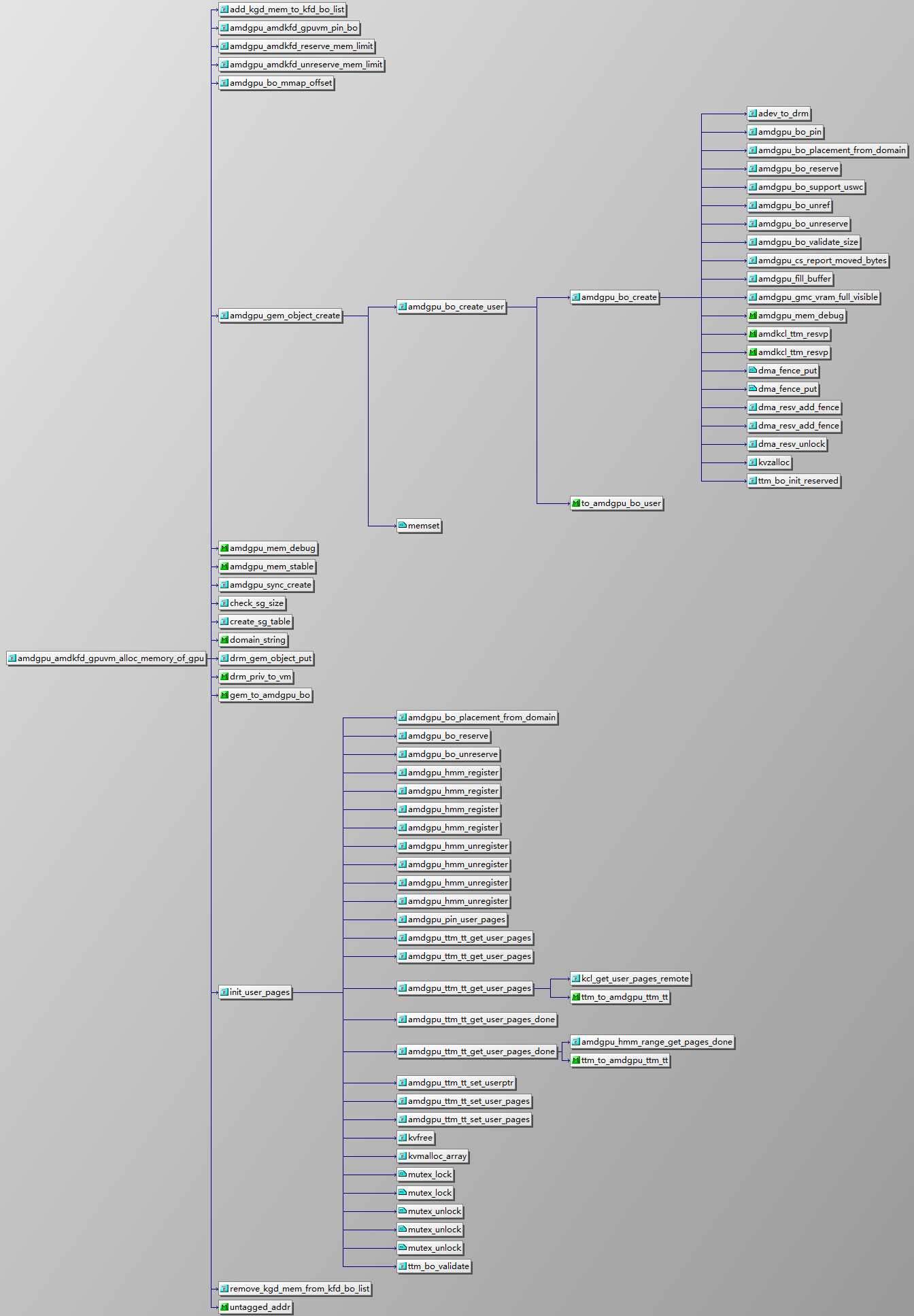
用于在 GPU 虚拟内存(GPUVM)中分配内存。该函数处理内存的分配、初始化和管理,确保 GPU 和 CPU 之间的内存映射和访问符合预期。
参数解析
adev: 指向amdgpu_device结构体的指针,表示当前的 AMD GPU 设备。va: 虚拟地址,表示分配的内存在 GPU 虚拟地址空间中的位置。size: 要分配的内存的大小,以字节为单位。drm_priv: 表示与当前进程相关的 DRM 私有数据,通常是一个指向amdgpu_vm(虚拟内存)结构的指针。mem: 指向指针的指针,函数返回时会指向一个已分配的kgd_mem结构体,表示分配的 GPU 内存。offset: 指向 64 位整数的指针,函数返回时会包含与分配的内存相关的偏移量(通常用于 mmap)。flags: 内存分配标志,指示如何分配内存(例如分配到 VRAM、GTT 等)。criu_resume: 布尔值,指示是否在 CRIU 恢复上下文中分配内存。
主要执行流程
- 虚拟内存初始化:
- 函数首先从
drm_priv中提取出amdgpu_vm(虚拟内存管理)结构。 - 根据
flags确定分配内存的类型(VRAM、GTT、用户指针等),并设置相应的内存分配标志。
- 函数首先从
- 分配内存区域:
