图解 Transformer
本教程的学习路径是:Attention->Transformer->BERT->NLP应用。
转自:https://github.com/datawhalechina/learn-nlp-with-transformers
图解Attention
问题:Attention出现的原因是什么?
潜在的答案:基于循环神经网络(RNN)一类的seq2seq模型,在处理长文本时遇到了挑战,而对长文本中不同位置的信息进行attention有助于提升RNN的模型效果。
于是学习的问题就拆解为:1. 什么是seq2seq模型?2. 基于RNN的seq2seq模型如何处理文本/长文本序列?3. seq2seq模型处理长文本序列时遇到了什么问题?4.基于RNN的seq2seq模型如何结合attention来改善模型效果?
seq2seq框架
seq2seq是一种常见的NLP模型结构,全称是:sequence to sequence,翻译为“序列到序列”。顾名思义:从一个文本序列得到一个新的文本序列。典型的任务有:机器翻译任务,文本摘要任务。谷歌翻译在2016年末开始使用seq2seq模型,并发表了2篇开创性的论文:Sutskever等2014年发表的Sequence to Sequence Learning
with Neural Networks和Cho等2014年发表的Learning Phrase Representations using RNN Encoder–Decoder
for Statistical Machine Translation,感兴趣的读者可以阅读原文进行学习。
无论读者是否读过上述两篇谷歌的文章,NLP初学者想要充分理解并实现seq2seq模型很不容易。因为,我们需要拆解一系列相关的NLP概念,而这些NLP概念又是是层层递进的,所以想要清晰的对seq2seq模型有一个清晰的认识并不容易。但是,如果能够把这些复杂生涩的NLP概念可视化,理解起来其实就更简单了。因此,本文希望通过一系列图片、动态图帮助NLP初学者学习seq2seq以及attention相关的概念和知识。
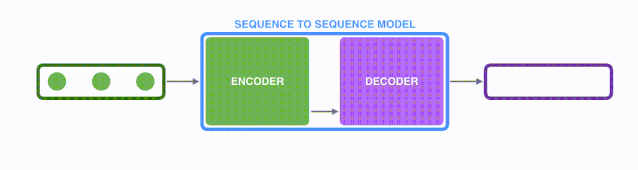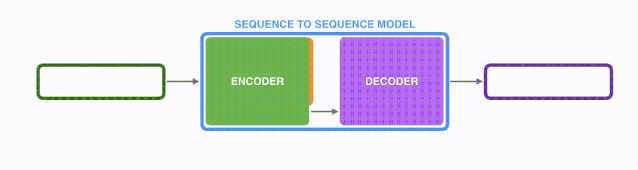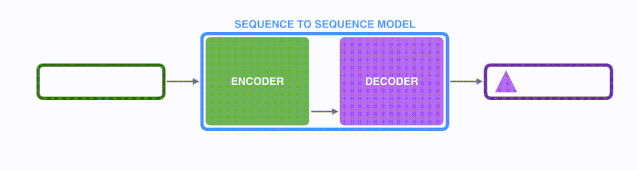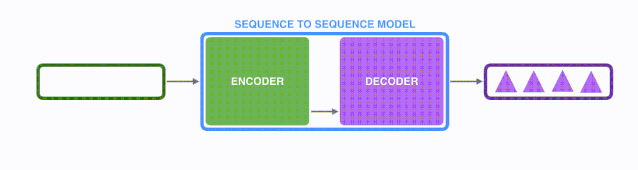
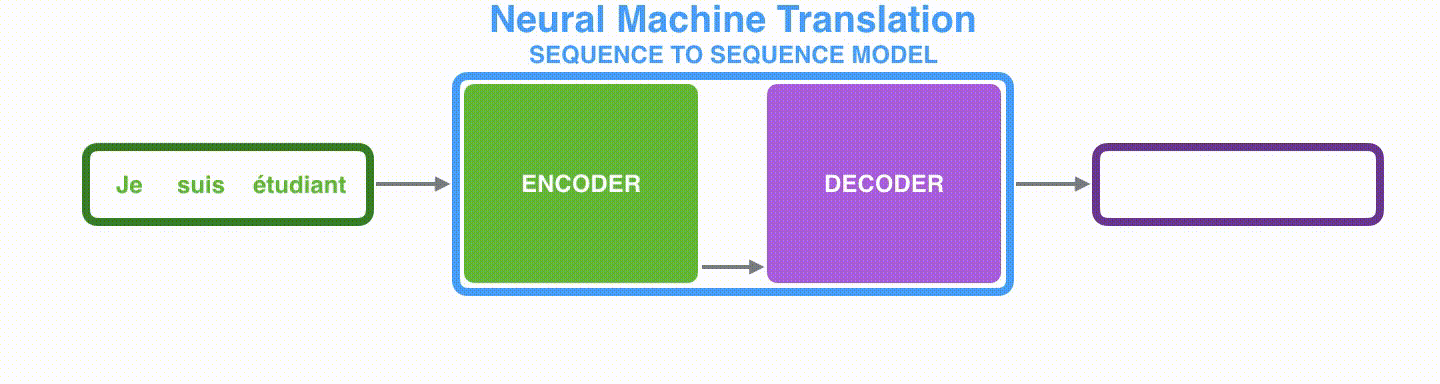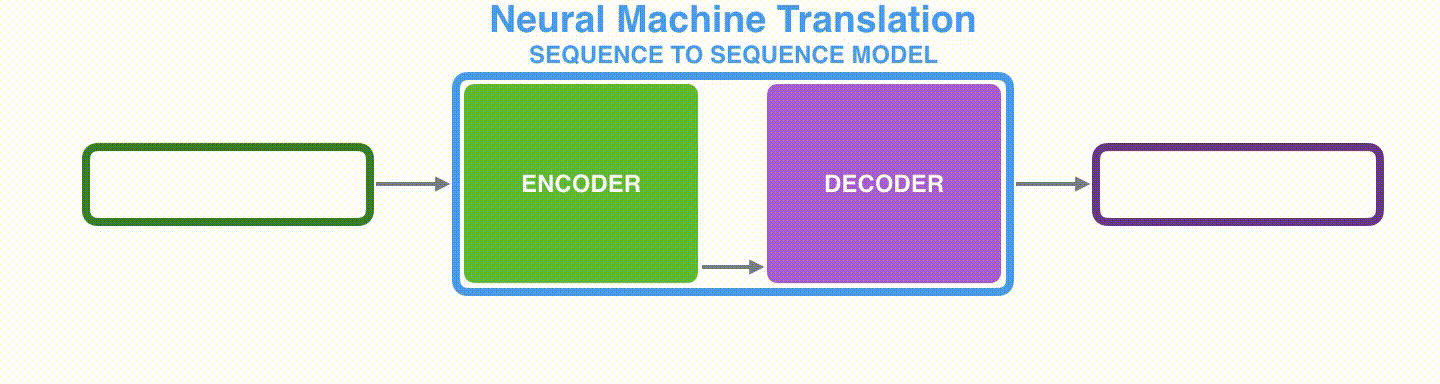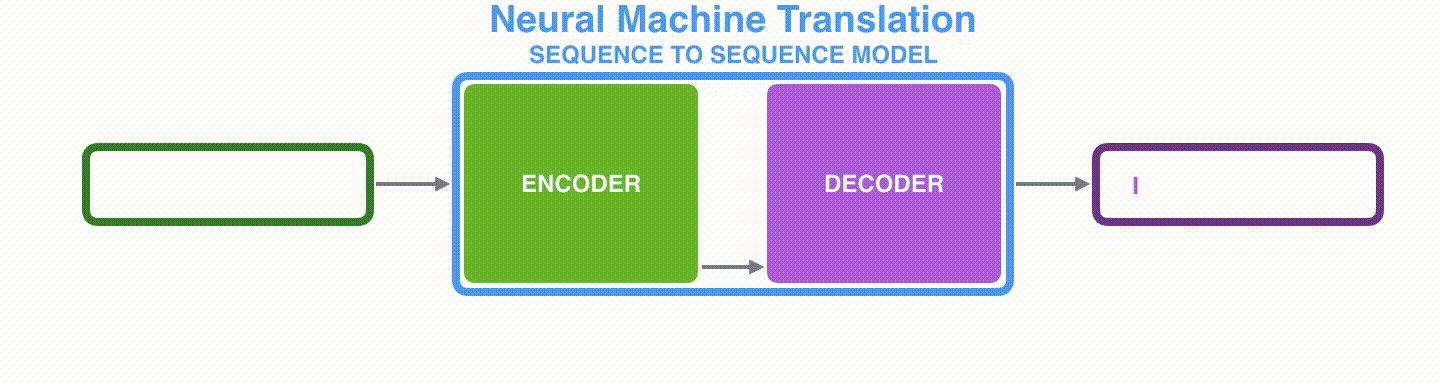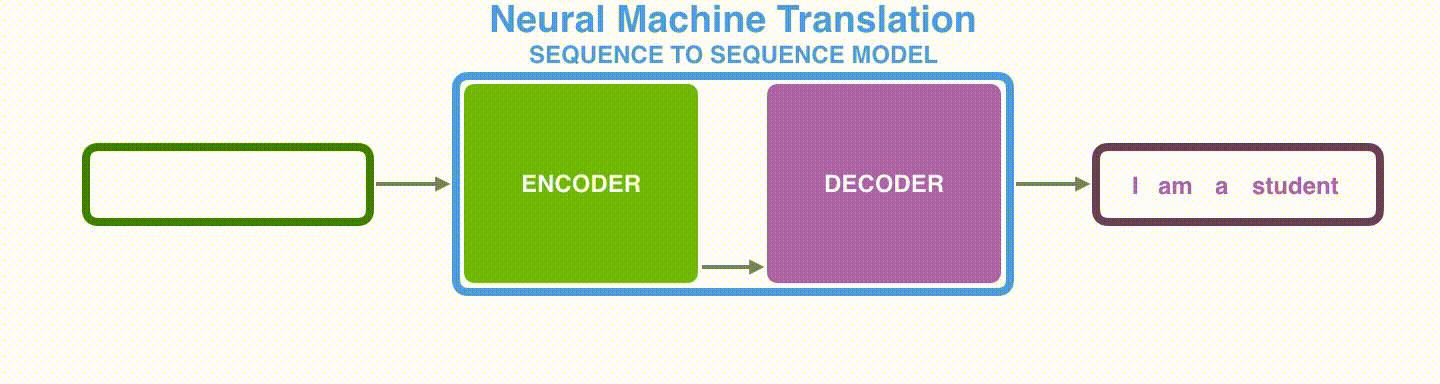
首先看seq2seq干了什么事情?seq2seq模型的输入可以是一个(单词、字母或者图像特征)序列,输出是另外一个(单词、字母或者图像特征)序列。一个训练好的seq2seq模型如下图所示(注释:将鼠标放在图上,图就会动起来):

如下图所示,以NLP中的机器翻译任务为例,序列指的是一连串的单词,输出也是一连串单词。
seq2seq细节
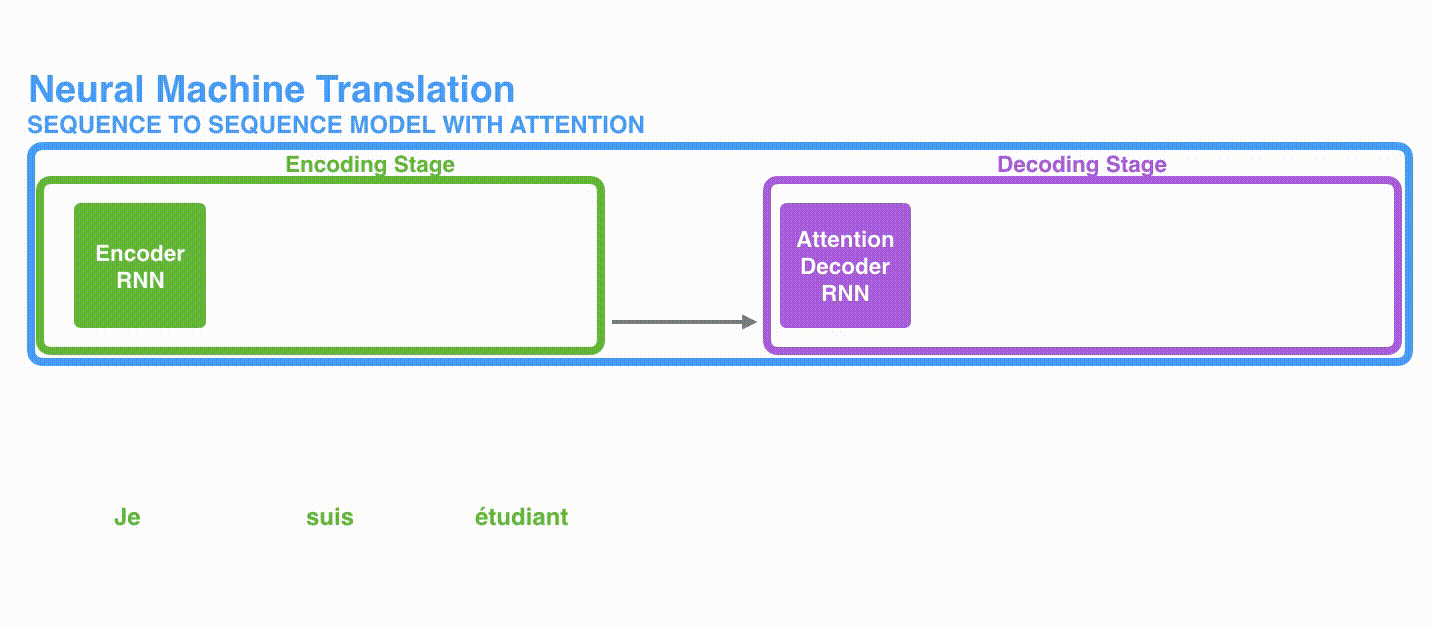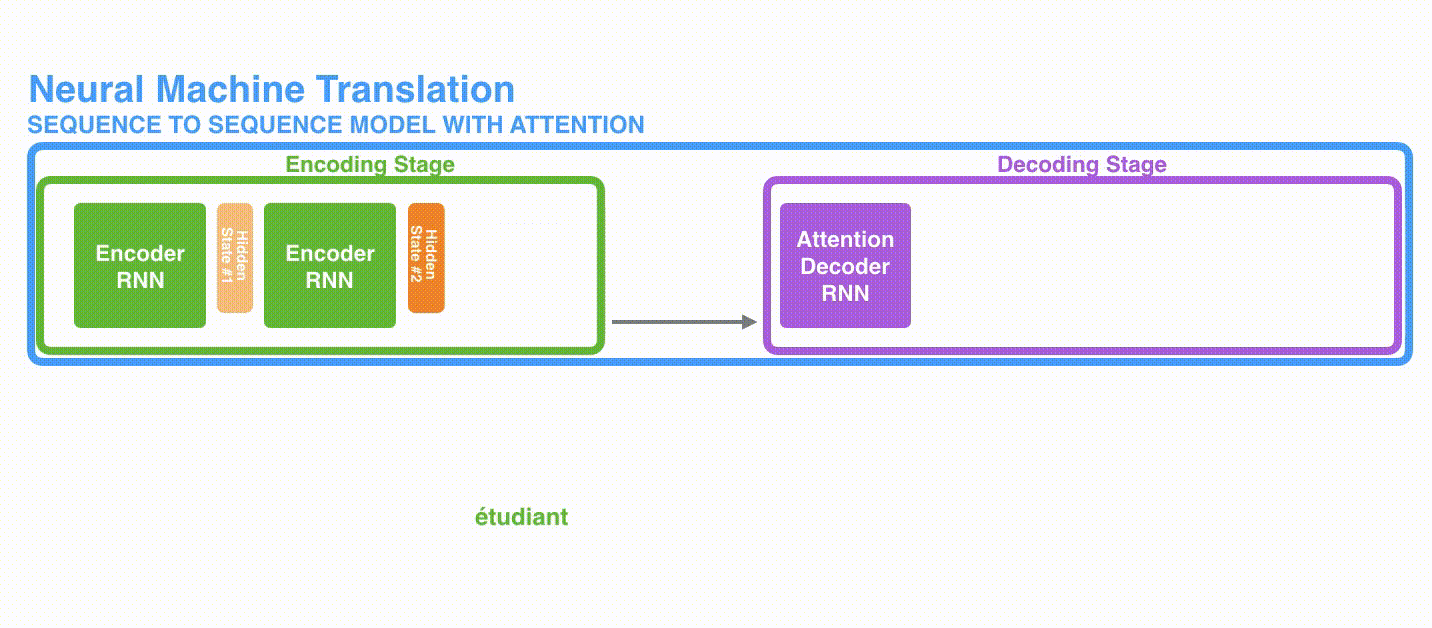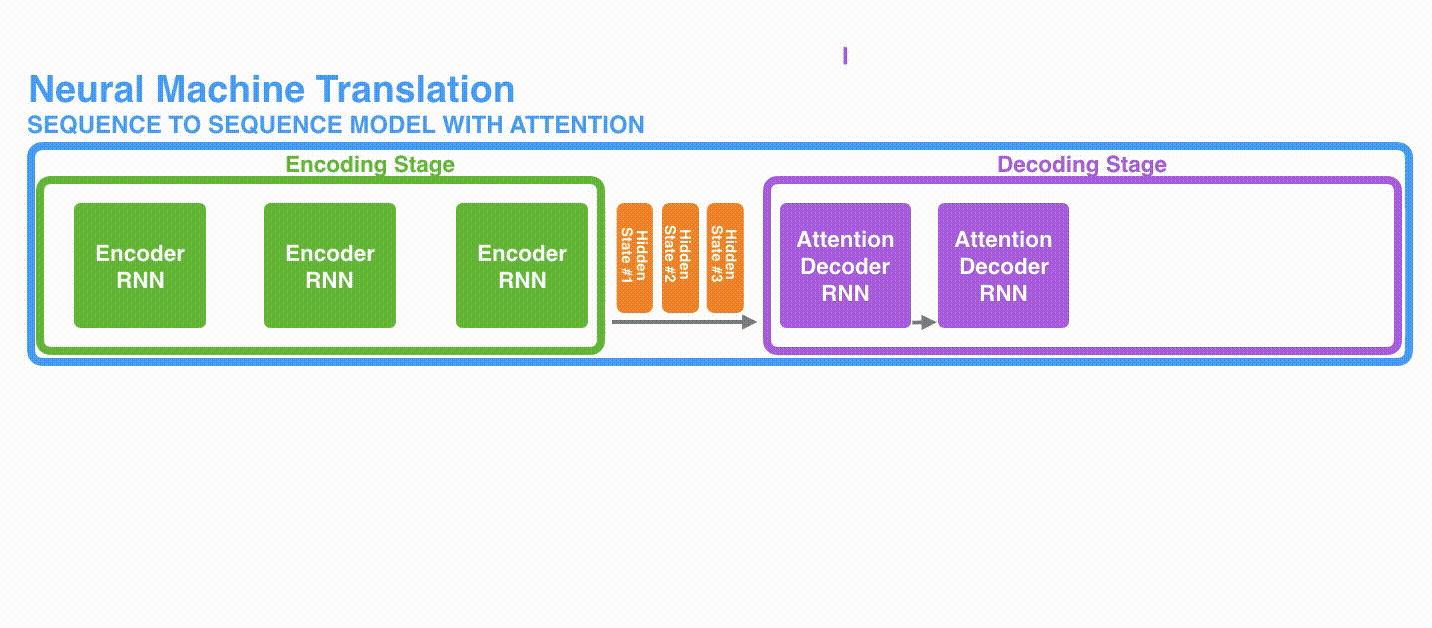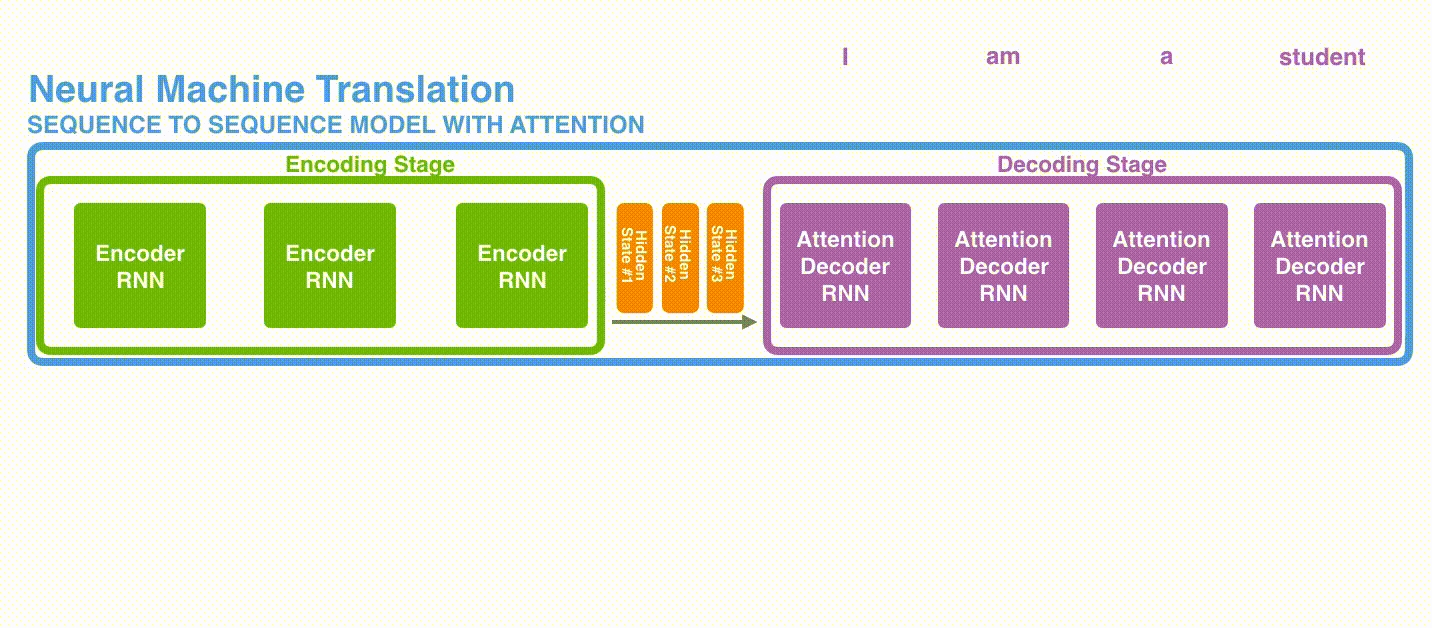
将上图中蓝色的seq2seq模型进行拆解,如下图所示:seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。绿色的编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个黄色的向量(称为context向量)。当我们处理完整个输入序列后,编码器把 context向量 发送给紫色的解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
由于seq2seq模型可以用来解决机器翻译任务,因此机器翻译被任务seq2seq模型解决过程如下图所示,当作seq2seq模型的一个具体例子来学习。
深入学习机器翻译任务中的seq2seq模型,如下图所示。seq2seq模型中的编码器和解码器一般采用的是循环神经网络RNN(Transformer模型还没出现的过去时代)。编码器将输入的法语单词序列编码成context向量(在绿色encoder和紫色decoder中间出现),然后解码器根据context向量解码出英语单词序列。关于循环神经网络,本文建议阅读 Luis Serrano写的循环神经网络精彩介绍.