- 如果标志表明内存应分配在 VRAM 中,函数会设置
domain和alloc_domain为 VRAM,并根据标志确定其他分配选项,如 CPU 访问要求等。 - 如果标志指示内存应分配在 GTT(显卡地址转换表)中,函数会相应设置
domain和alloc_domain为 GTT。 - 函数还会处理其他特殊情况,如用户指针(
USERPTR)或DOORBELL内存。
- 如果标志表明内存应分配在 VRAM 中,函数会设置
- 分配
kgd_mem结构:- 函数为
kgd_mem结构分配内存,并初始化它的一些基本字段,如分配标志和同步对象。
- 函数为
- 内存预留与分配:
- 函数会调用
amdgpu_amdkfd_reserve_mem_limit预留内存限制,以确保足够的内存可供分配。 - 使用
amdgpu_gem_object_create创建实际的缓冲区对象(BO),这代表了分配的 GPU 内存。
- 函数会调用
- 内存映射与管理:
- 如果是用户指针内存(
USERPTR),函数会初始化用户页表。 - 如果是
DOORBELL或MMIO_REMAP内存,函数会将 BO 固定在 GTT 中。 - 最后,函数会将偏移量返回给调用者,以便于后续的内存映射。
- 如果是用户指针内存(
- 错误处理与回滚:
- 函数包含多个错误处理路径。如果在内存分配或初始化过程中遇到问题,它会清理已分配的资源,并返回相应的错误代码。
关键概念
- BO (Buffer Object): 在图形驱动程序中用于表示 GPU 上的内存缓冲区。
- GTT (Graphics Translation Table): 用于管理系统内存与 GPU 显存之间的映射。
- VRAM: 显存,GPU 上的高速内存,用于存储需要快速访问的数据,如纹理、 Frame Buffer 等。
- User Pointer (USERPTR): 允许用户空间的指针直接映射到 GPU 的地址空间,通常用于高效的数据共享。
该函数的作用
这个函数的作用是确保在适当的内存域(VRAM、GTT 等)中分配 GPU 内存,并处理复杂的内存映射需求,同时提供足够的灵活性以应对不同的内存分配场景(如用户指针、DOORBELL 等)。它是 AMD GPU 驱动程序中的一个重要部分,确保了 GPU 内存的高效管理和使用。
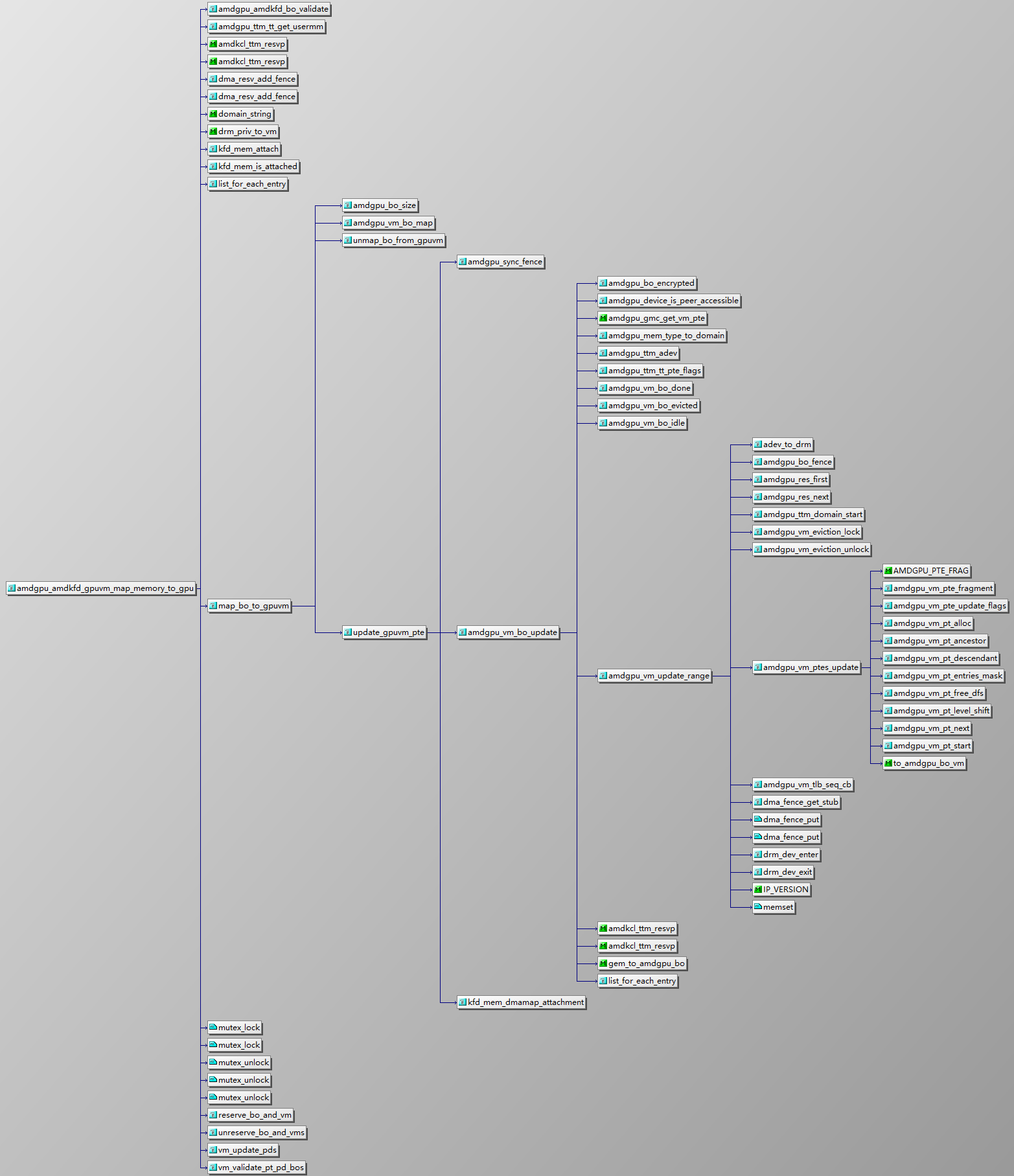
内存映射
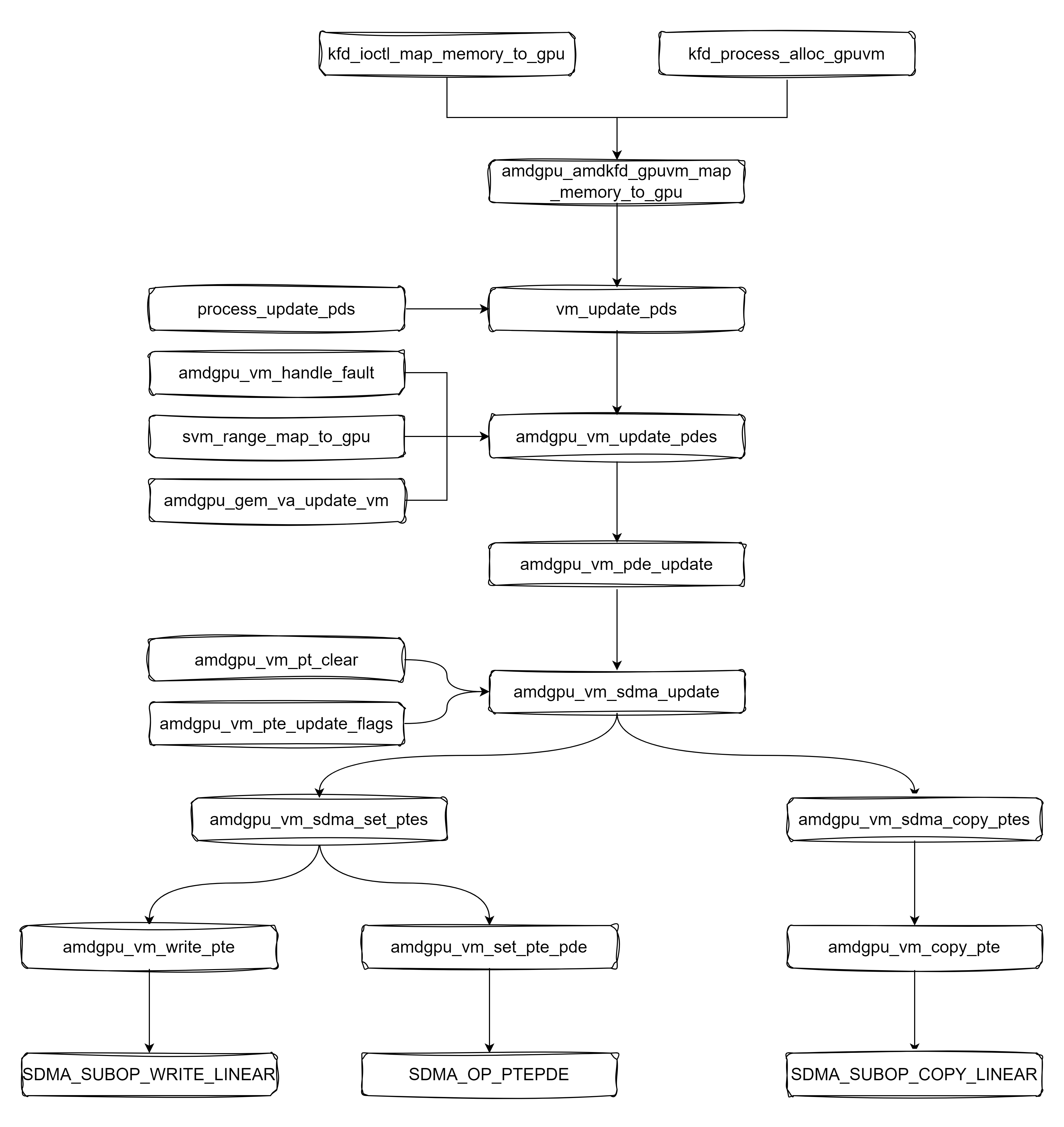
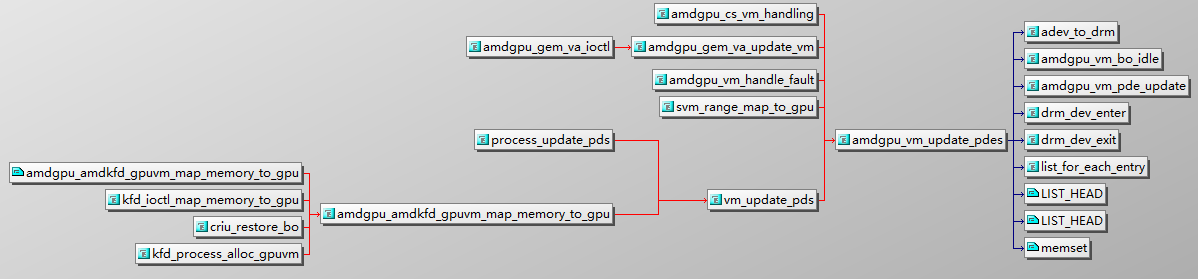
1 | |
当缓存中未写入的数据量达到一定水平时,控制器会定期将缓存数据写入驱动器。此写入过程称为“刷新”。