如上图所示,我们来看一下黄色的context向量是什么?本质上是一组浮点数。而这个context的数组长度是基于编码器RNN的隐藏层神经元数量的。上图展示了长度为4的context向量,但在实际应用中,context向量的长度是自定义的,比如可能是256,512或者1024。
那么RNN是如何具体地处理输入序列的呢?
假设序列输入是一个句子,这个句子可以由$n$个词表示:$sentence = {w_1, w_2,…,w_n}$。
RNN首先将句子中的每一个词映射成为一个向量得到一个向量序列:$X = {x_1, x_2,…,x_n}$,每个单词映射得到的向量通常又叫做:word embedding。
然后在处理第$t \in [1,n]$个时间步的序列输入$x_t$时,RNN网络的输入和输出可以表示为:$h_{t} = RNN(x_t, h_{t-1})$
- 输入:RNN在时间步$t$的输入之一为单词$w_t$经过映射得到的向量$x_t$。
- 输入:RNN另一个输入为上一个时间步$t-1$得到的hidden state向量$h_{t-1}$,同样是一个向量。
- 输出:RNN在时间步$t$的输出为$h_t$ hidden state向量。
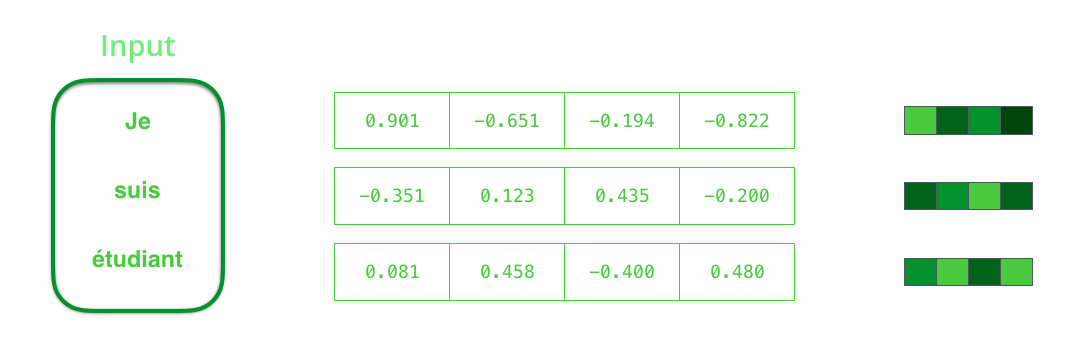
让我们来进一步可视化一下基于RNN的seq2seq模型中的编码器在第1个时间步是如何工作:
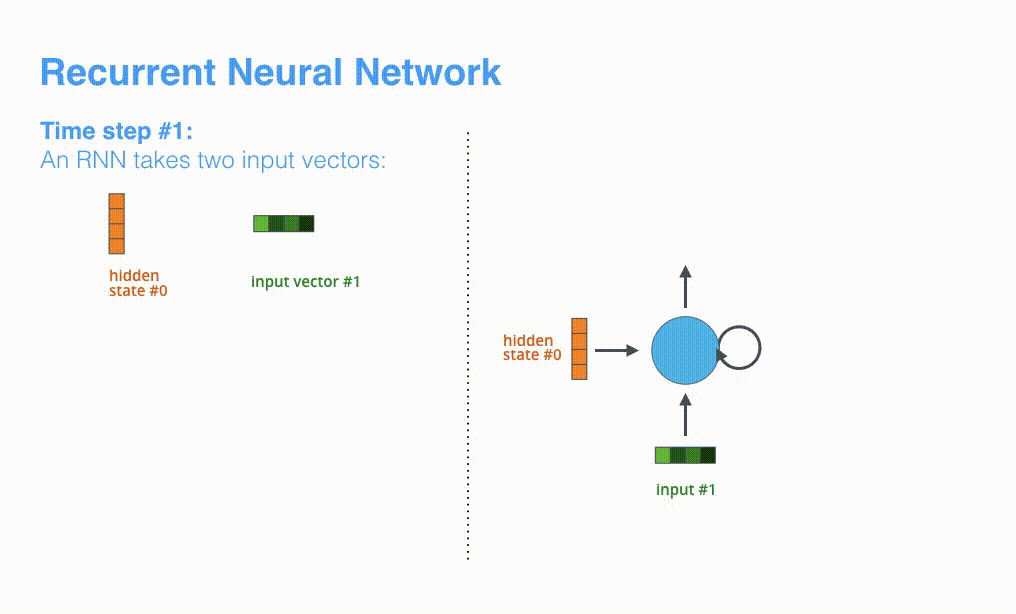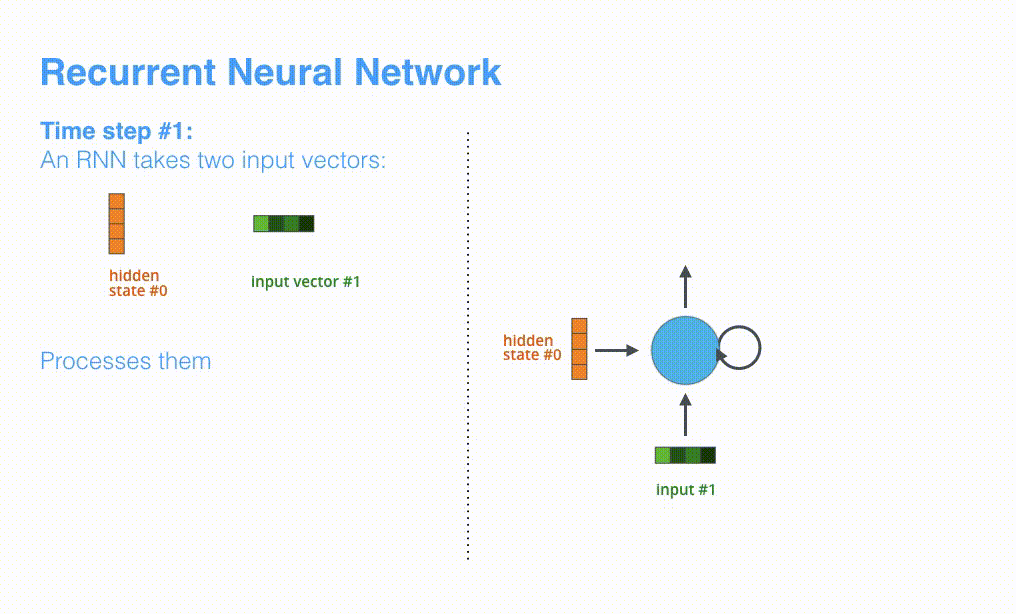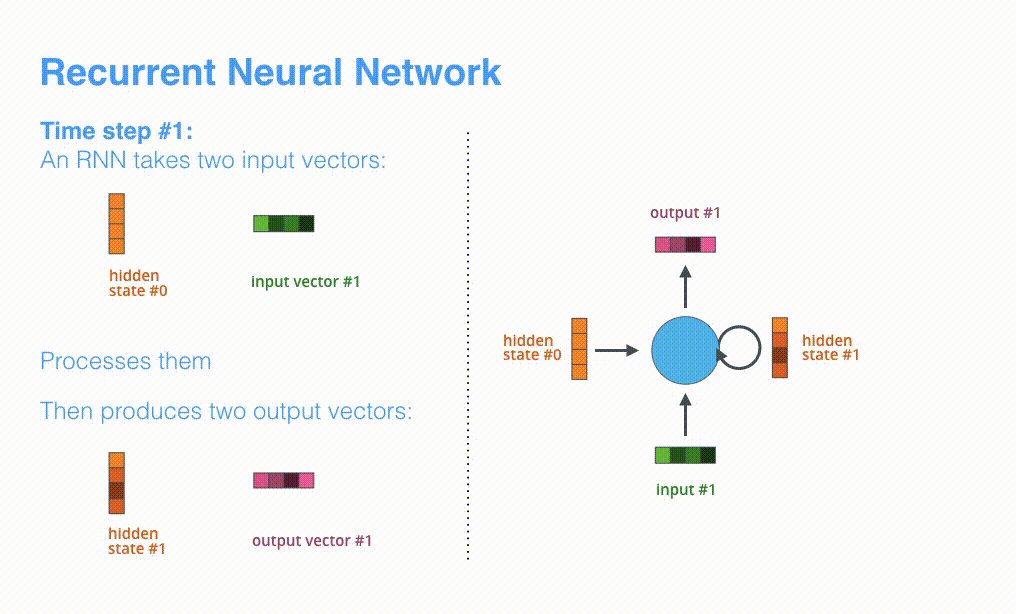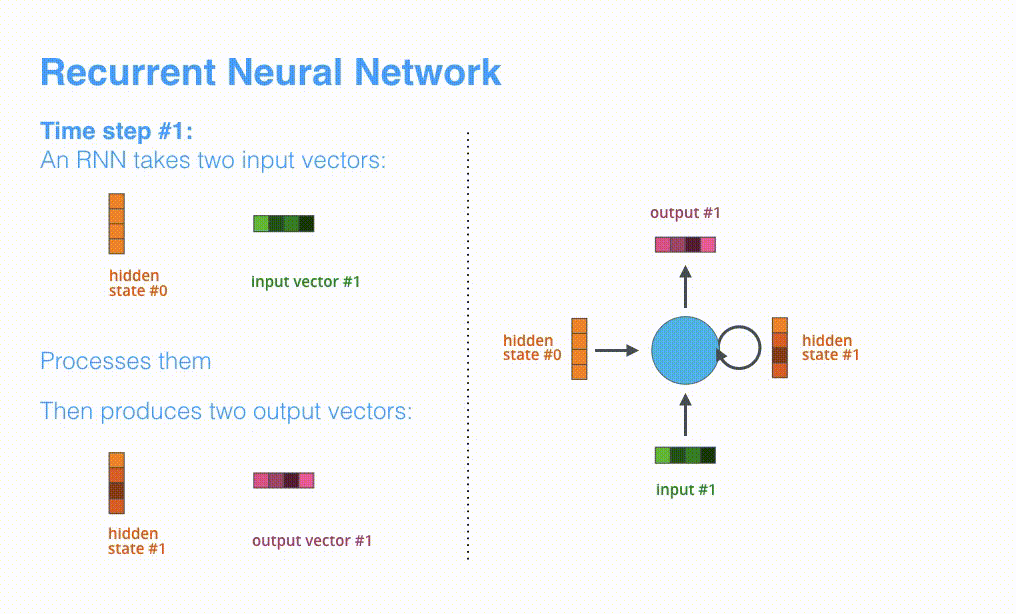
看下面的动态图,让我们详细观察一下编码器如何在每个时间步得到hidden sate,并将最终的hidden state传输给解码器,解码器根据编码器所给予的最后一个hidden state信息解码处输出序列。注意,最后一个 hidden state实际上是我们上文提到的context向量。
接着,结合编码器处理输入序列,一起来看下解码器如何一步步得到输出序列的l。与编码器类似,解码器在每个时间步也会得到 hidden state(隐藏层状态),而且也需要把 hidden state(隐藏层状态)从一个时间步传递到下一个时间步。

目前为止,希望你已经明白了本文开头提出的前两个问题:1. 什么是seq2seq模型?2. seq2seq模型如何处理文本/长文本序列?那么请思考第3、4个问题:3. seq2seq模型处理文本序列(特别是长文本序列)时会遇到什么问题?4.基于RNN的seq2seq模型如何结合attention来解决问题3并提升模型效果?
Attention
基于RNN的seq2seq模型编码器所有信息都编码到了一个context向量中,便是这类模型的瓶颈。一方面单个向量很难包含所有文本序列的信息,另一方面RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战(比如RNN处理到第500个单词的时候,很难再包含1-499个单词中的所有信息了)。
面对以上问题,Bahdanau等2014发布的Neural Machine Translation by Jointly Learning to Align and Translate 和 Luong等2015年发布的Effective Approaches to Attention-based Neural Machine Translation 两篇论文中,提出了一种叫做注意力attetion的技术。通过attention技术,seq2seq模型极大地提高了机器翻译的质量。归其原因是:attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
下图依旧是机器翻译的例子:
让我们继续来理解带有注意力的seq2seq模型:一个注意力模型与经典的seq2seq模型主要有2点不同:
- A. 首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态),如下面的动态图所示:
B. 注意力模型的解码器在产生输出之前,做了一个额外的attention处理。如下图所示,具体为:
- 由于编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词,那么解码器要查看所有接收到的编码器的 hidden state(隐藏层状态)。
- 给每个 hidden state(隐藏层状态)计算出一个分数(我们先忽略这个分数的计算过程)。
- 所有hidden state(隐藏层状态)的分数经过softmax进行归一化。
- 将每个 hidden state(隐藏层状态)乘以所对应的分数,从而能够让高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
- 将所有hidden state根据对应分数进行加权求和,得到对应时间步的context向量。

所以,attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
现在,让我们把所有内容都融合到下面的图中,来看看结合注意力的seq2seq模型解码器全流程,动态图展示的是第4个时间步:
- 注意力模型的解码器 RNN 的输入包括:一个word embedding 向量,和一个初始化好的解码器 hidden state,图中是$h_{init}$。
- RNN 处理上述的 2 个输入,产生一个输出和一个新的 hidden state,图中为h4。
- 注意力的步骤:我们使用编码器的所有 hidden state向量和 h4 向量来计算这个时间步的context向量(C4)。
- 我们把 h4 和 C4 拼接起来,得到一个橙色向量。
- 我们把这个橙色向量输入一个前馈神经网络(这个网络是和整个模型一起训练的)。
- 根据前馈神经网络的输出向量得到输出单词:假设输出序列可能的单词有N个,那么这个前馈神经网络的输出向量通常是N维的,每个维度的下标对应一个输出单词,每个维度的数值对应的是该单词的输出概率。
- 在下一个时间步重复1-6步骤。
到目前为止,希望你已经知道本文开头提出的3、4问题的答案啦:3、seq2seq处理长文本序列的挑战是什么?4、seq2seq是如何结合attention来解决问题3中的挑战的?
最后,我们可视化一下注意力机制,看看在解码器在每个时间步关注了输入序列的哪些部分: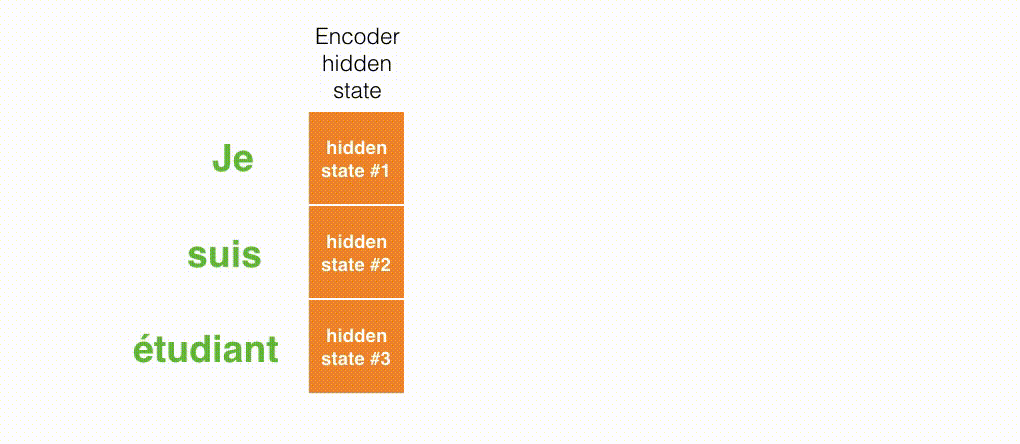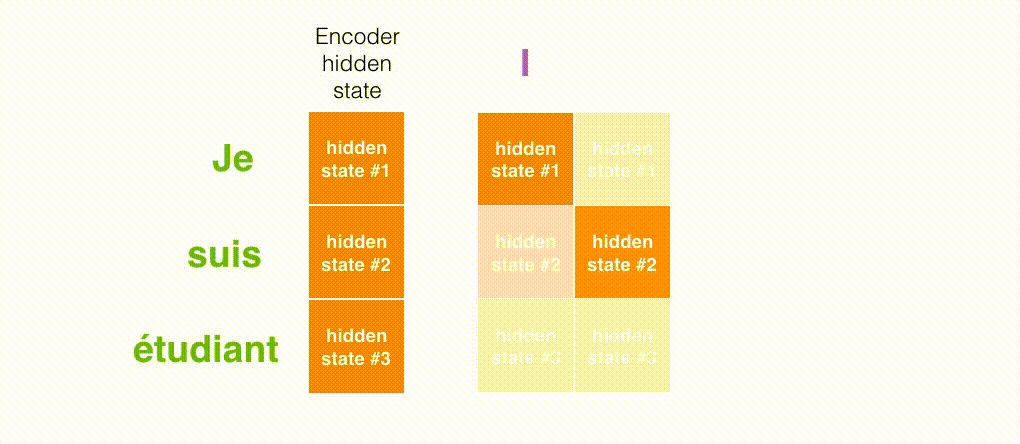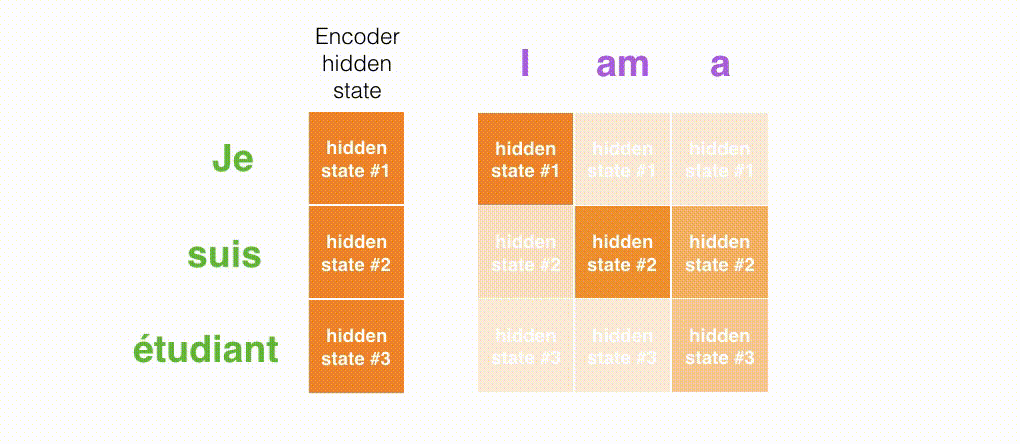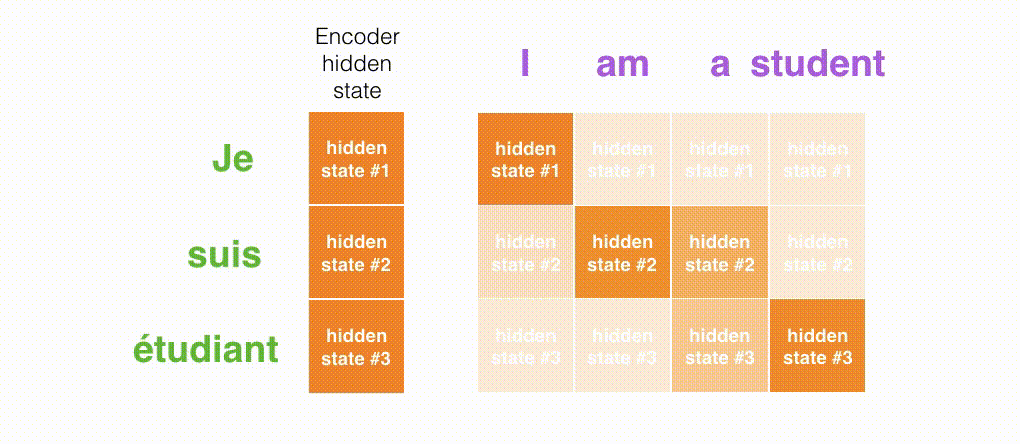
需要注意的是:注意力模型不是无意识地把输出的第一个单词对应到输入的第一个单词,它是在训练阶段学习到如何对两种语言的单词进行对应(在我们的例子中,是法语和英语)。
下图还展示了注意力机制的准确程度(图片来自于上面提到的论文):
图解transformer
在学习完上一节后,我们知晓了attention为循环神经网络带来的优点。那么有没有一种神经网络结构直接基于attention构造,并且不再依赖RNN、LSTM或者CNN网络结构了呢?答案便是:Transformer。因此,我们将在本小节对Transformer所涉及的细节进行深入探讨。
Transformer模型在2017年被google提出,直接基于Self-Attention结构,取代了之前NLP任务中常用的RNN神经网络结构,并在WMT2014 Englishto-German和WMT2014 English-to-French两个机器翻译任务上都取得了当时的SOTA。
与RNN这类神经网络结构相比,Transformer一个巨大的优点是:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。2.1章节详细介绍了RNN神经网络如何循环递归处理输入序列,欢迎读者复习查阅。
下图先便是Transformer整体结构图,与篇章2.1中介绍的seq2seq模型类似,Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder),下面我们来一步步拆解 Transformer。
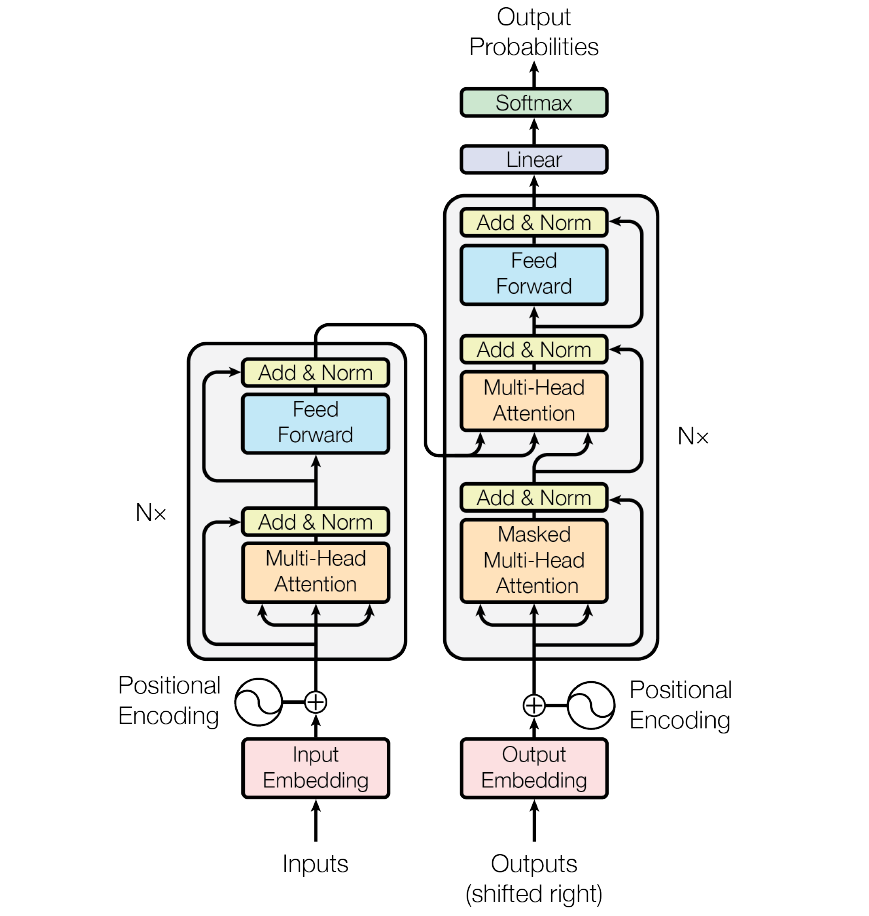
注释和引用说明:本文将通过总-分的方式对Transformer进行拆解和讲解,希望有助于帮助初学者理解Transformer模型结构。本文主要参考illustrated-transformer。
Transformer宏观结构
Transformer最开始提出来解决机器翻译任务,因此可以看作是seq2seq模型的一种。本小节先抛开Transformer模型中结构具体细节,先从seq2seq的角度对Transformer进行宏观结构的学习。以机器翻译任务为例,先将Transformer这种特殊的seqseq模型看作一个黑盒,黑盒的输入是法语文本序列,输出是英语文本序列(对比2.1章节的seq2seq框架知识我们可以发现,Transformer宏观结构属于seq2seq范畴,只是将之前seq2seq中的编码器和解码器,从RNN模型替换成了Transformer模型)。

将上图中的中间部分“THE TRANSFORMER”拆开成seq2seq标准结构,得到下图:左边是编码部分encoders,右边是解码器部分decoders。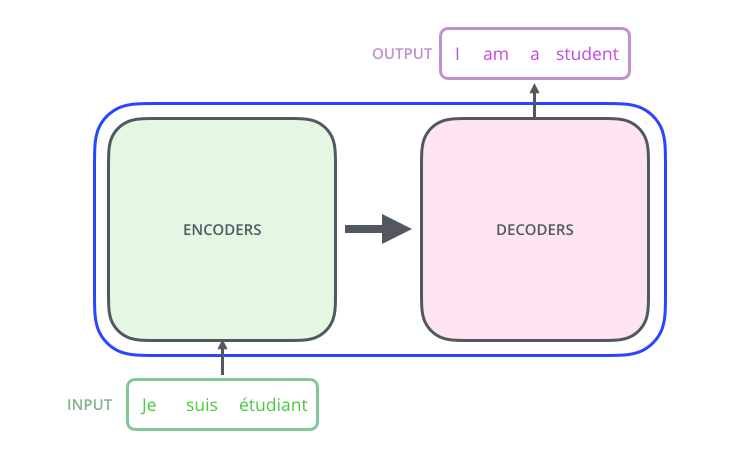
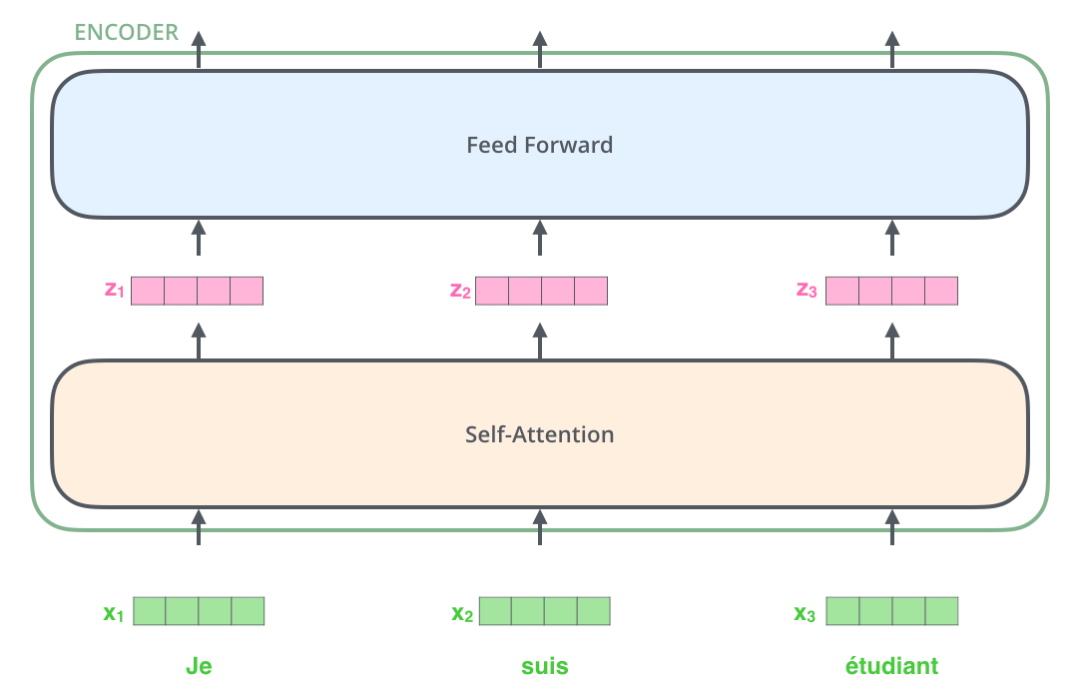
下面,再将上图中的编码器和解码器细节绘出,得到下图。我们可以看到,编码部分(encoders)由多层编码器(Encoder)组成(Transformer论文中使用的是6层编码器,这里的层数6并不是固定的,你也可以根据实验效果来修改层数)。同理,解码部分(decoders)也是由多层的解码器(Decoder)组成(论文里也使用了6层解码器)。每层编码器网络结构是一样的,每层解码器网络结构也是一样的。不同层编码器和解码器网络结构不共享参数。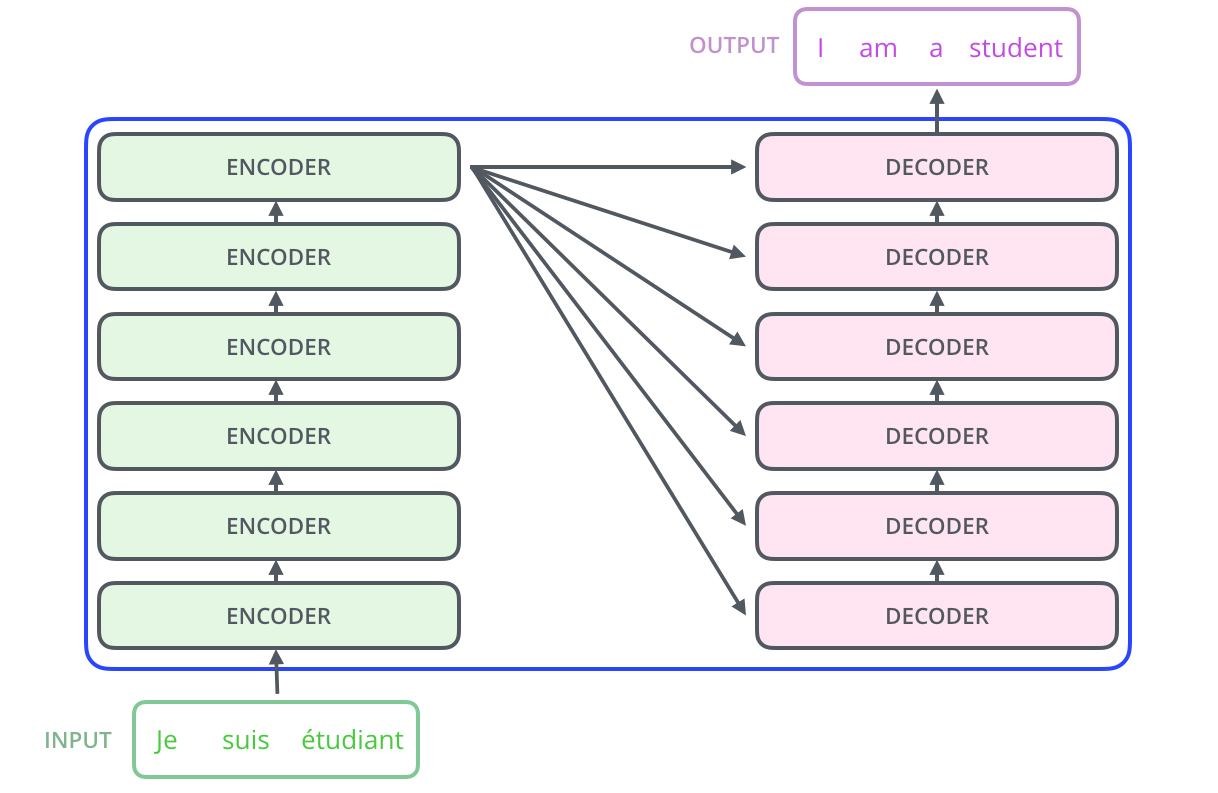
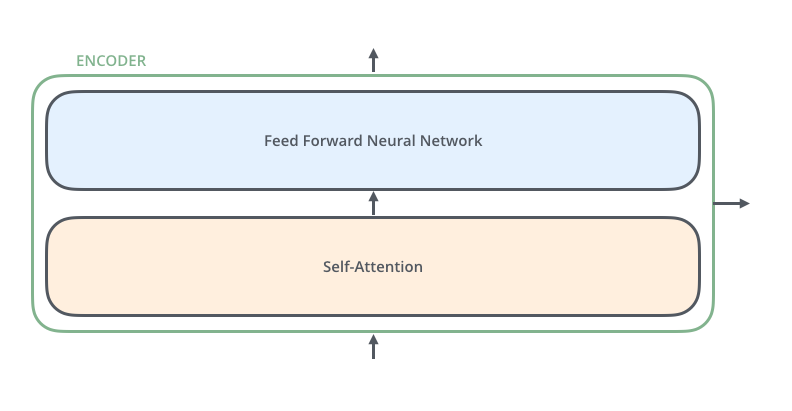
接下来,我们看一下单层encoder,单层encoder主要由以下两部分组成,如下图所示
- Self-Attention Layer
- Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)
编码器的输入文本序列 $w_1, w_2,…,w_n$ 最开始需要经过embedding转换,得到每个单词的向量表示 $x_1, x_2,…,x_n$,其中 $x_i \in \mathbb{R}^{d}$ 是维度为 $d$ 的向量,然后所有向量经过一个Self-Attention神经网络层进行变换和信息交互得到 $h_1, h_2,…h_n$,其中 $h_i \in \mathbb{R}^{d}$ 是维度为 $d$ 的向量。self-attention层处理一个词向量的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息(你可以类比为:当我们翻译一个词的时候,不仅会只关注当前的词,也会关注这个词的上下文的其他词的信息)。Self-Attention层的输出会经过前馈神经网络得到新的 $x_1, x_2,..,x_n$,依旧是 $n$ 个维度为 $d$ 的向量。这些向量将被送入下一层encoder,继续相同的操作。
与编码器对应,如下图,解码器在编码器的 self-attention 和 FFNN 中间插入了一个 Encoder-Decoder Attention 层,这个层帮助解码器聚焦于输入序列最相关的部分(类似于 seq2seq 模型中的 Attention)。
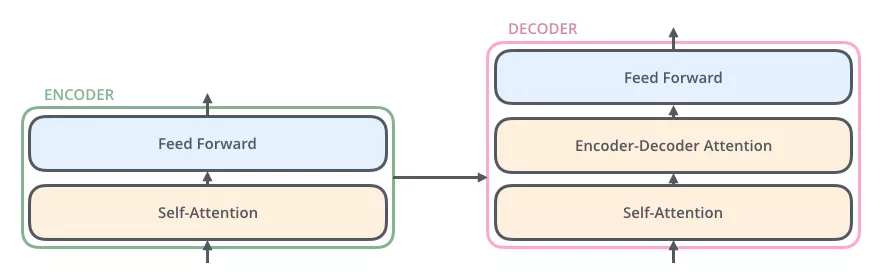
总结一下,我们基本了解了 Transformer 由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由 self-attention 和 FFNN 组成,每个解码层由 self-attention、FFN 和 encoder-decoder attention 组成。
以上便是Transformer的宏观结构啦,下面我们开始看宏观结构中的模型细节。
Transformer结构细节
了解了Transformer的宏观结构之后。下面,让我们来看看Transformer如何将输入文本序列转换为向量表示,又如何逐层处理这些向量表示得到最终的输出。
输入处理
词向量
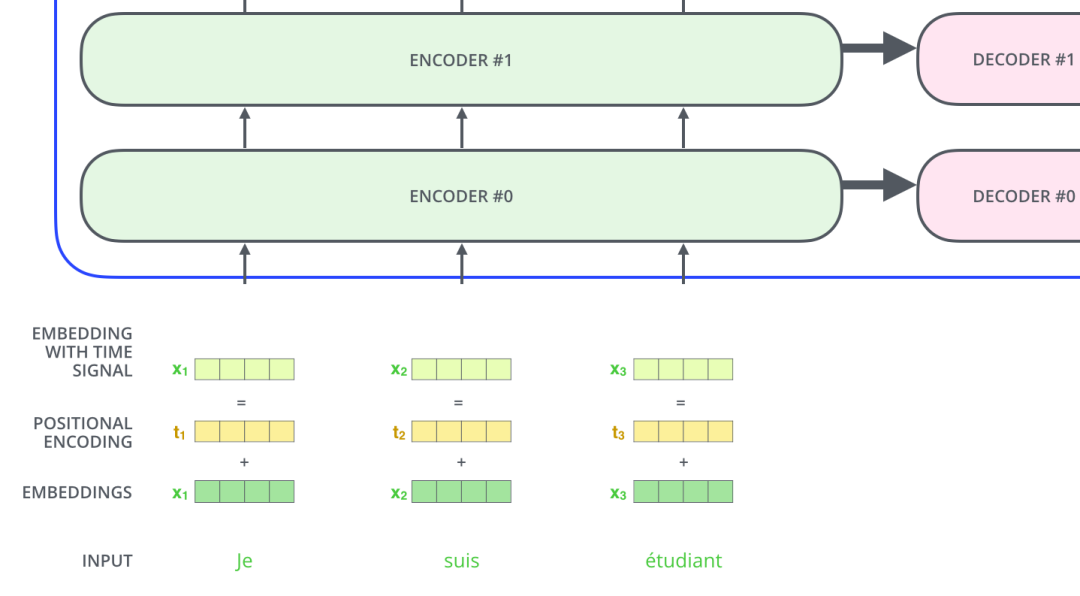
和常见的NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。但为了简化起见,我们这里使用4维的词向量来进行讲解。
如下图所示,假设我们的输入文本是序列包含了3个词,那么每个词可以通过词嵌入算法得到一个4维向量,于是整个输入被转化成为一个向量序列。在实际应用中,我们通常会同时给模型输入多个句子,如果每个句子的长度不一样,我们会选择一个合适的长度,作为输入文本序列的最大长度:如果一个句子达不到这个长度,那么就填充先填充一个特殊的“padding”词;如果句子超出这个长度,则做截断。最大序列长度是一个超参数,通常希望越大越好,但是更长的序列往往会占用更大的训练显存/内存,因此需要在模型训练时候视情况进行决定。

输入序列每个单词被转换成词向量表示还将加上位置向量来得到该词的最终向量表示。
位置向量
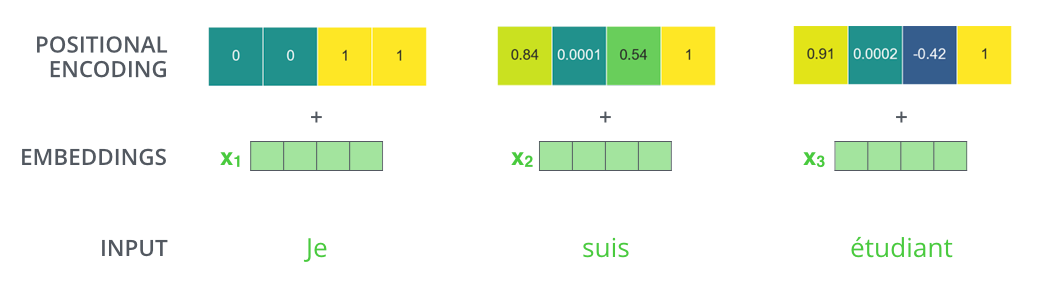
如下图所示,Transformer 模型对每个输入的词向量都加上了一个位置向量。这些向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。词向量加上位置向量背后的直觉是:将这些表示位置的向量添加到词向量中,得到的新向量,可以为模型提供更多有意义的信息,比如词的位置,词之间的距离等。
依旧假设词向量和位置向量的维度是4,我们在下图中展示一种可能的位置向量+词向量:
那么带有位置编码信息的向量到底遵循什么模式?原始论文中给出的设计表达式为:
$$
\begin{equation}\begin{split}
PE_{(pos,2i)} = sin(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}})\\
\\
PE_{(pos,2i+1)} = cos(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}})
\end{split}\end{equation}
$$
上面表达式中的 $pos$ 代表词的位置,$d_{model}$ 代表位置向量的维度,$i \in [0, d_{model})$ 代表位置 $d_{model}$ 维位置向量第 $i$ 维。于是根据上述公式,我们可以得到第 $pos$ 位置的 $d_{model}$ 维位置向量。在下图中,我们画出了一种位置向量在第4、5、6、7维度、不同位置的的数值大小。横坐标表示位置下标,纵坐标表示数值大小。
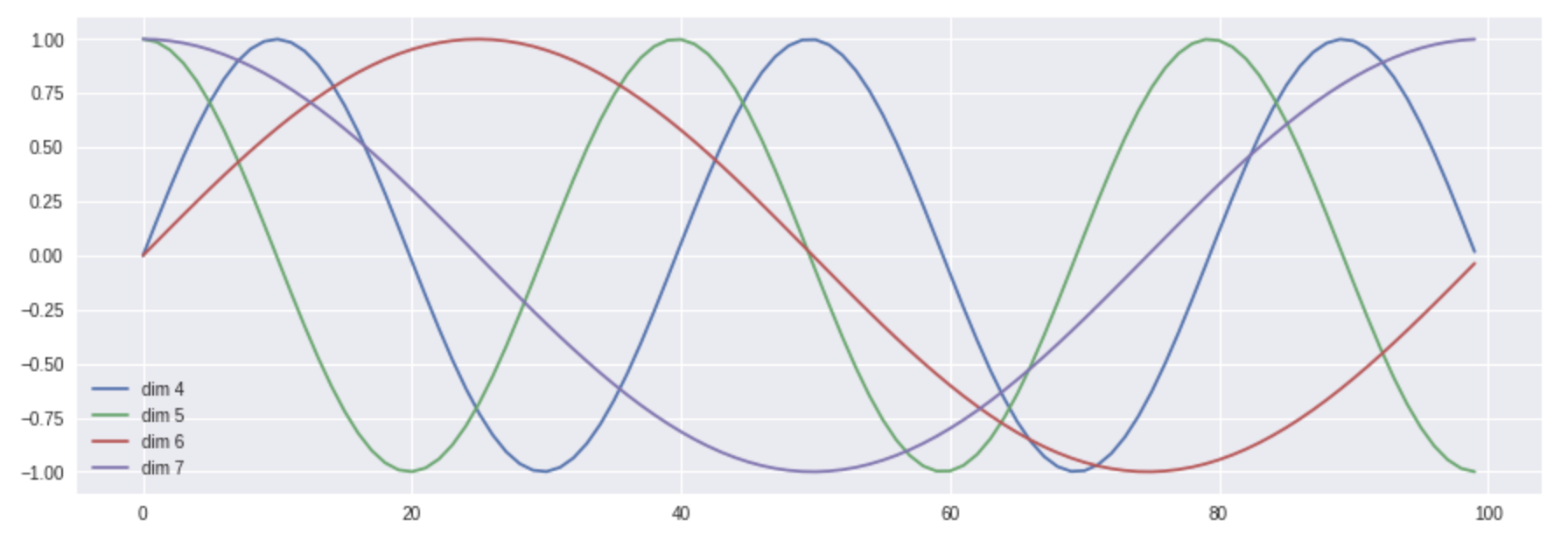
当然,上述公式不是唯一生成位置编码向量的方法。但这种方法的优点是:可以扩展到未知的序列长度。例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。
编码器encoder
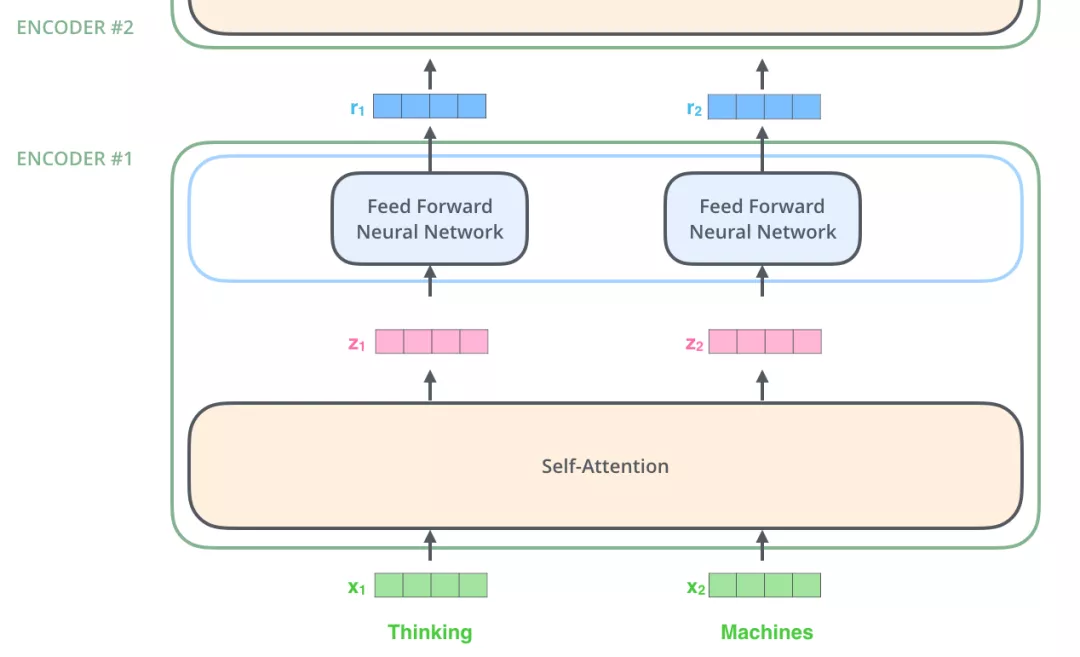
编码部分的输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器,第1层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第1层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
下图展示了向量序列在单层encoder中的流动:融合位置信息的词向量进入self-attention层,self-attention的输出每个位置的向量再输入FFN神经网络得到每个位置的新向量。
下面再看一个2个单词的例子:$x_1, x_2 \to z_1, z_2 \to r_1, r_2$
Self-Attention层
下面来分析一下上图中Self-Attention层的具体机制。
Self-Attention概览
假设我们想要翻译的句子是:
1 | |
这个句子中的 it 是一个指代词,那么 it 指的是什么呢?它是指 animal 还是street?这个问题对人来说,是很简单的,但是对模型来说并不是那么容易。但是,如果模型引入了Self Attention机制之后,便能够让模型把it和animal关联起来了。同样的,当模型处理句子中其他词时,Self Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
与2.1章节中提到的RNN对比一下:RNN 在处理序列中的一个词时,会考虑句子前面的词传过来的hidden state,而hidden state就包含了前面的词的信息;而Self Attention机制值得是,当前词会直接关注到自己句子中前后相关的所有词语,如下图 it的例子:

图:一个词和其他词的attention
上图所示的it是一个真实的例子,是当Transformer在第5层编码器编码“it”时的状态,可视化之后显示it有一部分注意力集中在了“The animal”上,并且把这两个词的信息融合到了”it”中。
Self-Attention细节
先通过一个简单的例子来理解一下:什么是“self-attention自注意力机制”?假设一句话包含两个单词:Thinking Machines。自注意力的一种理解是:Thinking-Thinking,Thinking-Machines,Machines-Thinking,Machines-Machines,共$2^2$种两两attention。那么具体如何计算呢?假设Thinking、Machines这两个单词经过词向量算法得到向量是$X_1, X_2$:
$$
\begin{equation}\begin{split}
1:&q_1 = X_1 W^Q, q_2 = X_2 W^Q\\
\\
&k_1 = X_1 W^K, k_2 = X_2 W^K\\
\\
&v_1 = X_1 W^V, v_2 = X_2 W^V\\
\\
&W^Q, W^K, W^K \in \mathbb{R}^{d_x \times d_k}\\
\\
2-3:&score_{11} = \frac{q_1 \cdot q_1}{\sqrt{d_k}}\\
\\
&score_{12} = \frac{q_1 \cdot q_2}{\sqrt{d_k}}\\
\\
&score_{21} = \frac{q_2 \cdot q_1}{\sqrt{d_k}}\\
\\
&score_{22} = \frac{q_2 \cdot q_2}{\sqrt{d_k}}\\
\\
4:&score_{11} = \frac{e^{score_{11}}}{e^{score_{11}} + e^{score_{12}}}\\
\\
&score_{12} = \frac{e^{score_{12}}}{e^{score_{11}} + e^{score_{12}}}\\
\\
&score_{21} = \frac{e^{score_{21}}}{e^{score_{21}} + e^{score_{22}}}\\
\\
&score_{22} = \frac{e^{score_{22}}}{e^{score_{21}} + e^{score_{22}}} \\
\\
5-6:&z_1 = v_1 \times score_{11} + v_2 \times score_{12}\\
\\
&z_2 = v_1 \times score_{21} + v_2 \times score_{22}
\end{split}\end{equation}
$$
下面,我们将上诉self-attention计算的6个步骤进行可视化。
第1步:对输入编码器的词向量进行线性变换得到:Query向量: $q_1, q_2$,Key向量: $k_1, k_2$,Value向量: $v_1, v_2$。这3个向量是词向量分别和3个参数矩阵相乘得到的,而这个矩阵也是是模型要学习的参数。
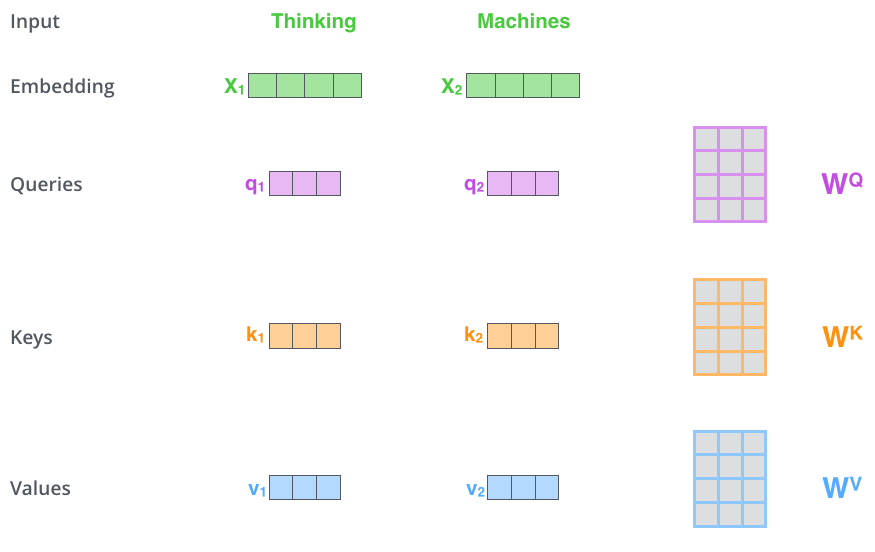
Query 向量,Key 向量,Value 向量是什么含义呢?
其实它们就是 3 个向量,给它们加上一个名称,可以让我们更好地理解 Self-Attention 的计算过程和逻辑。attention计算的逻辑常常可以描述为:query和key计算相关或者叫attention得分,然后根据attention得分对value进行加权求和。
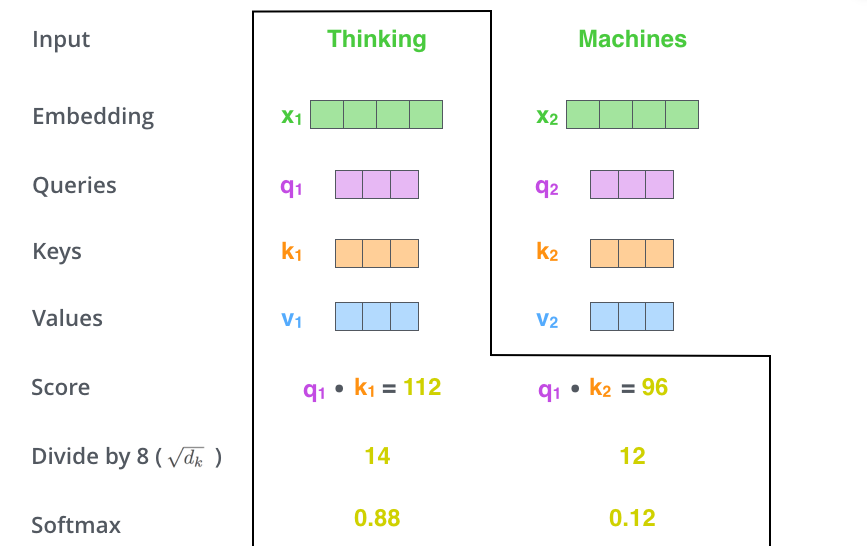
第2步:计算Attention Score(注意力分数)。假设我们现在计算第一个词Thinking的Attention Score(注意力分数),需要根据Thinking 对应的词向量,对句子中的其他词向量都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的词向量的权重。
Attention score是根据”Thinking“对应的 Query 向量和其他位置的每个词的 Key 向量进行点积得到的。Thinking的第一个Attention Score就是$q_1$和$k_1$的内积,第二个分数就是$q_1$和$k_2$的点积。这个计算过程在下图中进行了展示,下图里的具体得分数据是为了表达方便而自定义的。

第3步:把每个分数除以 $\sqrt{d_k}$,$d_{k}$是Key向量的维度。你也可以除以其他数,除以一个数是为了在反向传播时,求梯度时更加稳定。
第4步:接着把这些分数经过一个Softmax函数,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于1, 如下图所示。
这些分数决定了Thinking词向量,对其他所有位置的词向量分别有多少的注意力。
第5步:得到每个词向量的分数后,将分数分别与对应的Value向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的。
第6步:把第5步得到的Value向量相加,就得到了Self Attention在当前位置(这里的例子是第1个位置)对应的输出。
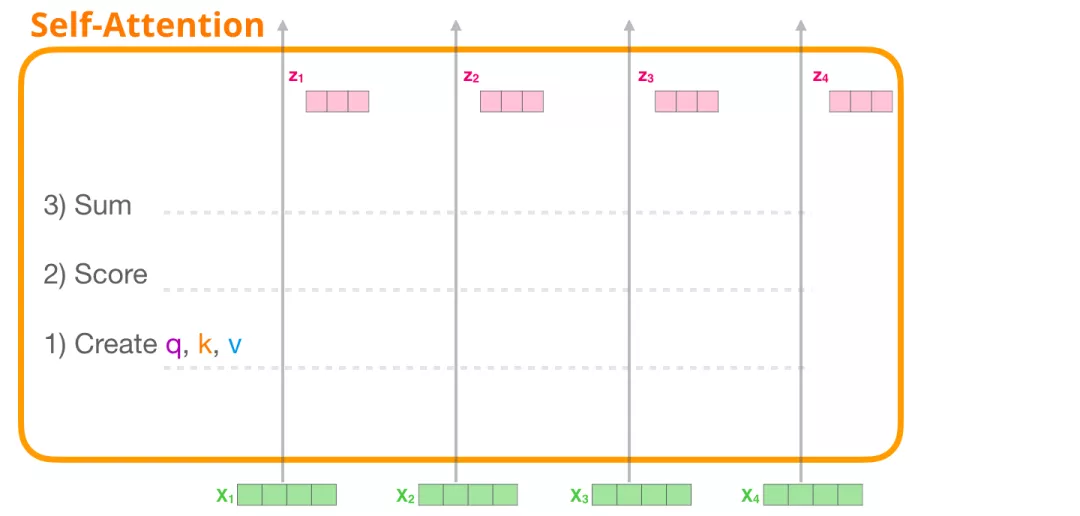
最后,在下图展示了 对第一个位置词向量计算Self Attention 的全过程。最终得到的当前位置(这里的例子是第一个位置)词向量会继续输入到前馈神经网络。注意:上面的6个步骤每次只能计算一个位置的输出向量,在实际的代码实现中,Self Attention的计算过程是使用矩阵快速计算的,一次就得到所有位置的输出向量。
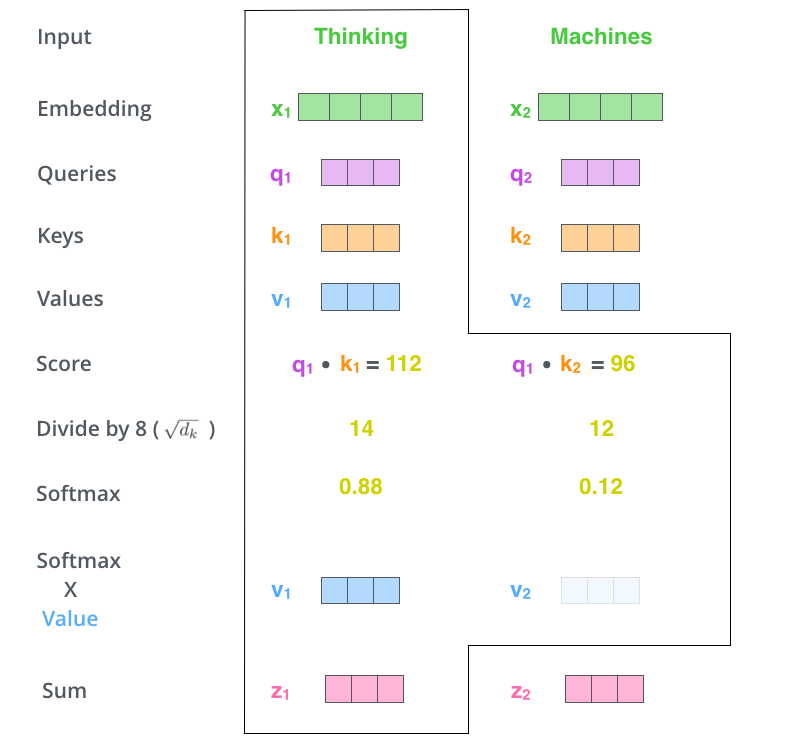
Self-Attention矩阵计算
将self-attention计算6个步骤中的向量放一起,比如$X=[x_1;x_2]$,便可以进行矩阵计算啦。下面,依旧按步骤展示self-attention的矩阵计算方法。
$$
\begin{equation}\begin{split}
X &= [X_1;X_2]\\
\\
Q &= X W^Q\\
K &= X W^K\\
V&=X W^V \\
\\
Z &= softmax(\frac{QK^T}{\sqrt{d_k}}) V
\end{split}\end{equation}
$$
第1步:计算 Query,Key,Value 的矩阵。首先,我们把所有词向量放到一个矩阵X中,然后分别和3个权重矩阵$W^Q, W^K W^V$ 相乘,得到 Q,K,V 矩阵。矩阵X中的每一行,表示句子中的每一个词的词向量。Q,K,V 矩阵中的每一行表示 Query向量,Key向量,Value 向量,向量维度是$d_k$。
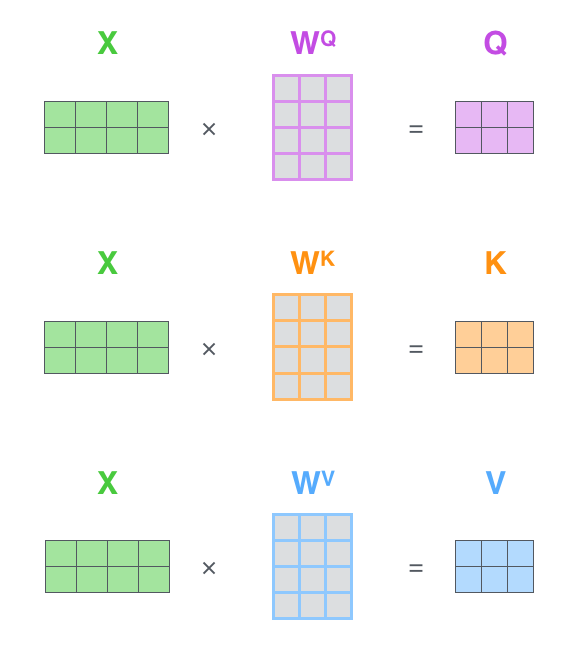
第2步:由于我们使用了矩阵来计算,我们可以把上面的第 2 步到第 6 步压缩为一步,直接得到 Self Attention 的输出。
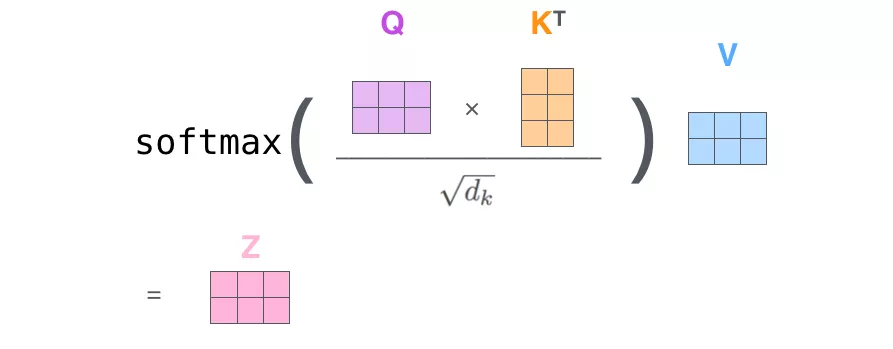
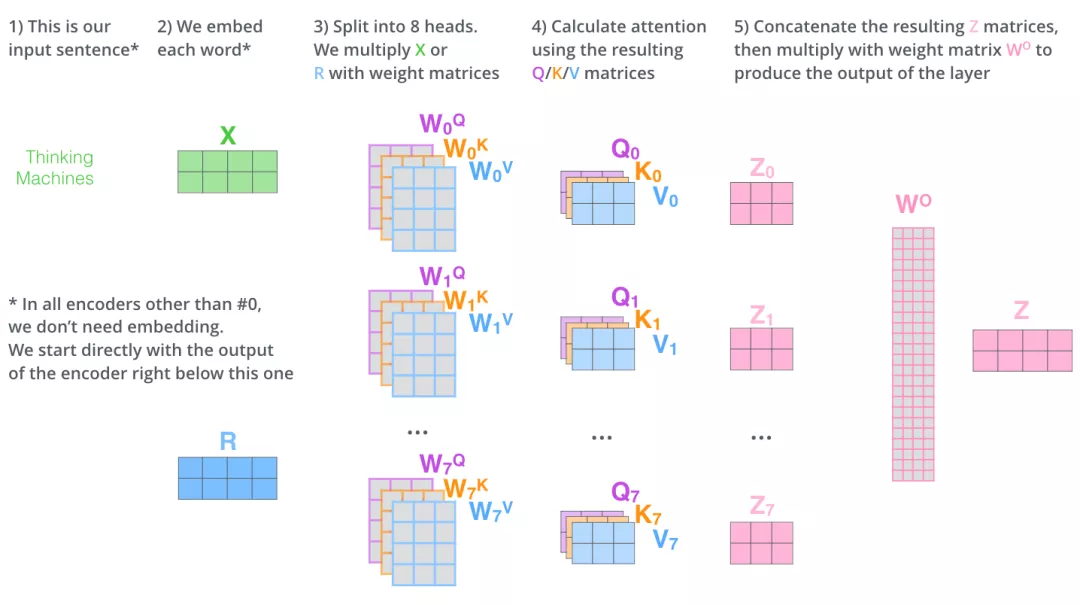
多头注意力机制
Transformer 的论文通过增加多头注意力机制(一组注意力称为一个 attention head),进一步完善了Self-Attention。这种机制从如下两个方面增强了attention层的能力:
- 它扩展了模型关注不同位置的能力。在上面的例子中,第一个位置的输出$z_1$包含了句子中其他每个位置的很小一部分信息,但$z_1$仅仅是单个向量,所以可能仅由第1个位置的信息主导了。而当我们翻译句子:
The animal didn’t cross the street because it was too tired时,我们不仅希望模型关注到”it”本身,还希望模型关注到”The”和“animal”,甚至关注到”tired”。这时,多头注意力机制会有帮助。 - 多头注意力机制赋予attention层多个“子表示空间”。下面我们会看到,多头注意力机制会有多组$W^Q, W^K W^V$ 的权重矩阵(在 Transformer 的论文中,使用了 8 组注意力),,因此可以将$X$变换到更多种子空间进行表示。接下来我们也使用8组注意力头(attention heads))。每一组注意力的权重矩阵都是随机初始化的,但经过训练之后,每一组注意力的权重$W^Q, W^K W^V$ 可以把输入的向量映射到一个对应的”子表示空间“。
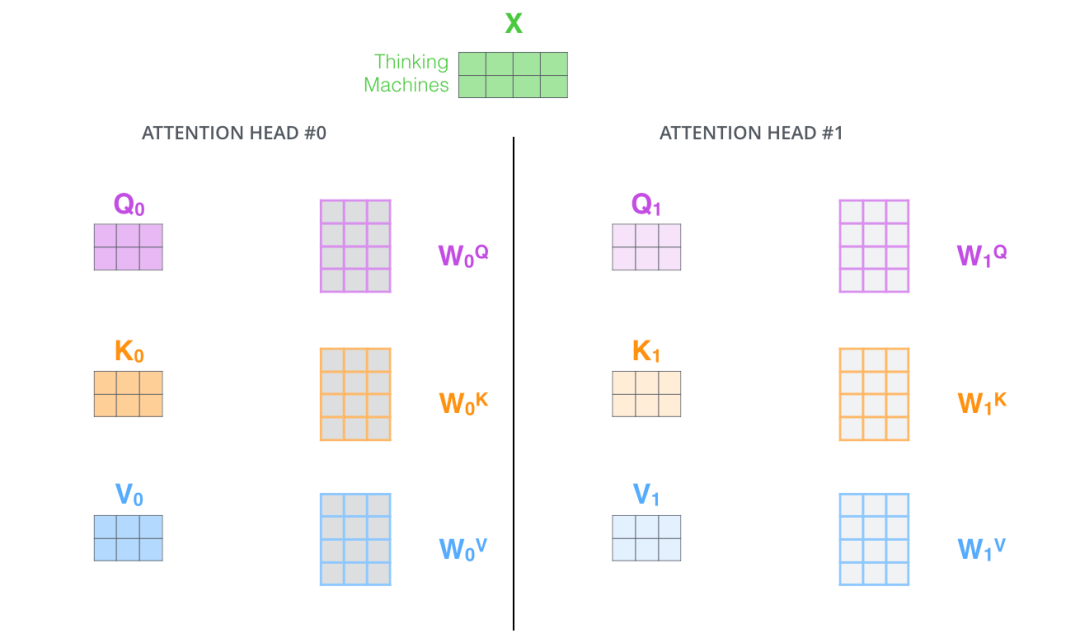
在多头注意力机制中,我们为每组注意力设定单独的 WQ, WK, WV 参数矩阵。将输入X和每组注意力的WQ, WK, WV 相乘,得到8组 Q, K, V 矩阵。
接着,我们把每组 K, Q, V 计算得到每组的 Z 矩阵,就得到8个Z矩阵。
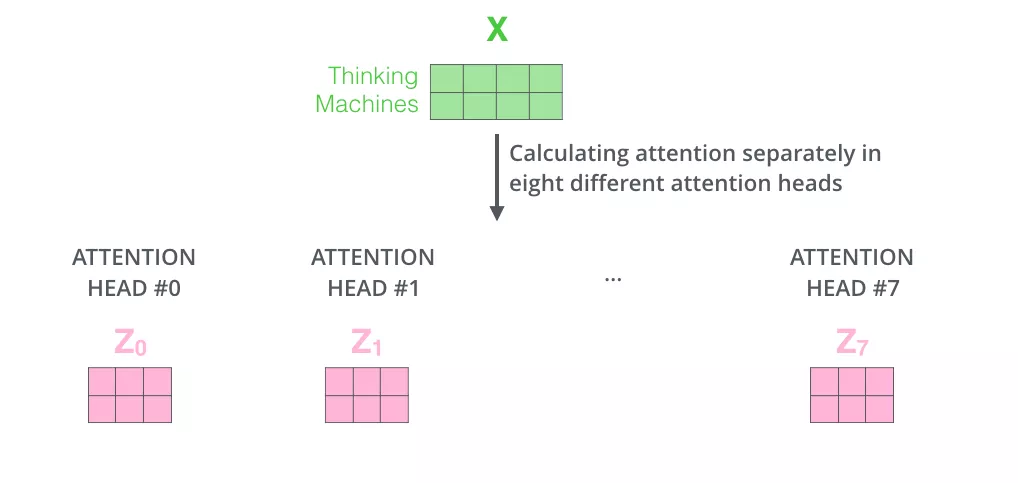
由于前馈神经网络层接收的是 1 个矩阵(其中每行的向量表示一个词),而不是 8 个矩阵,所以我们直接把8个子矩阵拼接起来得到一个大的矩阵,然后和另一个权重矩阵$W^O$相乘做一次变换,映射到前馈神经网络层所需要的维度。
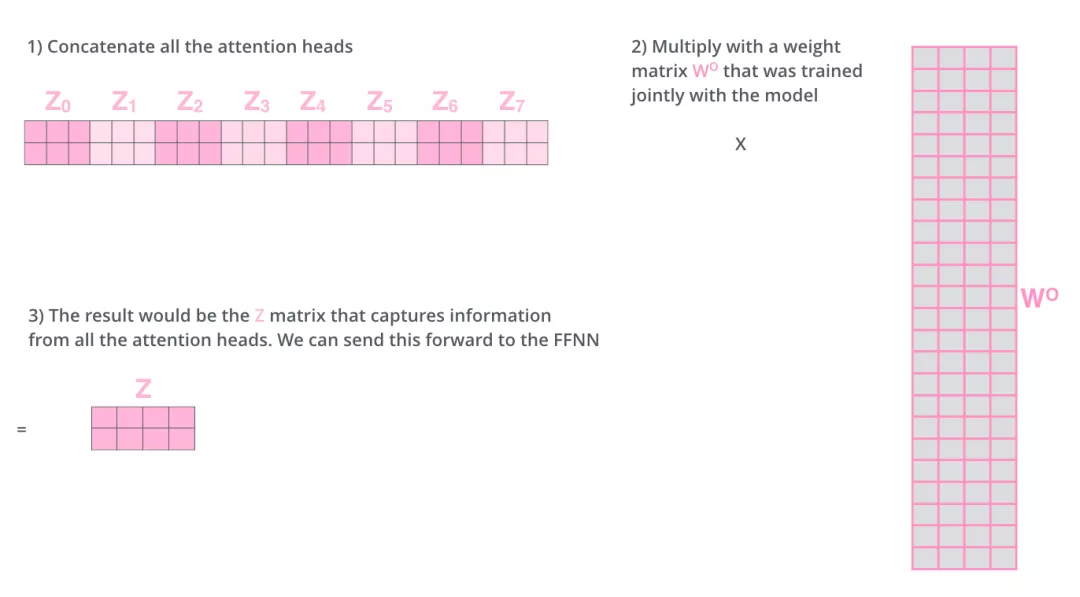
总结一下就是:
- 把8个矩阵 {Z0,Z1…,Z7} 拼接起来
- 把拼接后的矩阵和WO权重矩阵相乘
- 得到最终的矩阵Z,这个矩阵包含了所有 attention heads(注意力头) 的信息。这个矩阵会输入到FFNN (Feed Forward Neural Network)层。
以上就是多头注意力的全部内容。最后将所有内容放到一张图中:
学习了多头注意力机制,让我们再来看下当我们前面提到的it例子,不同的attention heads (注意力头)对应的“it”attention了哪些内容。下图中的绿色和橙色线条分别表示2组不同的attentin heads:
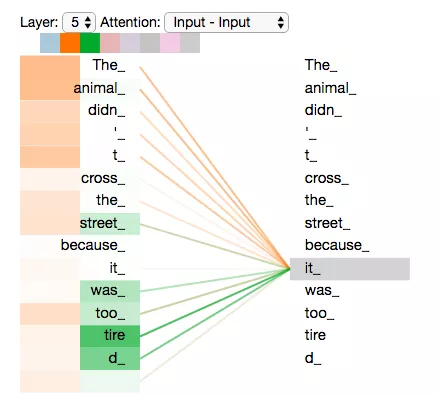
当我们编码单词”it”时,其中一个 attention head (橙色注意力头)最关注的是”the animal”,另外一个绿色 attention head 关注的是”tired”。因此在某种意义上,”it”在模型中的表示,融合了”animal”和”tire”的部分表达。
Attention代码实例
下面的代码实现中,张量的第1维是 batch size,第 2 维是句子长度。代码中进行了详细注释和说明。
1 | |
残差连接
到目前为止,我们计算得到了self-attention的输出向量。而单层encoder里后续还有两个重要的操作:残差链接、标准化。
编码器的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization),如下图所示。
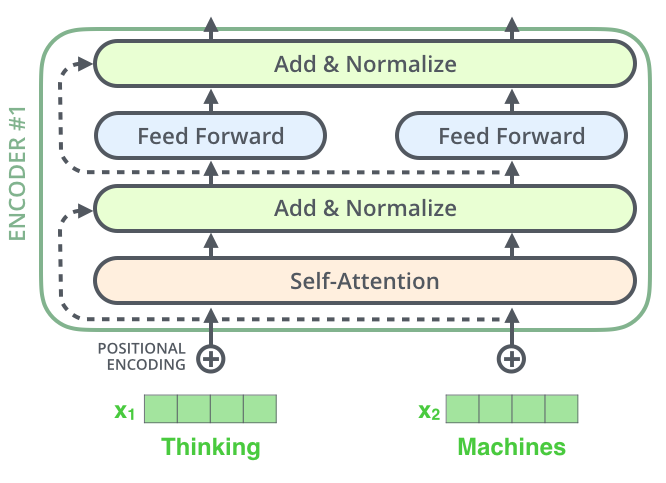
将 Self-Attention 层的层标准化(layer-normalization)和涉及的向量计算细节都进行可视化,如下所示:
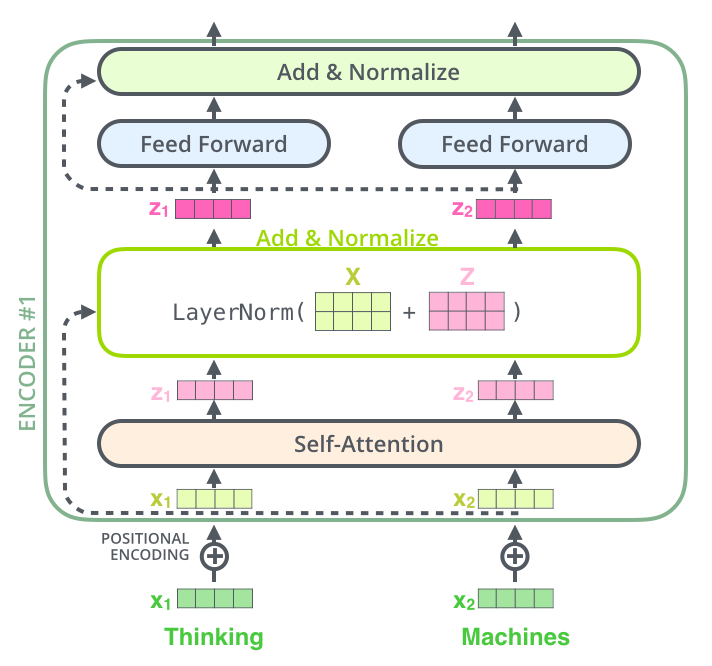
编码器和和解码器的子层里面都有层标准化(layer-normalization)。假设一个 Transformer 是由 2 层编码器和两层解码器组成的,将全部内部细节展示起来如下图所示。
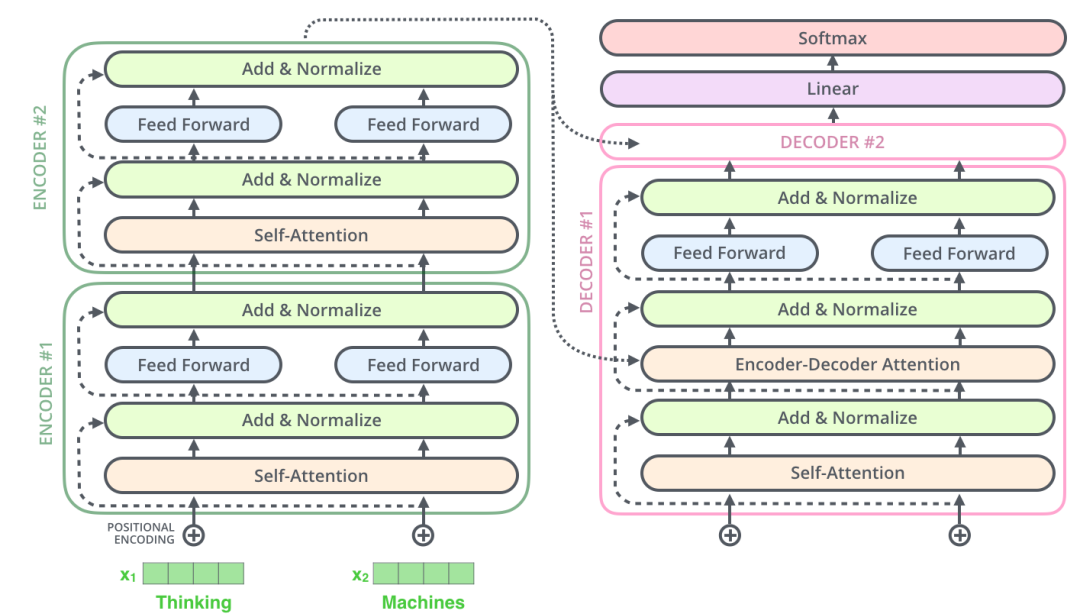
解码器
现在我们已经介绍了编码器中的大部分概念,我们也基本知道了编码器的原理。现在让我们来看下, 编码器和解码器是如何协同工作的。
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的K、V输入,其中K=V=解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的Encoder-Decoder Attention层,这有助于解码器把注意力集中到输入序列的合适位置,如下图所示。
![]()
解码(decoding )阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译),解码器当前时间步的输出又重新作为输入Q和编码器的输出K、V共同作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符。如下图所示:
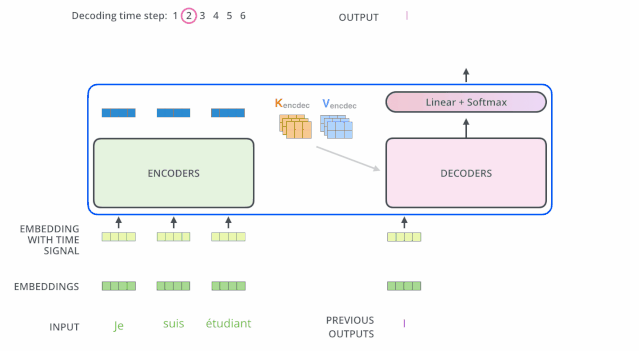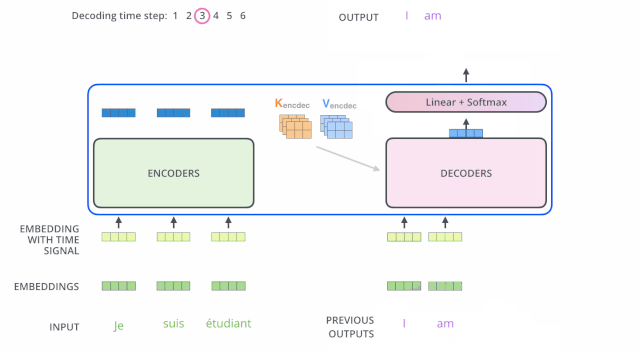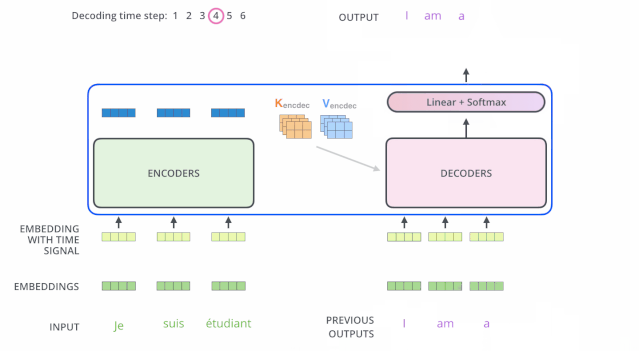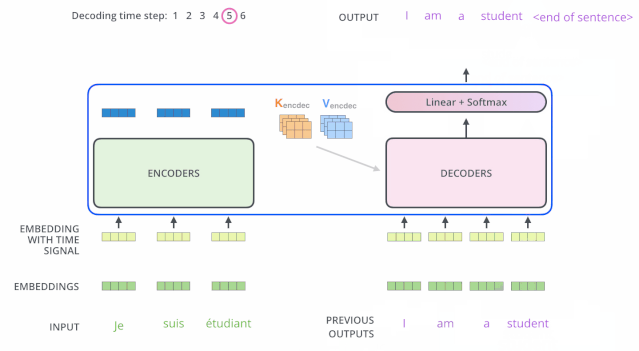
解码器中的 Self Attention 层,和编码器中的 Self Attention 层的区别:
- 在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将attention score设置成-inf)。
- 解码器 Attention层是使用前一层的输出来构造Query 矩阵,而Key矩阵和 Value矩阵来自于编码器最终的输出。
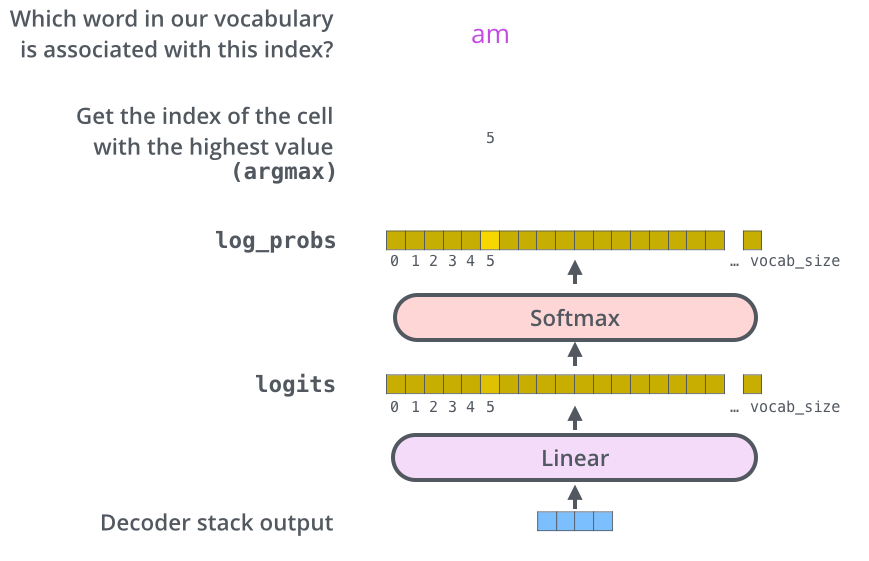
线性层和softmax
Decoder 最终的输出是一个向量,其中每个元素是浮点数。我们怎么把这个向量转换为单词呢?这是线性层和softmax完成的。
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为 logits 向量:假设我们的模型有 10000 个英语单词(模型的输出词汇表),此 logits 向量便会有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
损失函数
Transformer训练的时候,需要将解码器的输出和label一同送入损失函数,以获得loss,最终模型根据loss进行方向传播。这一小节,我们用一个简单的例子来说明训练过程的loss计算:把“merci”翻译为“thanks”。
我们希望模型解码器最终输出的概率分布,会指向单词 ”thanks“(在“thanks”这个词的概率最高)。但是,一开始模型还没训练好,它输出的概率分布可能和我们希望的概率分布相差甚远,如下图所示,正确的概率分布应该是“thanks”单词的概率最大。但是,由于模型的参数都是随机初始化的,所示一开始模型预测所有词的概率几乎都是随机的。
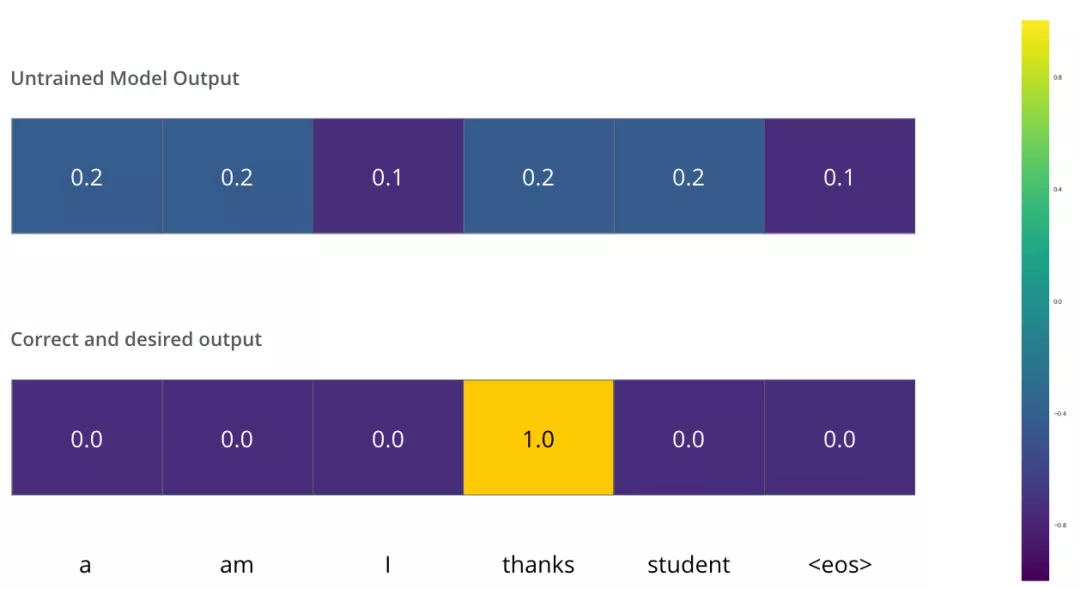
只要Transformer解码器预测了组概率,我们就可以把这组概率和正确的输出概率做对比,然后使用反向传播来调整模型的权重,使得输出的概率分布更加接近整数输出。
那我们要怎么比较两个概率分布呢?:我们可以简单的用两组概率向量的的空间距离作为loss(向量相减,然后求平方和,再开方),当然也可以使用交叉熵(cross-entropy)]和KL 散度(Kullback–Leibler divergence)。读者可以进一步检索阅读相关知识,损失函数的知识不在本小节展开。
由于上面仅有一个单词的例子太简单了,我们可以再看一个复杂一点的句子。句子输入是:“je suis étudiant” ,输出是:“i am a student”。这意味着,我们的transformer模型解码器要多次输出概率分布向量:
- 每次输出的概率分布都是一个向量,长度是 vocab_size(前面约定最大vocab size,也就是向量长度是 6,但实际中的vocab size更可能是 30000 或者 50000)
- 第1次输出的概率分布中,最高概率对应的单词是 “i”
- 第2次输出的概率分布中,最高概率对应的单词是 “am”
- 以此类推,直到第 5 个概率分布中,最高概率对应的单词是 “<eos>”,表示没有下一个单词了
于是我们目标的概率分布长下面这个样子:
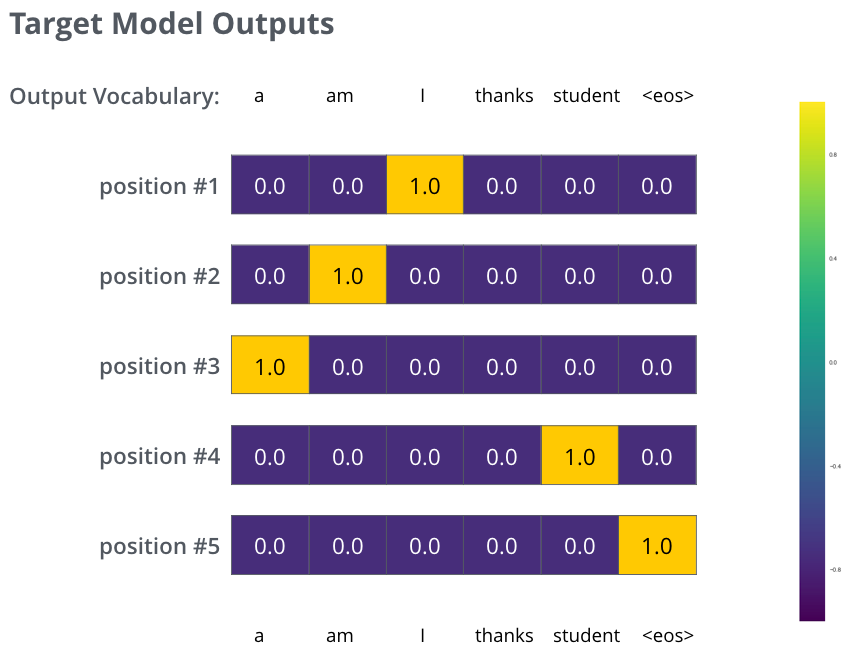
我们用例子中的句子训练模型,希望产生图中所示的概率分布
我们的模型在一个足够大的数据集上,经过足够长时间的训练后,希望输出的概率分布如下图所示:
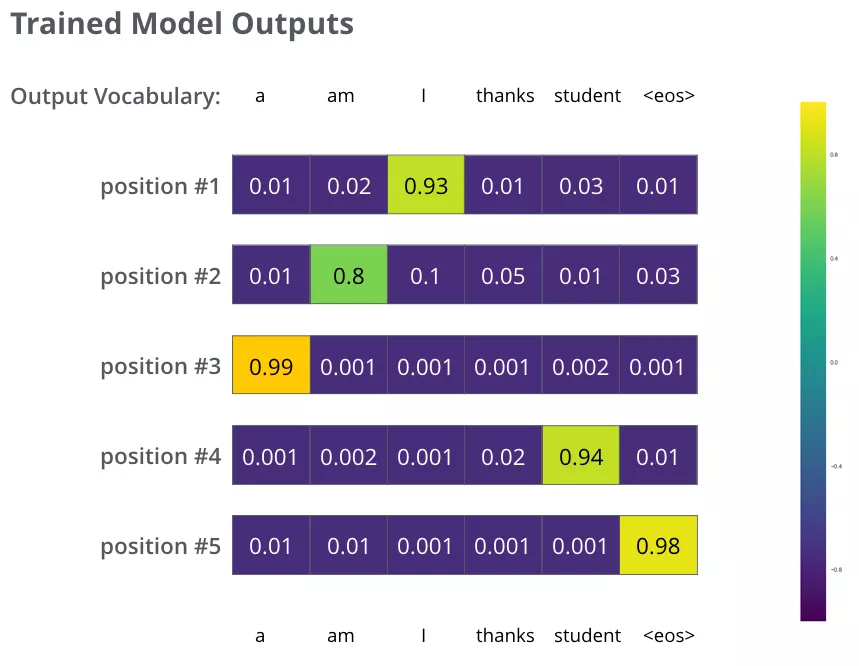
我们希望模型经过训练之后可以输出的概率分布也就对应了正确的翻译。当然,如果你要翻译的句子是训练集中的一部分,那输出的结果并不能说明什么。我们希望模型在没见过的句子上也能够准确翻译。
额外提一下greedy decoding和beam search的概念:
- Greedy decoding:由于模型每个时间步只产生一个输出,我们这样看待:模型是从概率分布中选择概率最大的词,并且丢弃其他词。这种方法叫做贪婪解码(greedy decoding)。
- Beam search:每个时间步保留k个最高概率的输出词,然后在下一个时间步,根据上一个时间步保留的k个词来确定当前应该保留哪k个词。假设k=2,第一个位置概率最高的两个输出的词是”I“和”a“,这两个词都保留,然后根据第一个词计算第2个位置的词的概率分布,再取出第2个位置上2个概率最高的词。对于第3个位置和第4个位置,我们也重复这个过程。这种方法称为集束搜索(beam search)。
图解BERT
在学习完Transformer之后,我们来学习一下将Transformer模型结构发扬光大的一个经典模型:BERT。
站在2021年来看,2018年是自然语言处理技术的一个转折点,运用深度学习技术处理文本的能力通过预训练模型被极大的发挥了出来。同时,伴随着NLP开源社区的贡献,很多强大的模型被封装成组件,让NLP初学者也有机会在各种NLP任务上取得非常好的效果。在众多NLP预训练模型里,最经典的基本就是BERT和GPT了,因此本文将开始对BERT(单篇文章的citation已经接近2万)的学习。
BERT在2018年被提出,BERT模型一出现就打破了多个自然语言处理任务的最好记录。BERT的论文发布不久后,BERT团队公开了模型的代码,并提供了基于大规模新书数据集预训练完成的模型下载。BERT的模型代码和模型参数的开源,使得任何一个NLP从业者,都可以基于这个强大的模型组件搭建自己的NLP系统,也节省了从零开始训练语言处理模型所需要的时间、精力、知识和资源。
那么BERT具体干了一件什么事情呢?如下图所示,BERT首先在大规模无监督语料上进行预训练,然后在预训练好的参数基础上增加一个与任务相关的神经网络层,并在该任务的数据上进行微调训,最终取得很好的效果。BERT的这个训练过程可以简述为:预训练+微调(finetune),已经成为最近几年最流行的NLP解决方案的范式。
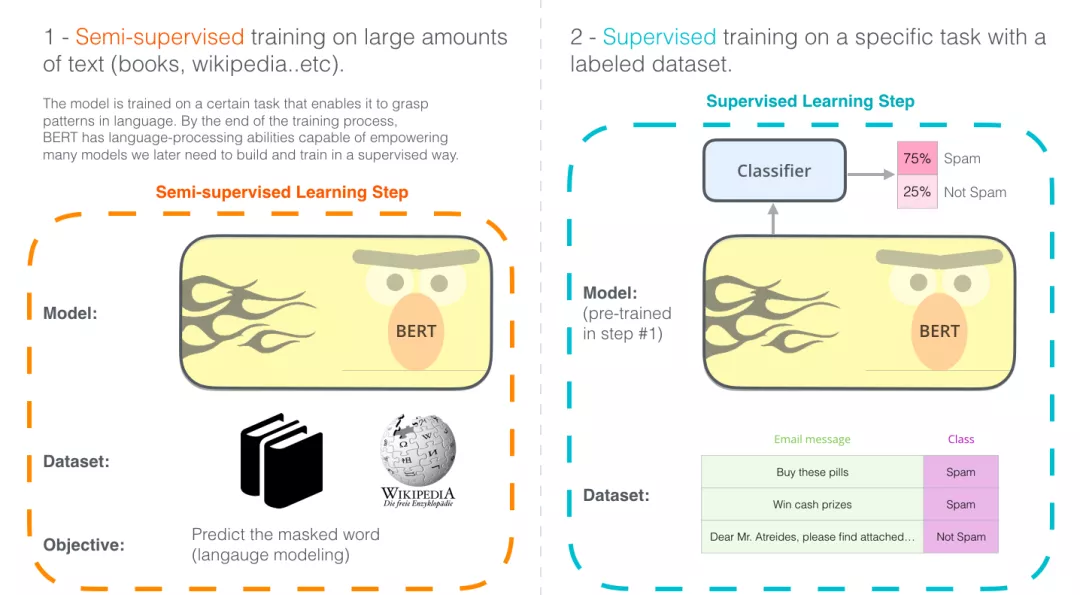
BERT句子分类
要想很好的理解BERT,最好先理解一下BERT的使用场景,明确一下输入和输出,最后再详细学习BERT的内在模型结构和训练方法。因此,在介绍模型本身涉及的BERT相关概念之前,让我们先看看如何直接应用BERT。
- 下载在无监督语料上预训练好的BERT模型,一般来说对应了3个文件:BERT模型配置文件(用来确定Transformer的层数,隐藏层大小等),BERT模型参数,BERT词表(BERT所能处理的所有token)。
- 针对特定任务需要,在BERT模型上增加一个任务相关的神经网络,比如一个简单的分类器,然后在特定任务监督数据上进行微调训练。(微调的一种理解:学习率较小,训练epoch数量较少,对模型整体参数进行轻微调整)
先来看一下如何使用BERT进行句子分类,
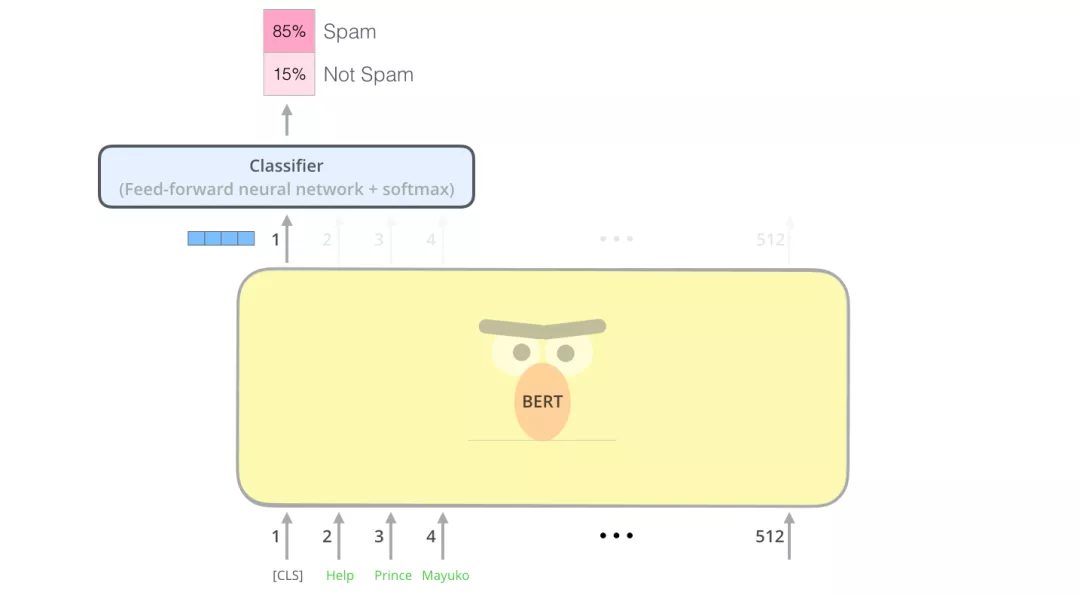
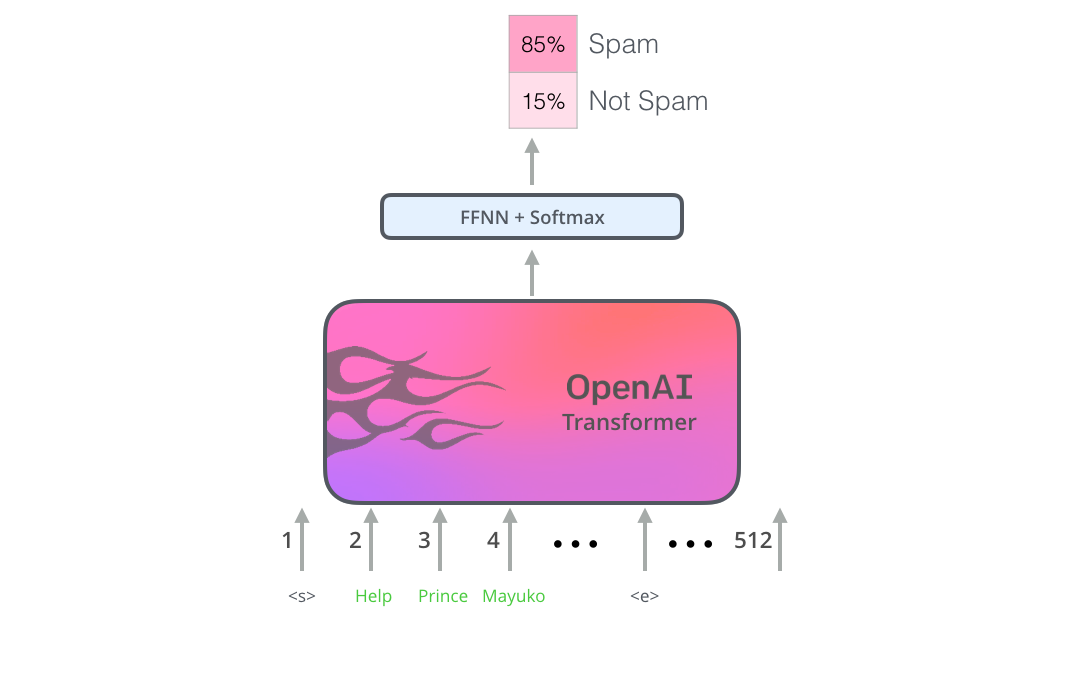
假设我们的句子分类任务是:判断一个邮件是“垃圾邮件”或者“非垃圾邮件”,如下图所示。当然除了垃圾邮件判断,也可以是其他NLP任务,比如:
- 输入:电影或者产品的评价。输出:判断这个评价是正面的还是负面的。
- 输入:两句话。输出:两句话是否是同一个意思。

图:垃圾邮件分类
如下图所示,为了能够使用BERT进行句子分类,我们在BERT模型上增加一个简单的classifier层,由于这一层神经网络参数是新添加的,一开始只能随机初始化它的参数,所以需要用对应的监督数据来训练这个classifier。由于classifier是连接在BERT模型之上的,训练的时候也可以更新BERT的参数。
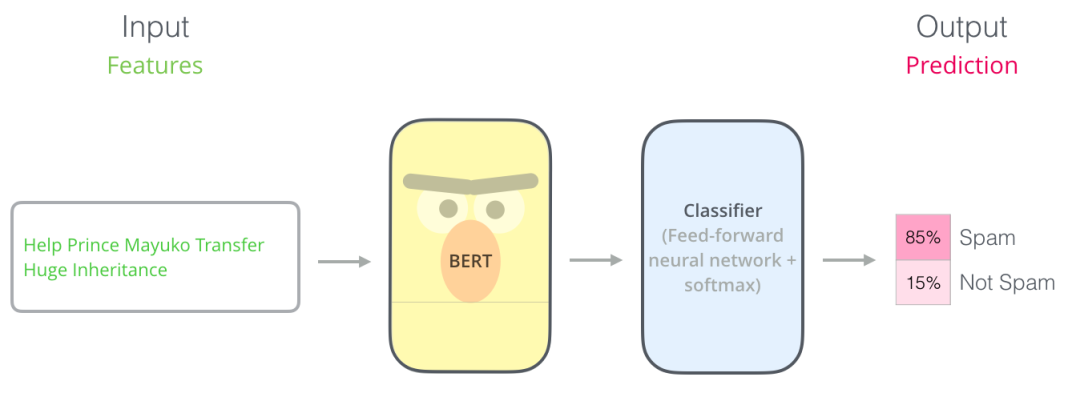
模型结构
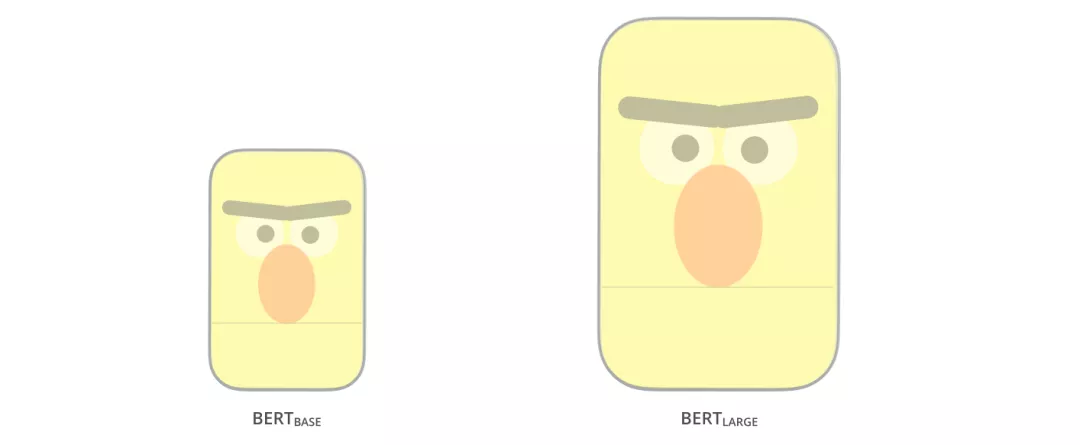
通过上面的例子,了解了如何使用BERT,接下来让我们更深入地了解一下它的工作原理。BERT原始论文提出了BERT-base和BERT—large两个模型,base的参数量比large少一些,可以形象的表示为下图的样子。
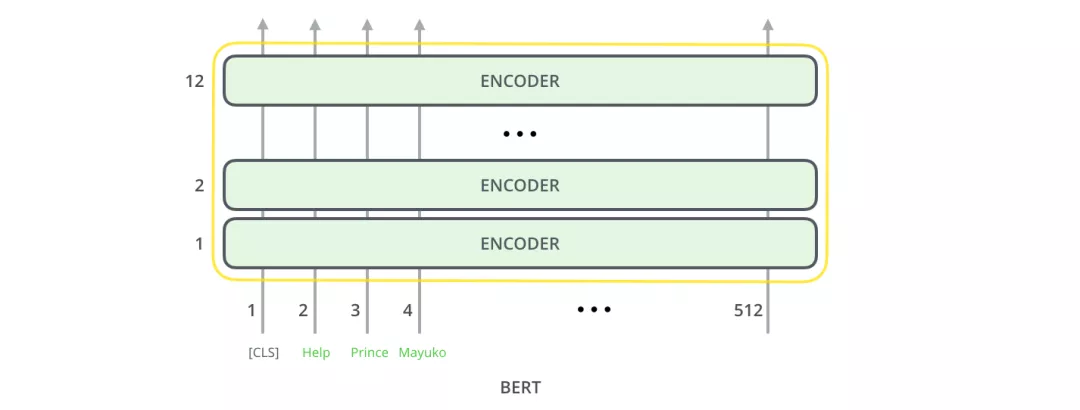
回顾一下篇章2.2的Transformer,BERT模型结构基本上就是Transformer的encoder部分,BERT-base对应的是12层encoder,BERT-large对应的是24层encoder。
模型输入
接着看一下模型的输入和输出:BERT模型输入有一点特殊的地方是在一句话最开始拼接了一个[CLS] token,如下图所示。这个特殊的[CLS] token经过BERT得到的向量表示通常被用作当前的句子表示。除了这个特殊的[CLS] token,其余输入的单词类似篇章2.2的Transformer。BERT将一串单词作为输入,这些单词在多层encoder中不断向上流动,每一层都会经过 Self-Attention和前馈神经网络。
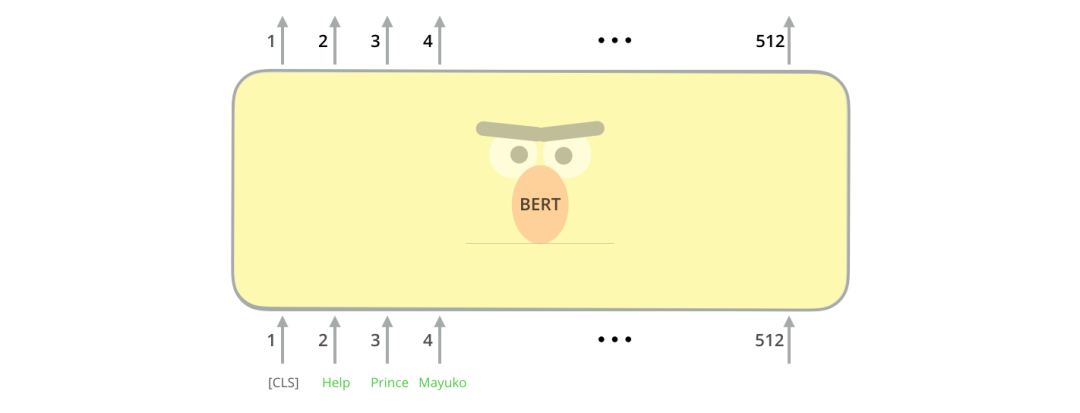
模型输出
BERT输入的所有token经过BERT编码后,会在每个位置输出一个大小为 hidden_size(在 BERT-base中是 768)的向量。
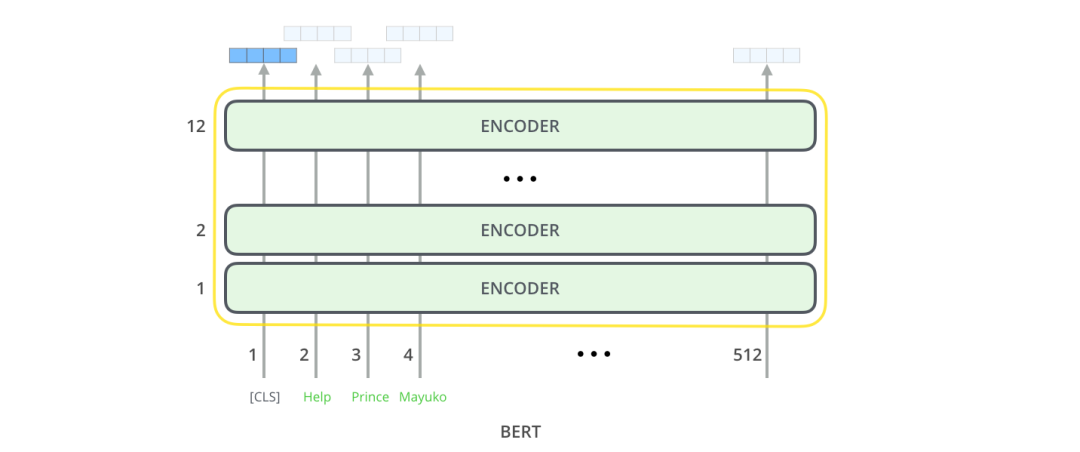
对于上面提到的句子分类的例子,我们直接使用第1个位置的向量输出(对应的是[CLS])传入classifier网络,然后进行分类任务,如下图所示。
预训练任务:Masked Language Model
知道了模型输入、输出、Transformer结构,那么BERT是如何无监督进行训练的呢?如何得到有效的词、句子表示信息呢?以往的NLP预训练通常是基于语言模型进行的,比如给定语言模型的前3个词,让模型预测第4个词。但是,BERT是基于Masked language model进行预训练的:将输入文本序列的部分(15%)单词随机Mask掉,让BERT来预测这些被Mask的词语。如下图所示: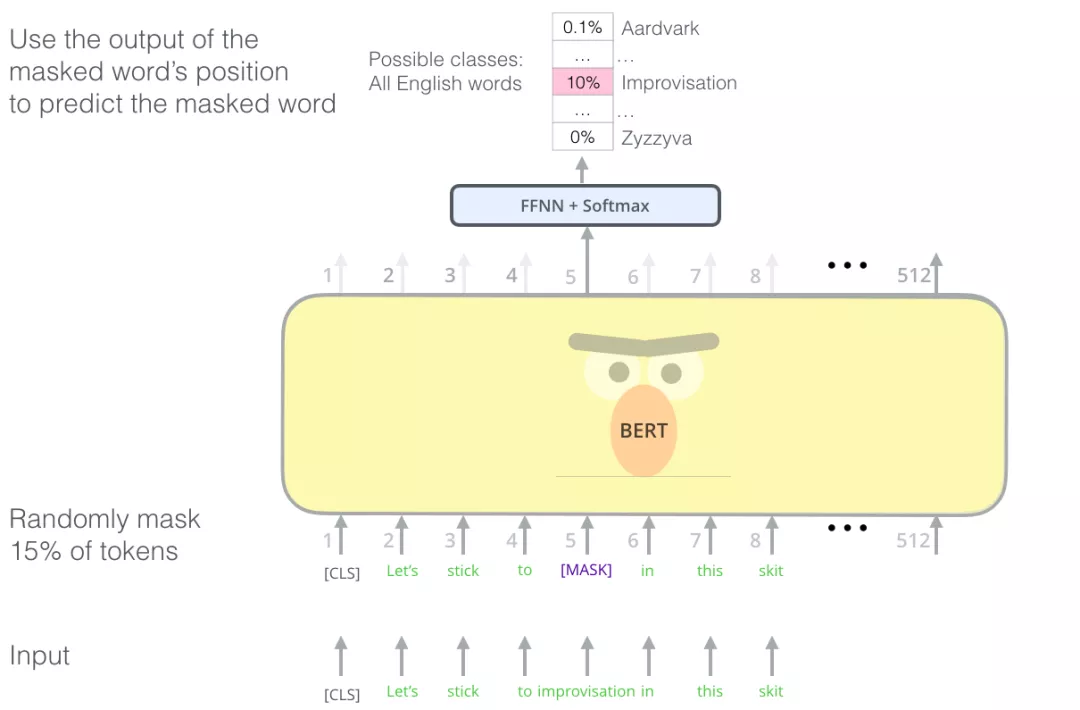
这种训练方式最早可以追溯到Word2Vec时代,典型的Word2Vec算法便是:基于词C两边的A、B和D、E词来预测出词C。
预训练任务:相邻句子判断
除了masked language model,BERT在预训练时,还引入了一个新的任务:判断两个句子是否是相邻句子。如下图所示:输入是sentence A和sentence B,经过BERT编码之后,使用[CLS] token的向量表示来预测两个句子是否是相邻句子。
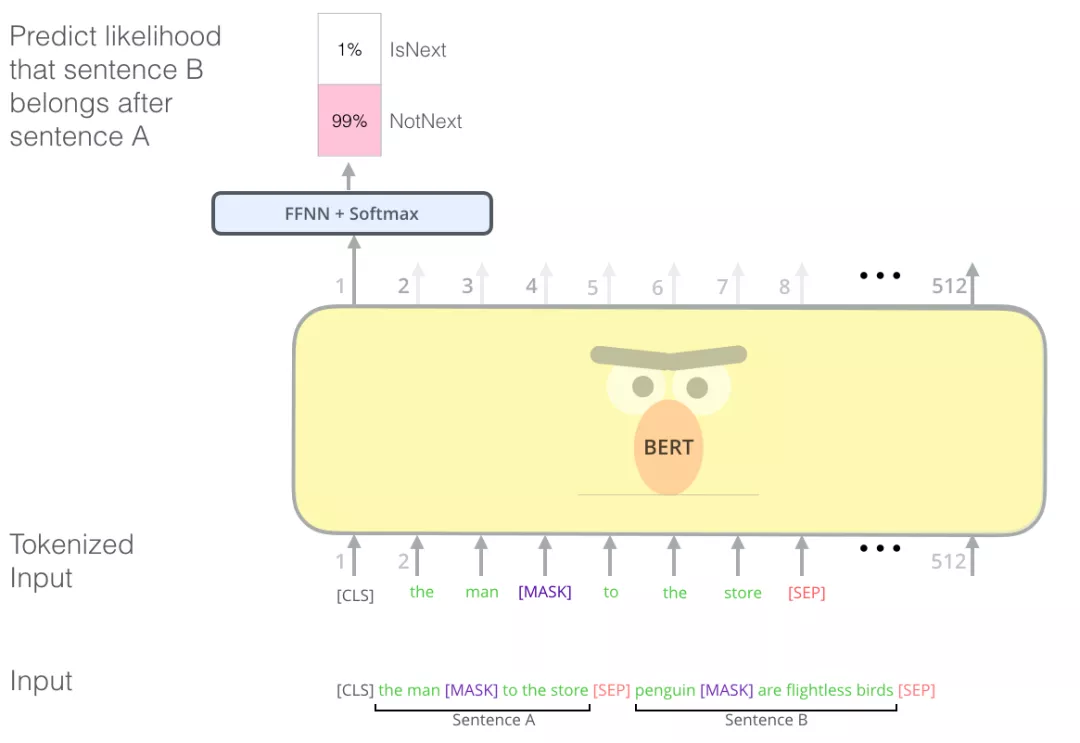
注意事项:为了本文的描述方便,在前面的叙述中,均省略了BERT tokenize的过程,但读者朋友需要注意BERT实际上使用的是WordPieces作为最小的处理单元(采用的是wordpiece算法分词):token,而不是使用单词本身。在 WordPiece中,有些词会被拆分成更小的部分。关于WordPiece分词,本文不过多展开,感兴趣的读者可以阅读和学习subword tokenizer。另外,判断两个句子是否相邻这个任务在后来的研究中逐渐被淡化了,比如roberta模型在被提出的时候就不再使用该任务进行预训练了。
BERT的应用
BERT论文展示了BERT在多种任务上的应用,如下图所示。可以用来判断两个句子是否相似,判断单个句子的情感,用来做抽取式问答,用来做序列标注。
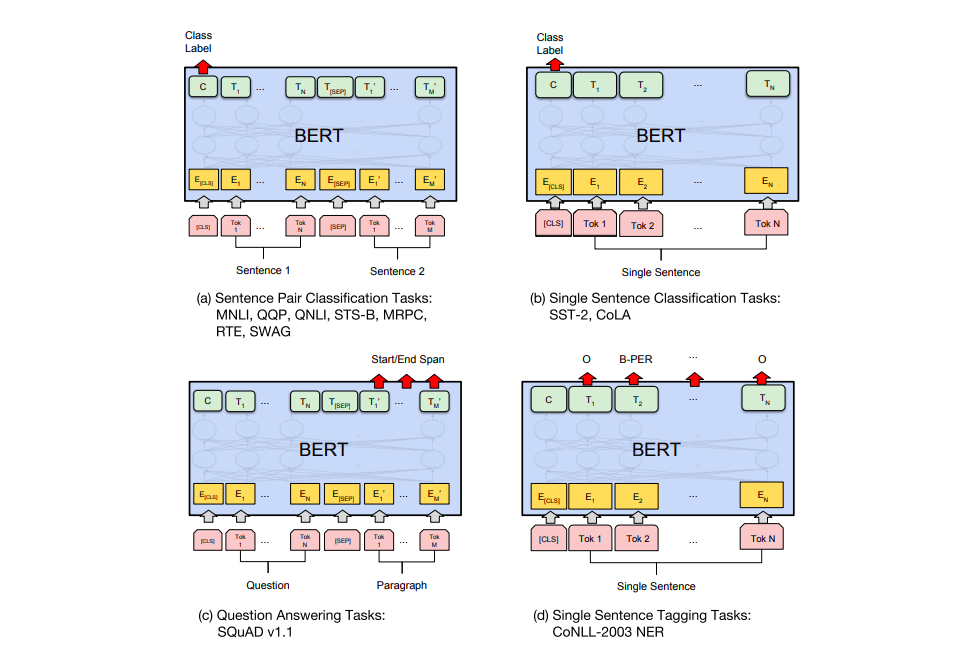
BERT特征提取
由于BERT模型可以得到输入序列所对应的所有token的向量表示,因此不仅可以使用最后一层BERT的输出连接上任务网络进行微调,还可以直接使用这些token的向量当作特征。比如,可以直接提取每一层encoder的token表示当作特征,输入现有的特定任务神经网络中进行训练。
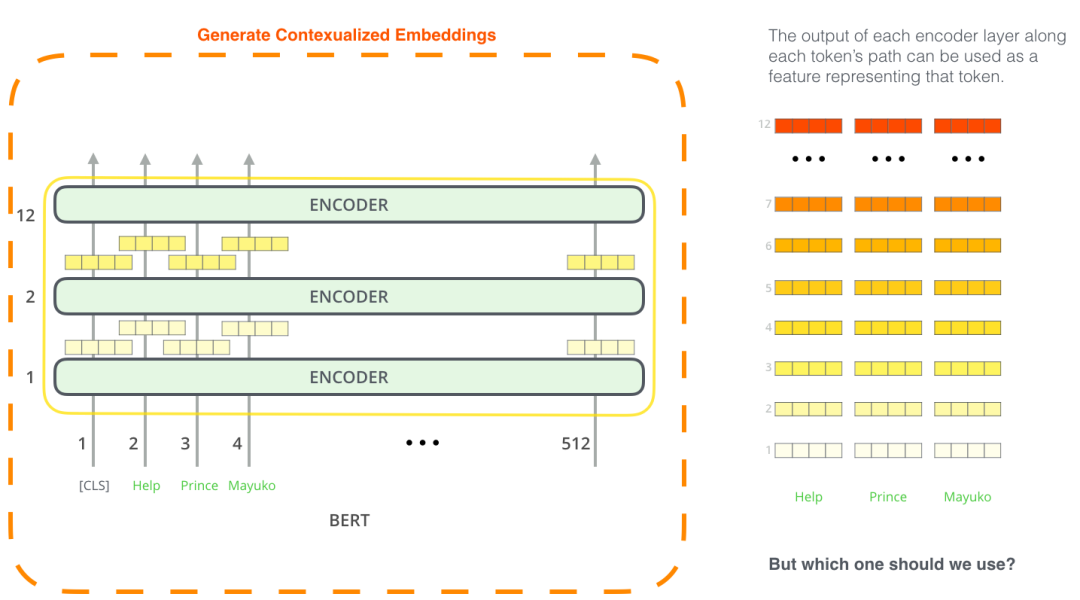
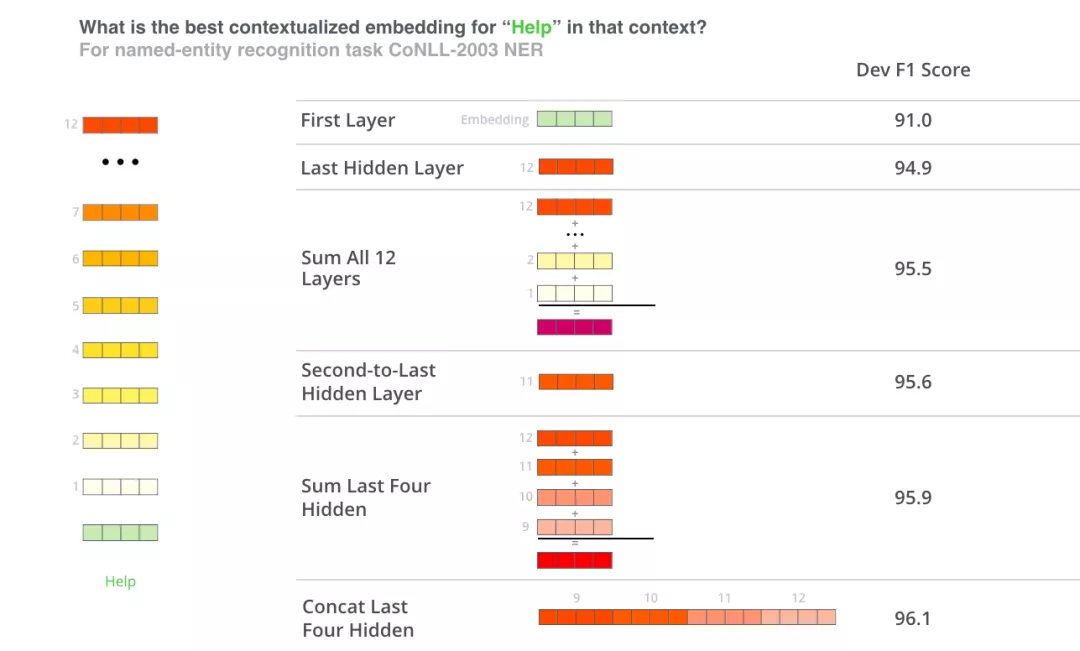
那么我们是使用最后一层的向量表示,还是前几层的,还是都使用呢?下图给出了一种试验结果:
拓展阅读
对比CNN
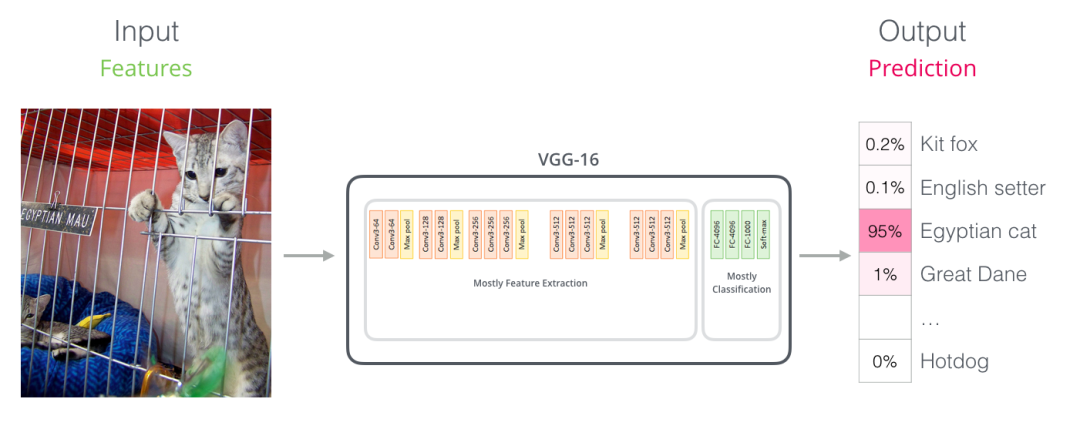
对于那些有计算机视觉背景的人来说,根据BERT的编码过程,会联想到计算机视觉中使用VGGNet等网络的卷积神经网络+全连接网络做分类任务,如下图所示,基本训练方法和过程是类似的。
词嵌入(Embedding)进展
回顾词嵌入
单词不能直接输入机器学习模型,而需要某种数值表示形式,以便模型能够在计算中使用。通过Word2Vec,我们可以使用一个向量(一组数字)来恰当地表示单词,并捕捉单词的语义以及单词和单词之间的关系(例如,判断单词是否相似或者相反,或者像 “Stockholm” 和 “Sweden” 这样的一对词,与 “Cairo” 和 “Egypt”这一对词,是否有同样的关系)以及句法、语法关系(例如,”had” 和 “has” 之间的关系与 “was” 和 “is” 之间的关系相同)。
人们很快意识到,相比于在小规模数据集上和模型一起训练词嵌入,更好的一种做法是,在大规模文本数据上预训练好词嵌入,然后拿来使用。因此,我们可以下载由 Word2Vec 和 GloVe 预训练好的单词列表,及其词嵌入。下面是单词 “stick” 的 Glove 词嵌入向量的例子(词嵌入向量长度是 200)。

单词 “stick” 的 Glove 词嵌入embedding向量表示:一个由200个浮点数组成的向量(四舍五入到小数点后两位)。
由于这些向量都很长,且全部是数字,所以在文章中我使用以下基本形状来表示向量:

语境问题
如果我们使用 Glove 的词嵌入表示方法,那么不管上下文是什么,单词 “stick” 都只表示为一个向量。一些研究人员指出,像 “stick” 这样的词有多种含义。为什么不能根据它使用的上下文来学习对应的词嵌入呢?这样既能捕捉单词的语义信息,又能捕捉上下文的语义信息。于是,语境化的词嵌入模型应运而生:ELMo。

语境化的词嵌入,可以根据单词在句子语境中的含义,赋予不同的词嵌入。
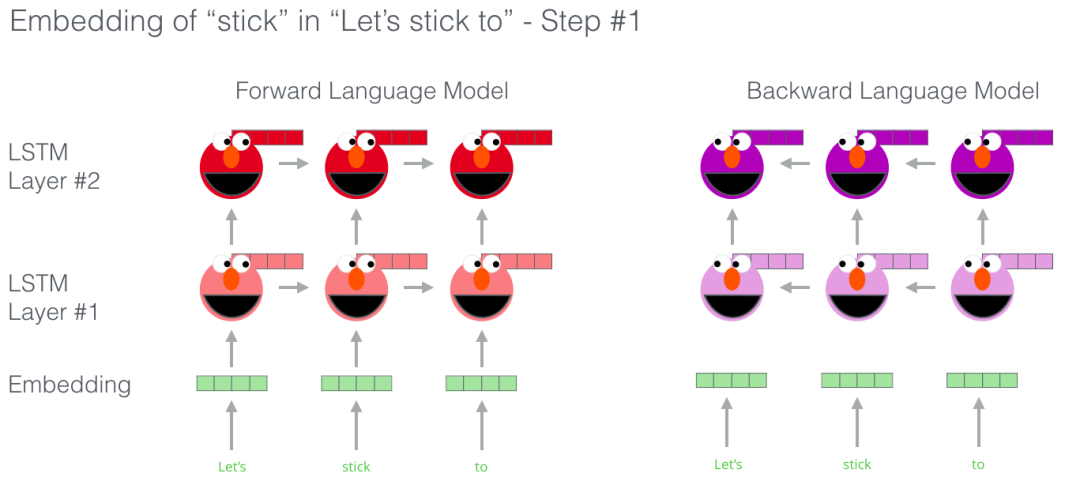
ELMo没有对每个单词使用固定的词嵌入,而是在为每个词分配词嵌入之前,查看整个句子,融合上下文信息。它使用在特定任务上经过训练的双向LSTM来创建这些词嵌入。
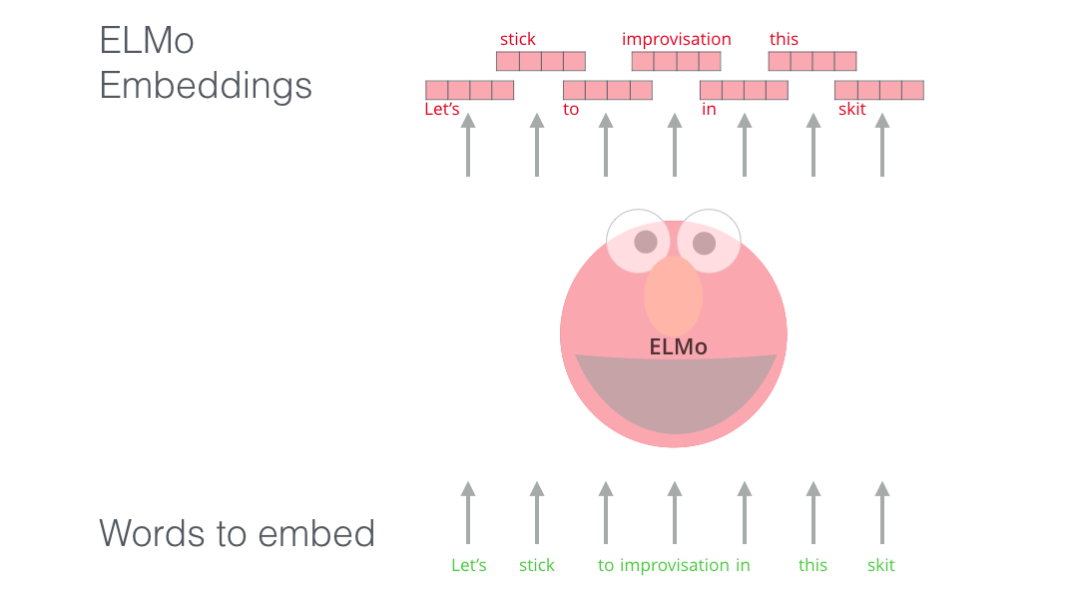
ELMo 在语境化的预训练这条道路上迈出了重要的一步。ELMo LSTM 会在一个大规模的数据集上进行训练,然后我们可以将它作为其他语言处理模型的一个部分,来处理自然语言任务。
那么 ELMo 的秘密是什么呢?
ELMo 通过训练,预测单词序列中的下一个词,从而获得了语言理解能力,这项任务被称为语言建模。要实现 ELMo 很方便,因为我们有大量文本数据,模型可以从这些数据中学习,而不需要额外的标签。
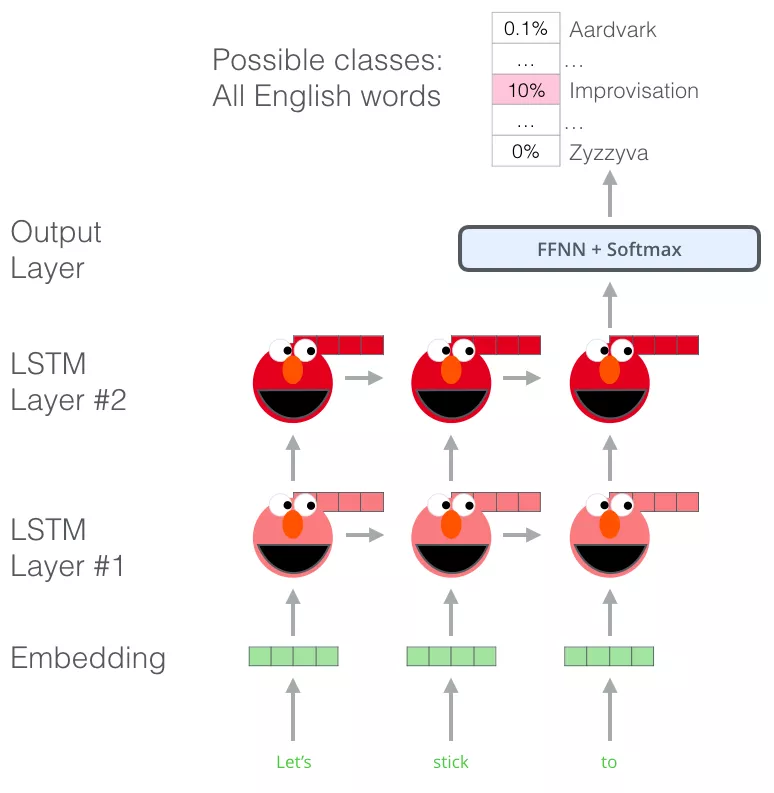
ELMo预训练过程是一个典型的语言模型:以 “Let’s stick to” 作为输入,预测下一个最有可能的单词。当我们在大规模数据集上训练时,模型开始学习语言的模式。例如,在 “hang” 这样的词之后,模型将会赋予 “out” 更高的概率(因为 “hang out” 是一个词组),而不是输出 “camera”。
在上图中,我们可以看到 ELMo 头部上方展示了 LSTM 的每一步的隐藏层状态向量。在这个预训练过程完成后,这些隐藏层状态在词嵌入过程中派上用场。
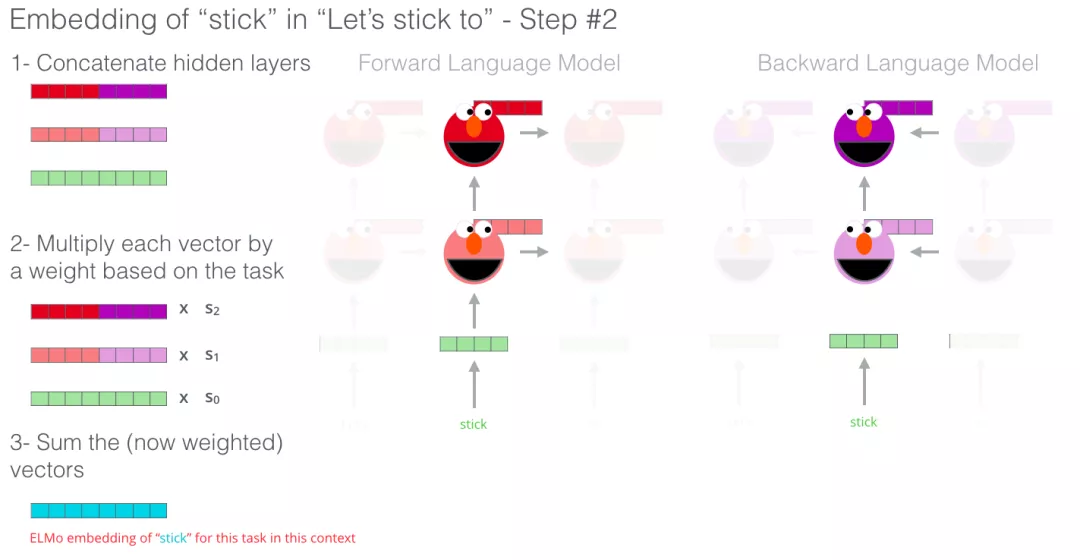
ELMo 通过将LSTM模型的隐藏层表示向量(以及初始化的词嵌入)以某种方式(向量拼接之后加权求和)结合在一起,实现了带有语境化的词嵌入。
Transformer:超越LSTM
随着Transformer论文和代码的发布,以及它在机器翻译等任务上取得的成果,开始让人们认为它是LSTM的替代品。一部分原因是:1. 因为 Transformer 可以比 LSTM 更好地处理长期依赖,2. Transformer可以对输入进行并行运算。
2017年,基于Transformer的Encoder-Decoder展示了它在机器翻译上的威力。但怎么才能用它来做文本分类呢?你怎么才能使用它来预训练一个语言模型,并能够在其他任务上进行微调(下游任务是指那些能够利用预训练模型的监督学习任务)?
OpenAI Transformer:预训练一个Transformer Decoder进行语言建模
沿着LSTM语言模型预训练的路子,将LSTM替换成Transformer结构后(相当于),直接语言模型预训练的参数给予下游任务监督数据进行微调,与最开始用于翻译seq2seq的Transformer对比来看,相当于只使用了Decoder部分。有了Transformer结构和语言模型任务设计,直接使用大规模未标记的数据不断得预测下一个词:只需要把 7000 本书的文字依次扔给模型 ,然后让它不断学习生成下一个词即可。
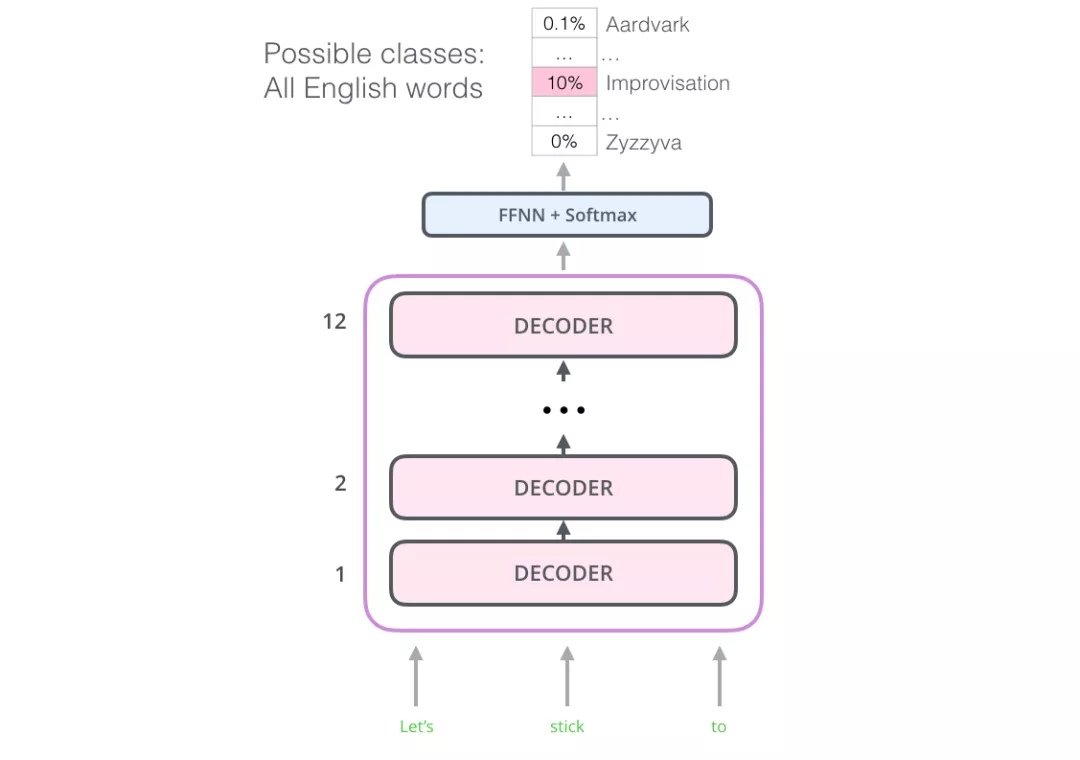
现在,OpenAI Transformer 已经经过了预训练,它的网络层藏书经过很多次调整,可以很好地用向量表示文本了,我们开始使用它来处理下游任务。让我们先看下句子分类任务(把电子邮件分类为 ”垃圾邮件“ 或者 ”非垃圾邮件“):
对于形形色色的NLP任务,OpenAI 的论文列出了一些列输入变换方法,可以处理不同任务类型的输入。下面这张图片来源于论文,展示了处理不同任务的模型结构和对应输入变换。

BERT:Decoder到Encoder
OpenAI Transformer为我们提供了一个基于Transformer的预训练网络。但是在把LSTM换成Transformer 的过程中,有些东西丢失了。比如之前的ELMo的语言模型是双向的,但 OpenAI Transformer 只训练了一个前向的语言模型。我们是否可以构建一个基于 Transformer 的语言模型,它既向前看,又向后看(用技术术语来说 - 融合上文和下文的信息)?答案就是BERT:基于双向Transformer的encoder,在Masked language model上进行预训练,最终在多项NLP下游任务中取得了SOTA效果。
图解GPT
除了BERT以外,另一个预训练模型GPT也给NLP领域带来了不少轰动,本节也对GPT做一个详细的讲解。
OpenAI提出的GPT-2模型能够写出连贯并且高质量的文章,比之前语言模型效果好很多。GPT-2是基于Transformer搭建的,相比于之前的NLP语言模型的区别是:基于Transformer大模型、,在巨大的数据集上进行了预训练。在本章节中,我们将对GPT-2的结构进行分析,对GPT-2的应用进行学习,同时还会深入解析所涉及的self-attention结构。本文可以看作是篇章2.2图解Transformer、2.3图解BERT的一个补充。
这篇文章翻译自GPT2。
语言模型和GPT-2
什么是语言模型
本文主要描述和对比2种语言模型:
- 自编码(auto-encoder)语言模型
- 自回归(auto-regressive)语言模型
先看自编码语言模型。
自编码语言模型典型代表就是篇章2.3所描述的BERT。如下图所示,自编码语言模型通过随机Mask输入的部分单词,然后预训练的目标是预测被Mask的单词,不仅可以融入上文信息,还可以自然的融入下文信息。
自编码语言模型的优缺点:
- 优点:自然地融入双向语言模型,同时看到被预测单词的上文和下文
- 缺点:训练和预测不一致。训练的时候输入引入了[Mask]标记,但是在预测阶段往往没有这个[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致。
接着我们来看看什么是常用的自回归(auto-regressive)语言模型:语言模型根据输入句子的一部分文本来预测下一个词。日常生活中最常见的语言模型就是输入法提示,它可以根据你输入的内容,提示下一个单词。
图:输入提示
自回归语言模型的优点和缺点:
- 优点:对于生成类的NLP任务,比如文本摘要,机器翻译等,从左向右的生成内容,天然和自回归语言模型契合。
- 缺点:由于一般是从左到右(当然也可能从右到左),所以只能利用上文或者下文的信息,不能同时利用上文和下文的信息。
GPT-2属于自回归语言模型,相比于手机app上的输入提示,GPT-2更加复杂,功能也更加强大。因为,OpenAI的研究人员从互联网上爬取了40GB的WebText数据集,并用该数据集训练了GPT-2模型。我们可以直接在AllenAI GPT-2 Explorer网站上试用GPT-2模型。 图:自回归GPT-2
图:自回归GPT-2

基于Transformer的语言模型
正如我们在图解Transformer所学习的,原始的Transformer模型是由 Encoder部分和Decoder部分组成的,它们都是由多层transformer堆叠而成的。原始Transformer的seq2seq结构很适合机器翻译,因为机器翻译正是将一个文本序列翻译为另一种语言的文本序列。
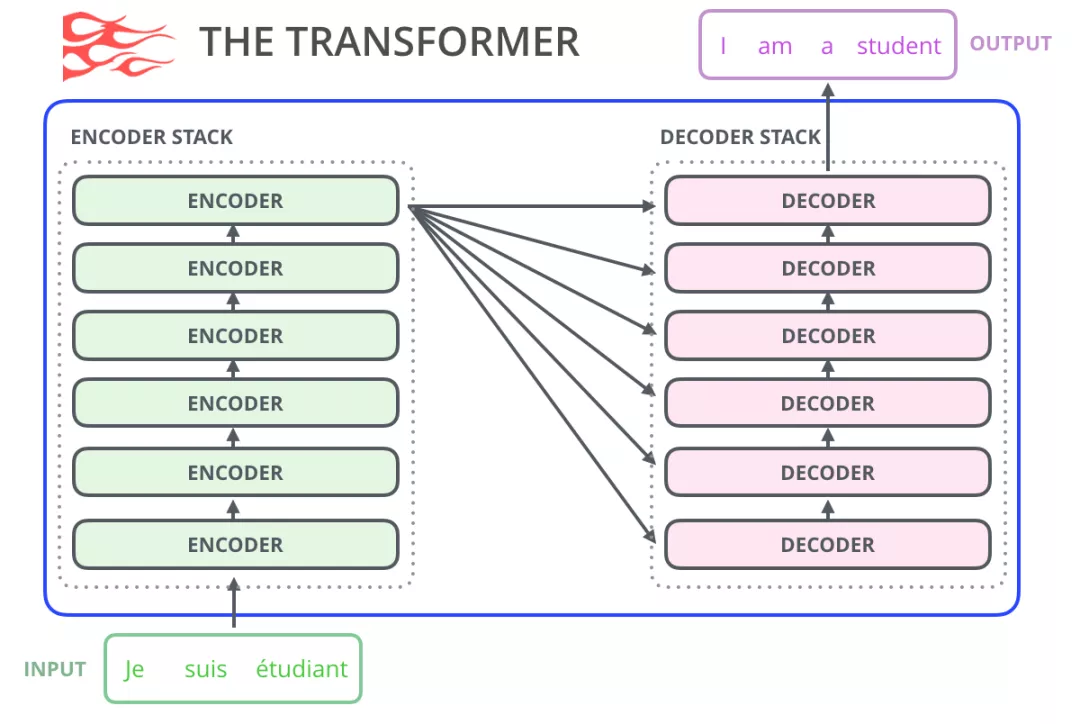
但如果要使用Transformer来解决语言模型任务,并不需要完整的Encoder部分和Decoder部分,于是在原始Transformer之后的许多研究工作中,人们尝试只使用Transformer Encoder或者Decoder,并且将它们堆得层数尽可能高,然后使用大量的训练语料和大量的计算资源(数十万美元用于训练这些模型)进行预训练。比如BERT只使用了Encoder部分进行masked language model(自编码)训练,GPT-2便是只使用了Decoder部分进行自回归(auto regressive)语言模型训练。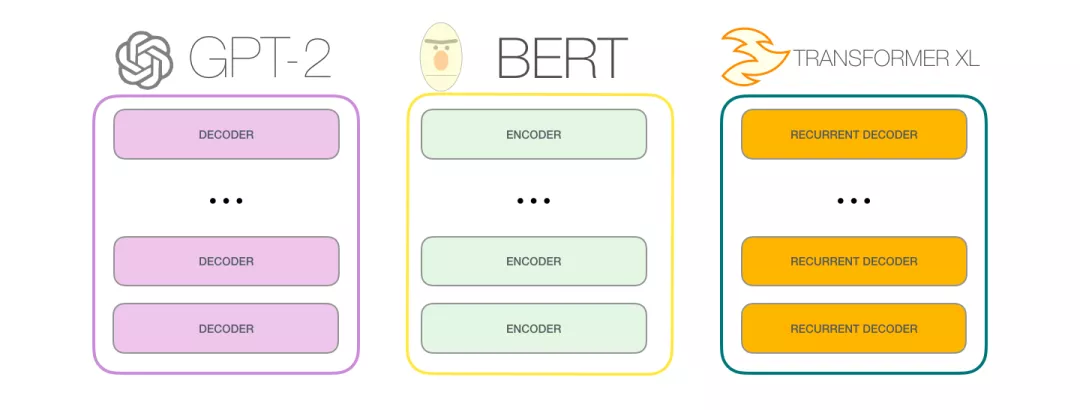
Transformer进化
Transformer的Encoder进化成了BERT,Decoder进化成了GPT2。
首先看Encoder部分。
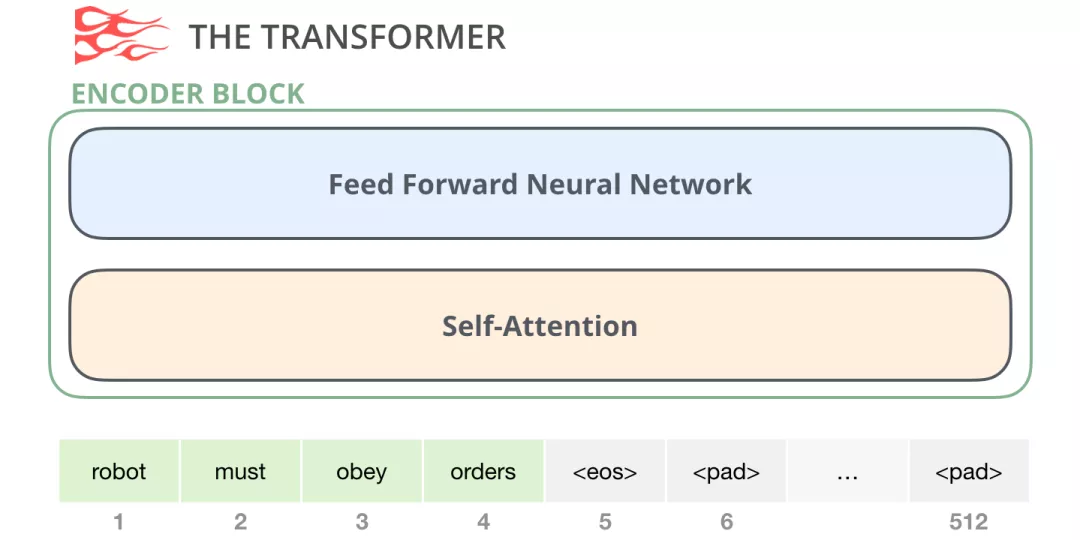
图:encoder
原始的Transformer论文中的Encoder部分接受特定长度的输入(如 512 个 token)。如果一个输入序列比这个限制短,我们可以使用pad填充序列的其余部分。如篇章2.3所讲,BERT直接使用了Encoder部分。
再回顾下Decoder部分
与Encoder相比,Decoder部分多了一个Encoder-Decoder self-attention层,使Decoder可以attention到Encoder编码的特定的信息。
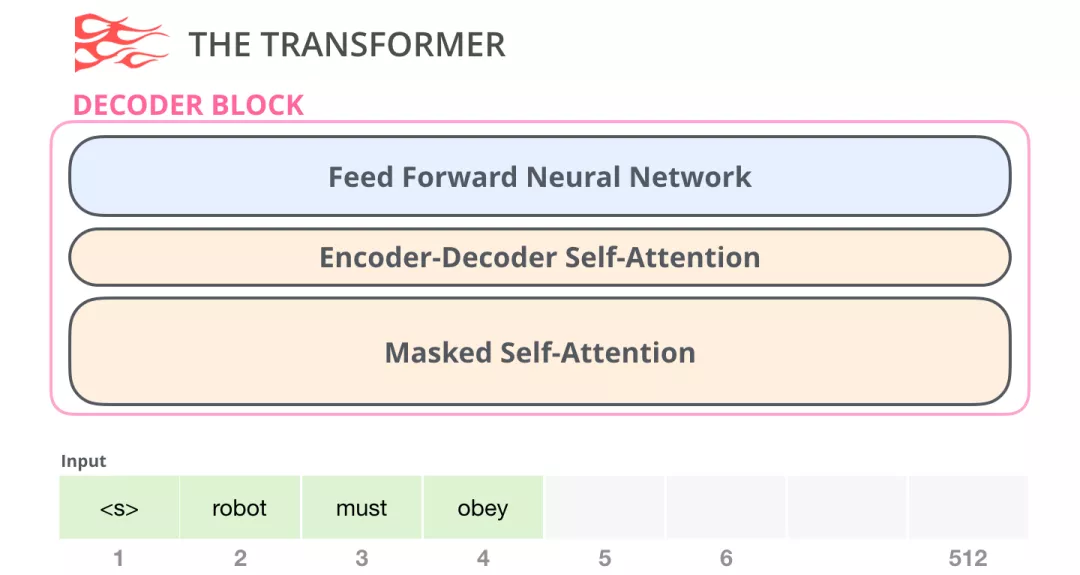
Decoder中的的 Masked Self-Attention会屏蔽未来的token。具体来说,它不像 BERT那样直接将输入的单词随机改为mask,而是通过改变Self-Attention的计算,来屏蔽未来的单词信息。
例如,我们想要计算位置4的attention,我们只允许看到位置4以前和位置4的token。
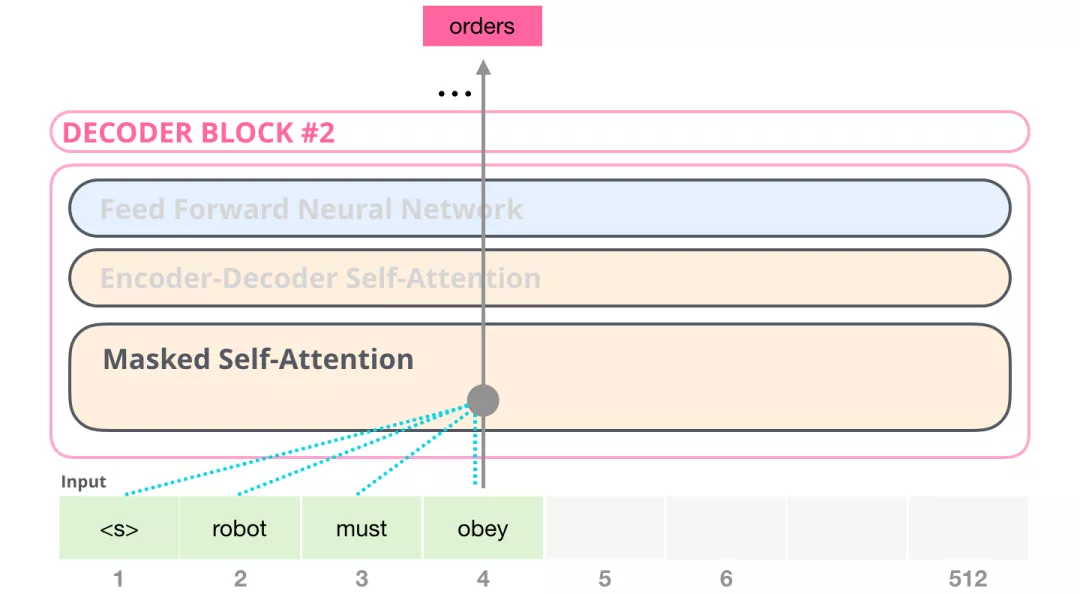
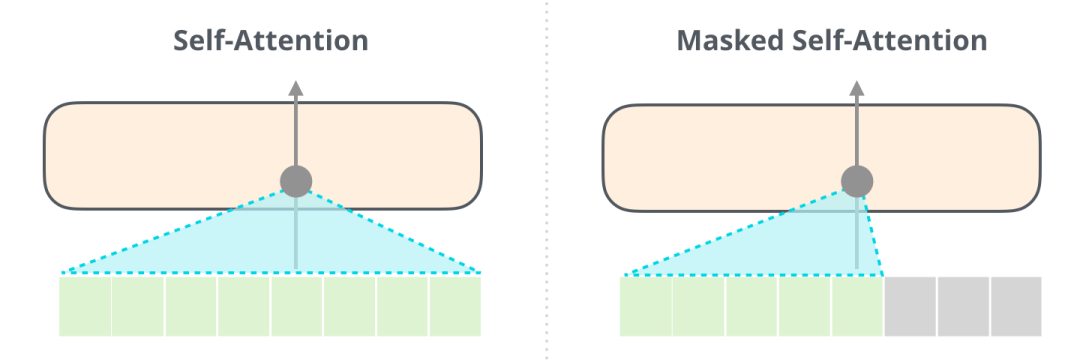
由于GPT2基于Decoder构建,所以BERT和GPT的一个重要区别来了:由于BERT是基于Encoder构建的,BERT使用是Self Attention层,而GPT2基于Decoder构建,GPT-2 使用masked Self Attention。一个正常的 Self Attention允许一个位置关注到它两边的信息,而masked Self Attention只让模型看到左边的信息:
那么GPT2中的Decoder长什么样子呢?先要说一下Generating Wikipedia by Summarizing Long Sequences这篇文章,它首先提出基于Transformer-Decoder部分进行语言模型训练。由于去掉了Encoder部分,于是Encoder-Decoder self attention也不再需要,新的Transformer-Decoder模型如下图所示:
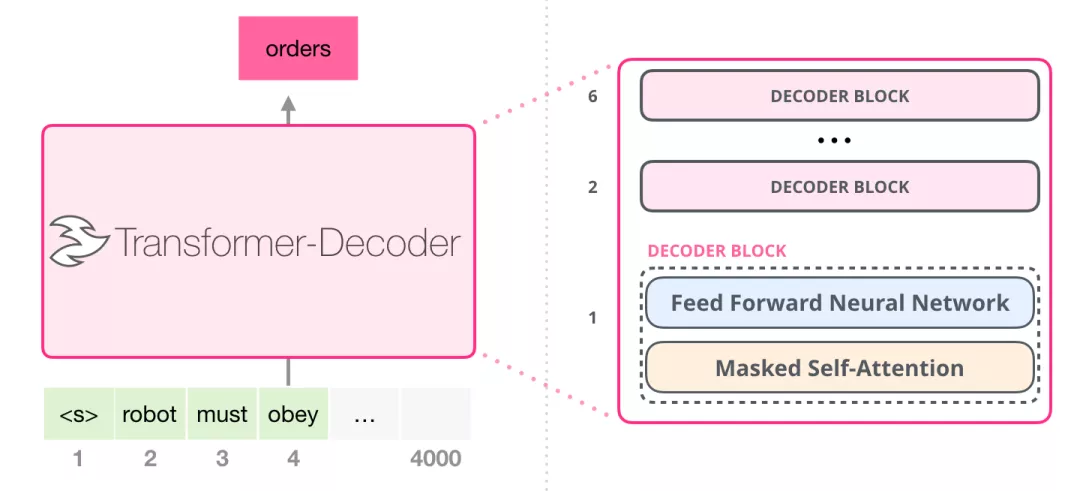
随后OpenAI的GPT2也使用的是上图的Transformer-Decoder结构。
GPT2概述
现在来拆解一个训练好的GPT-2,看看它是如何工作的。
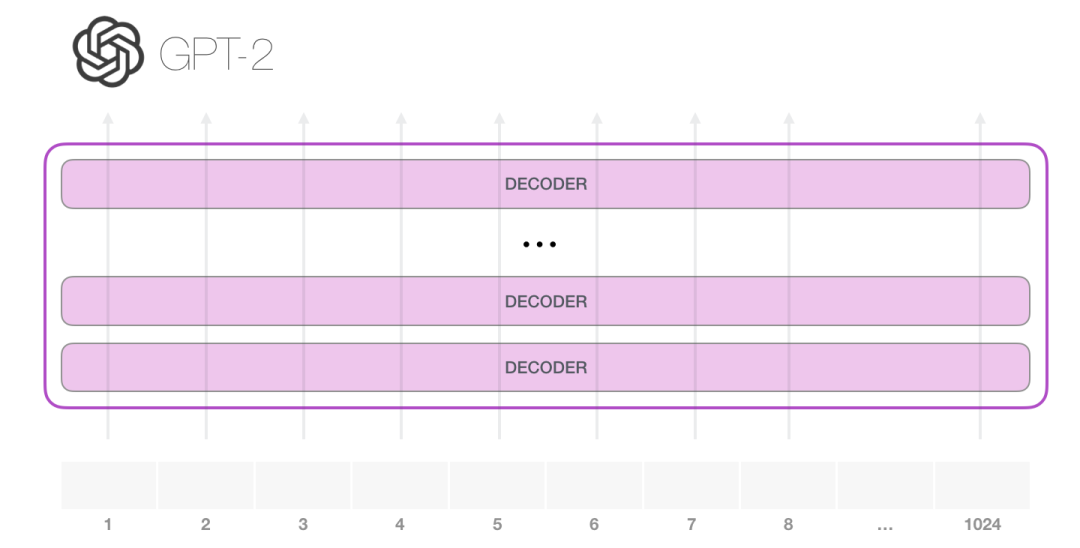
GPT-2能够处理1024 个token。每个token沿着自己的路径经过所有的Decoder层。试用一个训练好的GPT-2模型的最简单方法是让它自己生成文本(这在技术上称为:生成无条件文本)。或者,我们可以给它一个提示,让它谈论某个主题(即生成交互式条件样本)。
在漫无目的情况下,我们可以简单地给它输入一个特殊的<s>初始token,让它开始生成单词。如下图所示:
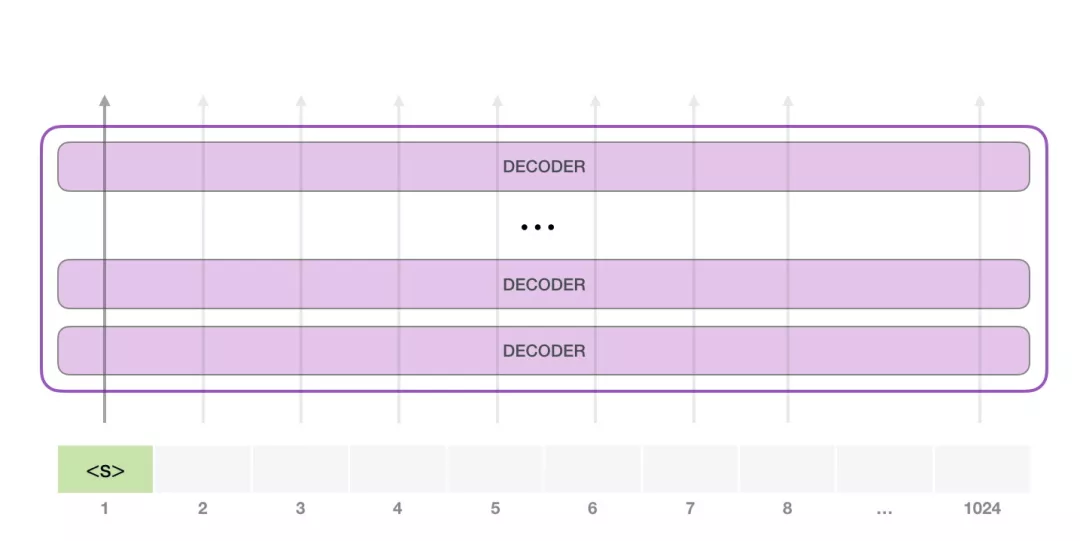
由于模型只有一个输入,因此只有一条活跃路径。<s> token在所有Decoder层中依次被处理,然后沿着该路径生成一个向量。根据这个向量和模型的词汇表给所有可能的词计算出一个分数。在下图的例子中,我们选择了概率最高的 the。下一步,我们把第一步的输出添加到我们的输入序列,然后让模型做下一个预测。
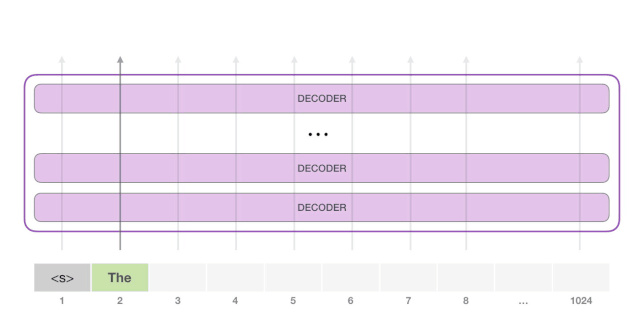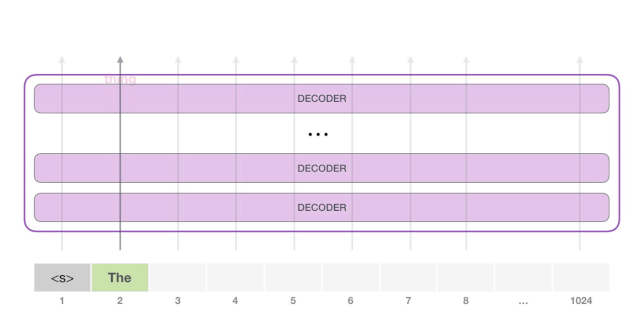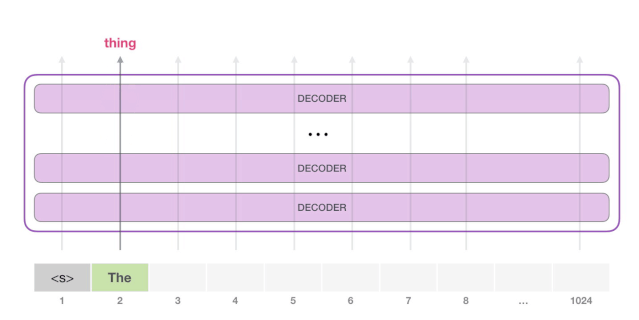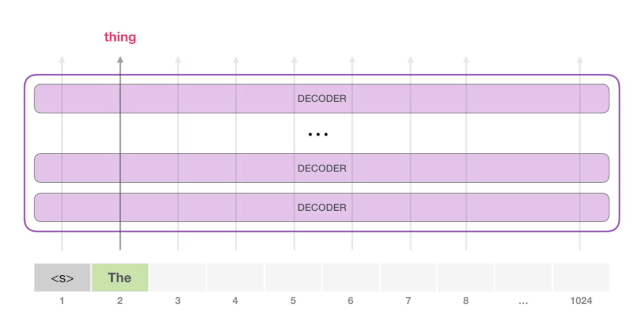
请注意,第二条路径是此计算中唯一活动的路径。GPT-2 的每一层都保留了它对第一个 token所编码的信息,而且会在处理第二个 token 时直接使用它:GPT-2 不会根据第2个 token 重新计算第一个 token。
不断重复上述步骤,就可以生成更多的单词了。
GPT2详解
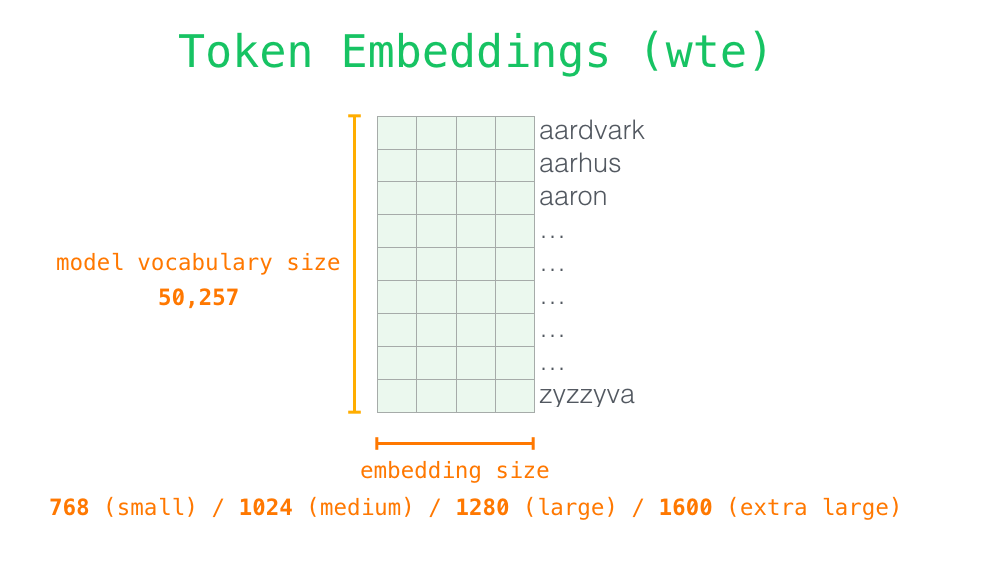
输入编码
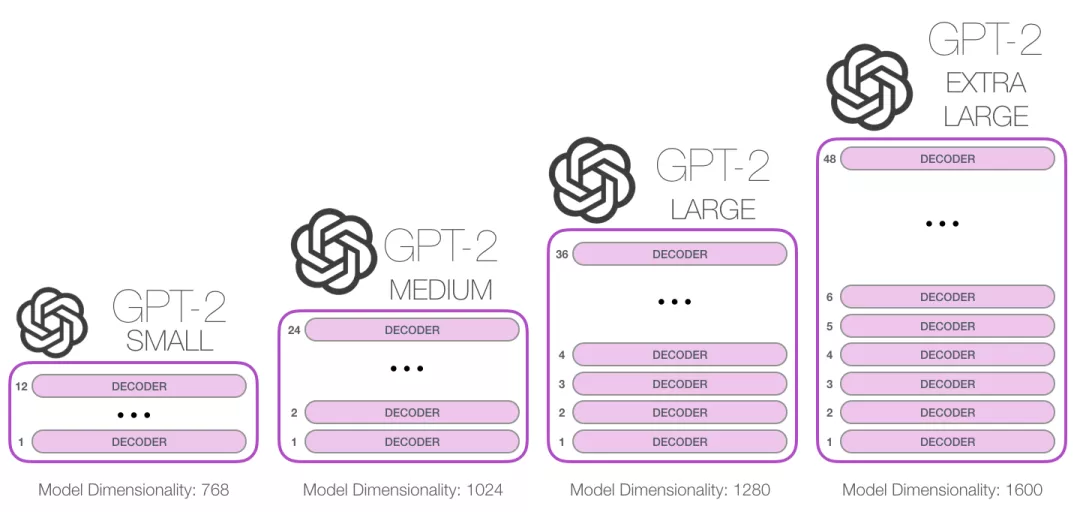
现在我们更深入了解和学习GPT,先看从输入开始。与之前我们讨论的其他 NLP 模型一样,GPT-2 在嵌入矩阵中查找输入的单词的对应的 embedding 向量。如下图所示:每一行都是词的 embedding:这是一个数值向量,可以表示一个词并捕获一些含义。这个向量的大小在不同的 GPT-2 模型中是不同的。最小的模型使用的 embedding 大小是 768。
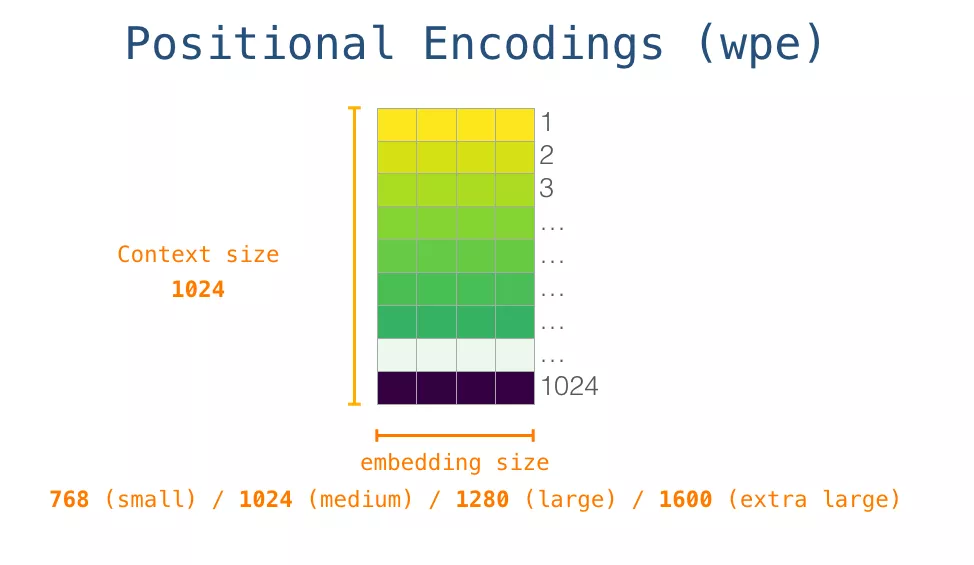
于是在开始时,我们会在嵌入矩阵查找第一个 token <s> 的 embedding。在把这个 embedding 传给模型的第一个模块之前,我们还需要融入位置编码(参考篇章2.2详解Transformer),这个位置编码能够指示单词在序列中的顺序。

于是输入的处理:得到词向量+位置编码
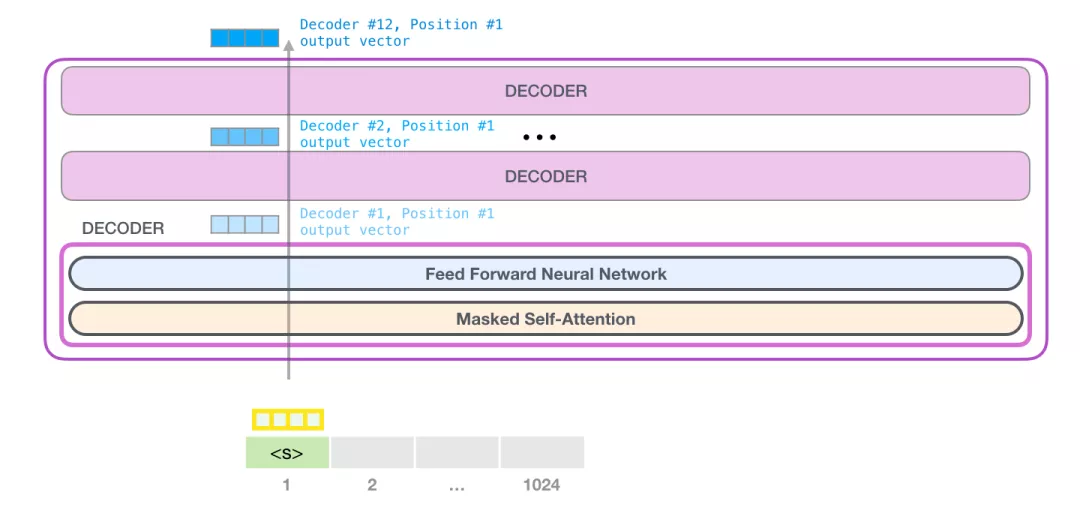
多层Decoder
第一层Decoder现在可以处理 <s> token所对应的向量了:首先通过 Self Attention 层,然后通过全连接神经网络。一旦Transformer 的第1个Decoder处理了<s> token,依旧可以得到一个向量,这个结果向量会再次被发送到下一层Decoder。
Decoder中的Self-Attention
Decoder中包含了Masked Self-Attention,由于Mask的操作可以独立进行,于是我们先独立回顾一下self-attention操作。语言严重依赖于上下文。给个例子:
1 | |
例句中包含了多个代词。如果不结合它们所指的上下文,就无法理解或者处理这些词。当一个模型处理这个句子,它必须能够知道:
- 它 指的是机器人
- 该命令 指的是这个定律的前面部分,也就是 人给予 它 的命令
- 第一定律 指的是机器人第一定律
self-attention所做的事情是:它通过对句子片段中每个词的相关性打分,并将这些词的表示向量根据相关性加权求和,从而让模型能够将词和其他相关词向量的信息融合起来。
举个例子,如下图所示,最顶层的Decoder中的 Self Attention 层在处理单词 it 的时候关注到a robot。于是self-attention传递给后续神经网络的it 向量,是3个单词对应的向量和它们各自分数的加权和。
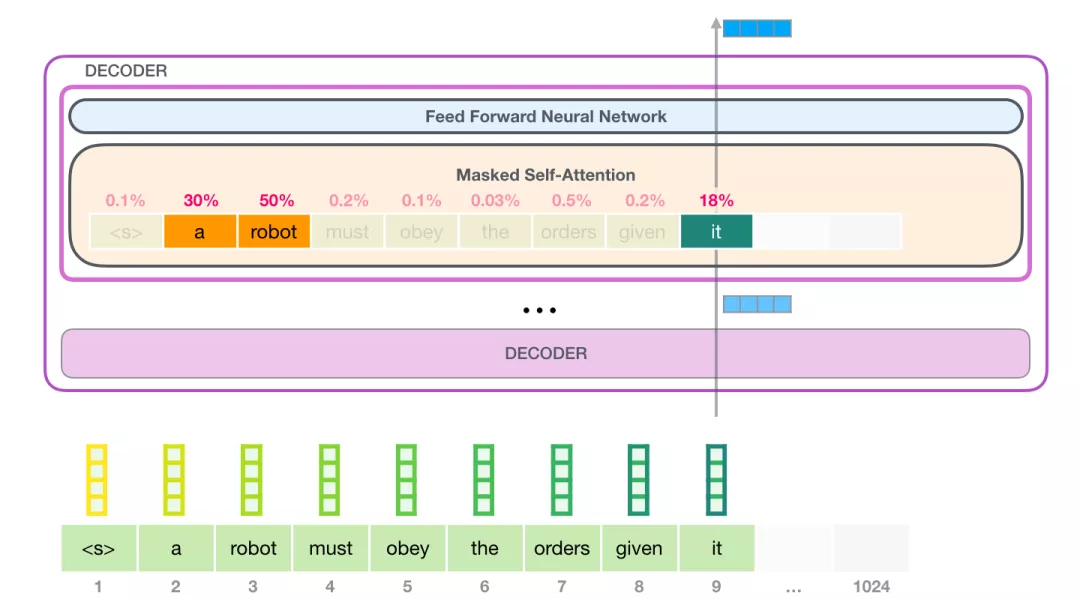
Self-Attention 过程
Self-Attention 沿着句子中每个 token 进行处理,主要组成部分包括 3 个向量。
- Query:Query 向量是由当前词的向量表示获得,用于对其他所有单词(使用这些单词的 key 向量)进行评分。
- Key:Key 向量由句子中的所有单词的向量表示获得,可以看作一个标识向量。
- Value:Value 向量在self-attention中与Key向量其实是相同的。
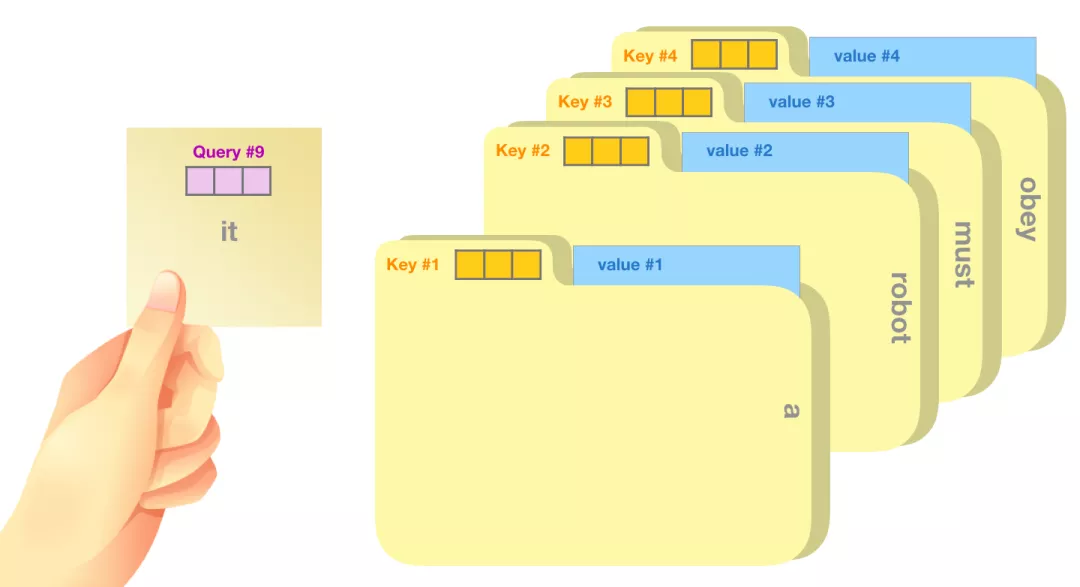
一个粗略的类比是把它看作是在一个文件柜里面搜索,Query 向量是一个便签,上面写着你正在研究的主题,而 Key 向量就像是柜子里的文件夹的标签。当你将便签与标签匹配时,我们取出匹配的那些文件夹的内容,这些内容就是 Value 向量。但是你不仅仅是寻找一个 Value 向量,而是找到一系列Value 向量。
将 Query 向量与每个文件夹的 Key 向量相乘,会为每个文件夹产生一个分数(从技术上来讲:点积后面跟着 softmax)。
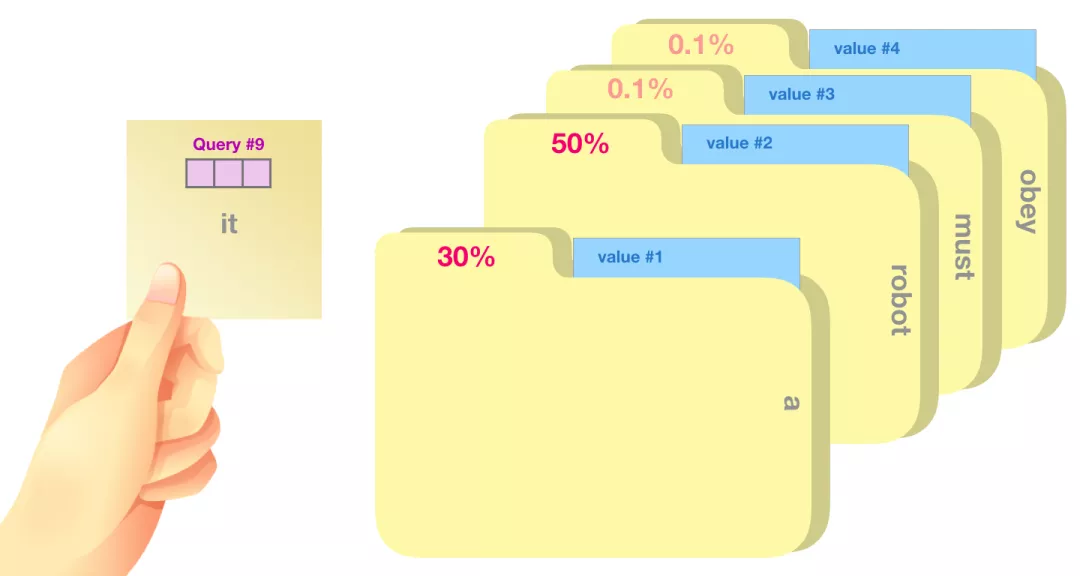
我们将每个 Value 向量乘以对应的分数,然后求和,就得到了 Self Attention 的输出。
这些加权的 Value 向量会得到一个向量,比如上图,它将 50% 的注意力放到单词 robot 上,将 30% 的注意力放到单词 a,将 19% 的注意力放到单词 it。
而所谓的Masked self attention指的的是:将mask位置对应的的attention score变成一个非常小的数字或者0,让其他单词再self attention的时候(加权求和的时候)不考虑这些单词。
模型输出
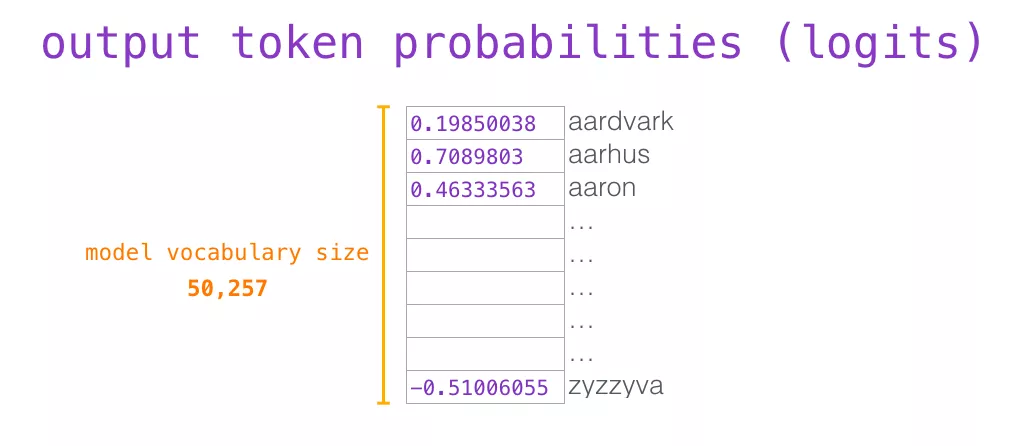
当模型顶部的Decoder层产生输出向量时(这个向量是经过 Self Attention 层和神经网络层得到的),模型会将这个向量乘以一个巨大的嵌入矩阵(vocab size x embedding size)来计算该向量和所有单词embedding向量的相关得分。
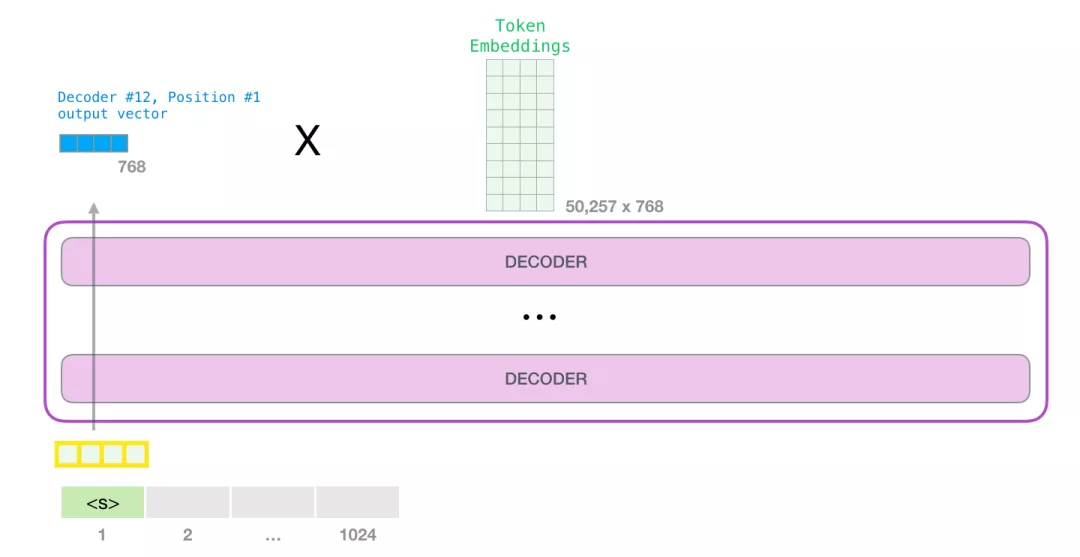
回忆一下,嵌入矩阵中的每一行都对应于模型词汇表中的一个词。这个相乘的结果,被解释为模型词汇表中每个词的分数,经过softmax之后被转换成概率。
我们可以选择最高分数的 token(top_k=1),也可以同时考虑其他词(top k)。假设每个位置输出k个token,假设总共输出n个token,那么基于n个单词的联合概率选择的输出序列会更好。
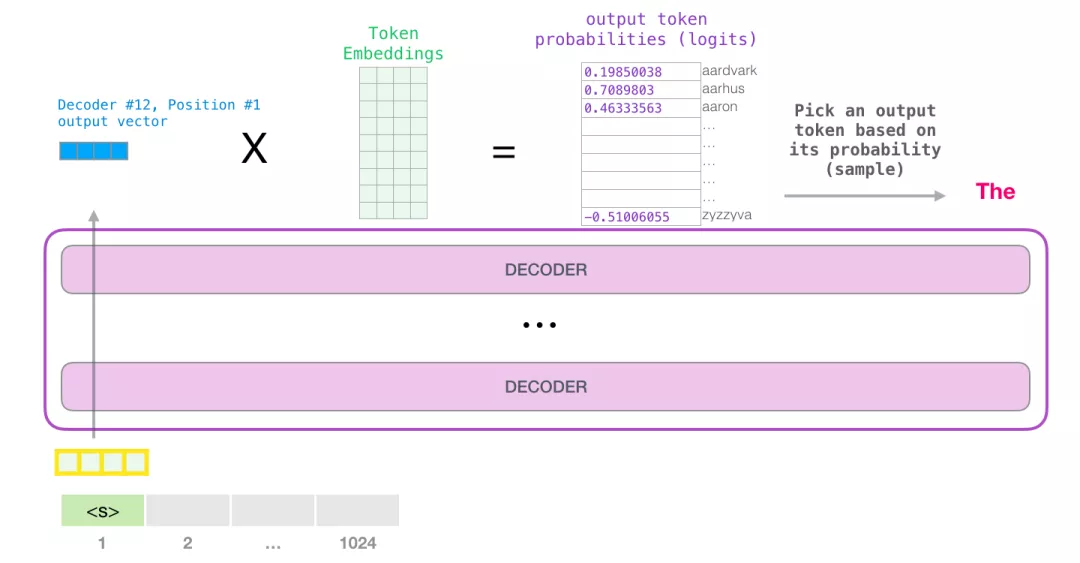
这样,模型就完成了一次迭代,输出一个单词。模型会继续迭代,直到所有的单词都已经生成,或者直到输出了表示句子末尾的 token。
详解Self-Attention
现在我们基本知道了 GPT-2 是如何工作的。如果你想知道 Self Attention 层里面到底发生了什么,那么文章接下来的额外部分就是为你准备的,我添加这个额外的部分,来使用更多可视化解释 Self Attention,
在这里指出文中一些过于简化的说法:
- 我在文中交替使用 token 和 词。但实际上,GPT-2 使用 Byte Pair Encoding 在词汇表中创建 token。这意味着 token 通常是词的一部分。
- 我们展示的例子是在推理模式下运行。这就是为什么它一次只处理一个 token。在训练时,模型将会针对更长的文本序列进行训练,并且同时处理多个 token。同样,在训练时,模型会处理更大的 batch size,而不是推理时使用的大小为 1 的 batch size。
- 为了更加方便地说明原理,我在本文的图片中一般会使用行向量。但有些向量实际上是列向量。在代码实现中,你需要注意这些向量的形式。
- Transformer 使用了大量的层归一化(layer normalization),这一点是很重要的。我们在图解Transformer中已经提及到了一部分这点,但在这篇文章,我们会更加关注 Self Attention。
- 有时我需要更多的框来表示一个向量,例如下面这幅图:
可视化Self-Attention
在这篇文章的前面,我们使用了这张图片来展示:Self Attention如何处理单词 it。

在这一节,我们会详细介绍如何实现这一点。请注意,我们会讲解清楚每个单词都发生了什么。这就是为什么我们会展示大量的单个向量,而实际的代码实现,是通过巨大的矩阵相乘来完成的。
让我们看看一个简单的Transformer,假设它一次只能处理 4 个 token。
Self-Attention 主要通过 3 个步骤来实现:
- 为每个路径创建 Query、Key、Value 矩阵。
- 对于每个输入的 token,使用它的 Query 向量为所有其他的 Key 向量进行打分。
- 将 Value 向量乘以它们对应的分数后求和。
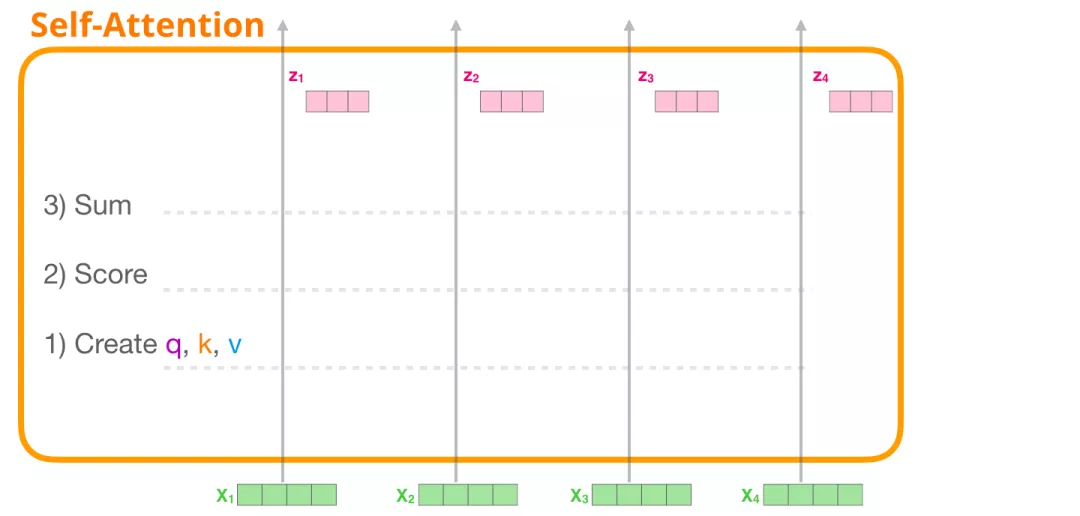
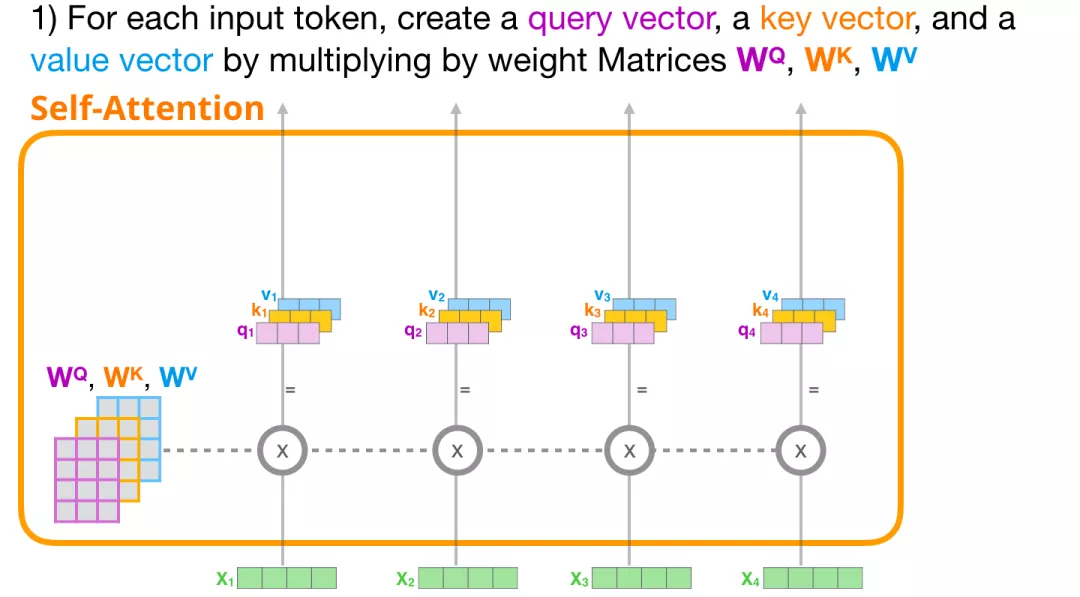
(1) 创建 Query、Key 和 Value 向量
让我们关注第一条路径。我们会使用它的 Query 向量,并比较所有的 Key 向量。这会为每个 Key 向量产生一个分数。Self Attention 的第一步是为每个 token 的路径计算 3 个向量。
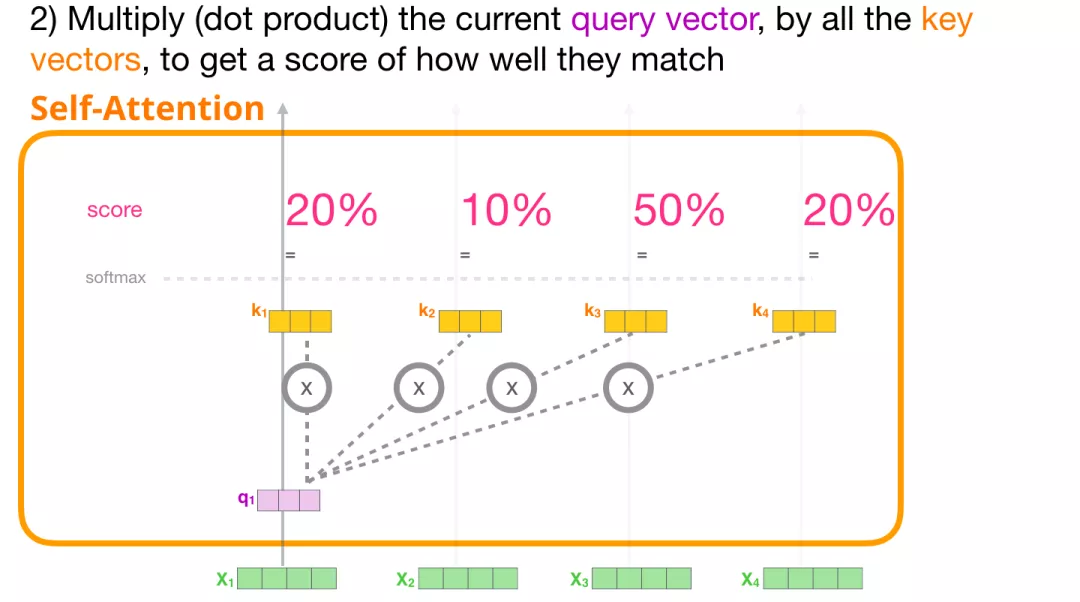
(2) 计算分数
现在我们有了这些向量,我们只对步骤 2 使用 Query 向量和 Value 向量。因为我们关注的是第一个 token 的向量,我们将第一个 token 的 Query 向量和其他所有的 token 的 Key 向量相乘,得到 4 个 token 的分数。
(3) 计算和
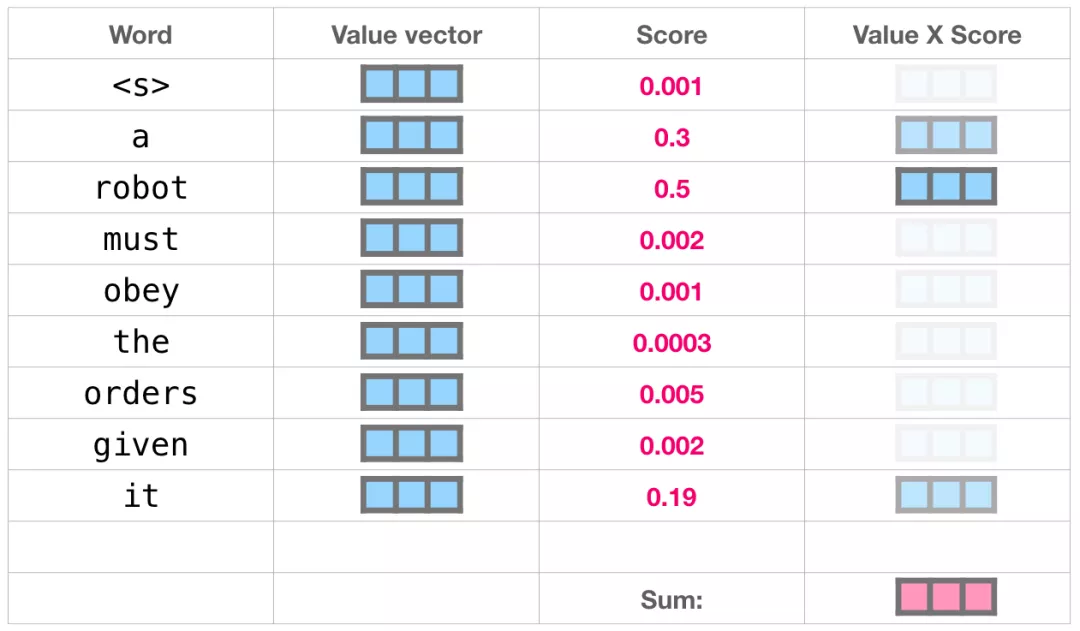
我们现在可以将这些分数和 Value 向量相乘。在我们将它们相加后,一个具有高分数的 Value 向量会占据结果向量的很大一部分。