控制器使用两种算法来刷新缓存:基于需求和基于年龄。控制器使用基于需求的算法,直到缓存数据量低于缓存刷新阈值。默认情况下,当 80% 的缓存正在使用时,刷新开始。
在系统管理器中,您可以设置“启动需求缓存刷新”阈值,以最好地支持环境中使用的 I/O 类型。在主要进行写入操作的环境中,您应该将“启动需求缓存刷新”百分比设置为较高,以增加任何新的写入请求都可以由缓存处理而无需转到磁盘的可能性。高百分比设置会限制缓存刷新的次数,以便更多数据保留在缓存中,从而增加更多缓存命中的机会。
在 I/O 不稳定(数据突发)的环境中,您可以使用较低的缓存刷新,以便系统在数据突发之间频繁刷新缓存。在处理各种负载的多样化 I/O 环境中,或者当负载类型未知时,将阈值设置为 50% 是一个不错的中间值。请注意,如果选择的启动百分比低于 80%,则可能会看到性能下降,因为主机读取所需的数据可能不可用。选择较低的百分比还会增加维持缓存级别所需的磁盘写入次数,从而增加系统开销。
基于年龄的算法指定写入数据在有资格刷新到磁盘之前可以保留在缓存中的时间段。控制器使用基于年龄的算法,直到达到缓存刷新阈值。默认值为 10 秒,但此时间段仅在非活动期间计算。您无法在系统管理器中修改刷新时间;相反,您必须使用命令行界面 (CLI) 中的“设置存储阵列”命令。
1 | |
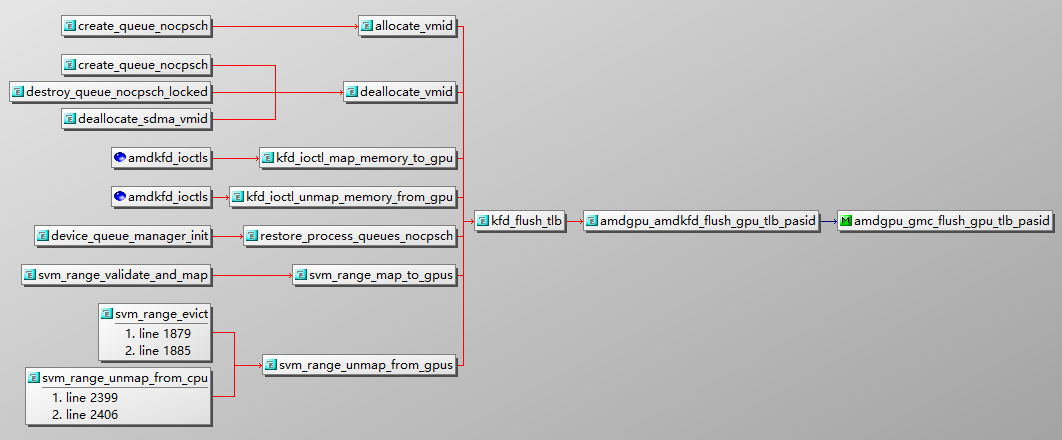
amdgpu_amdkfd_flush_gpu_tlb_pasid –> amdgpu_gmc_flush_gpu_tlb_pasid –> gmc_v9_0_flush_gpu_tlb_pasid –> gfx_v9_0_kiq_invalidate_tlbs
其中,kfd_ioctl_unmap_memory_from_gpu / svm_range_unmap_from_gpus 采用 TLB_FLUSH_HEAVYWEIGHT 策略
第二路径:
gmc_v9_0_flush_gpu_tlb_pasid –> gfx_v9_0_kiq_invalidate_tlbs
gmc_v9_0_flush_gpu_tlb_pasid –> gmc_v9_0_flush_gpu_tlb(无pasid flush)
gmc_v9_0_hw_init –> gmc_v9_0_flush_gpu_tlb
amdgpu_gmc_flush_gpu_tlb –> gmc_v9_0_flush_gpu_tlb
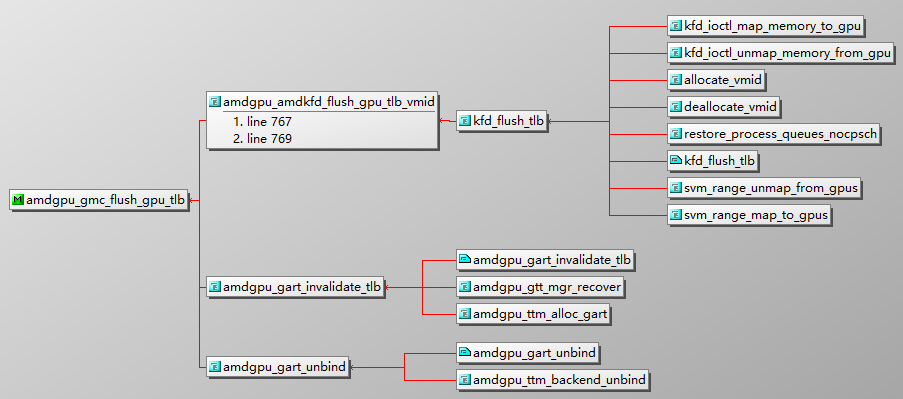
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |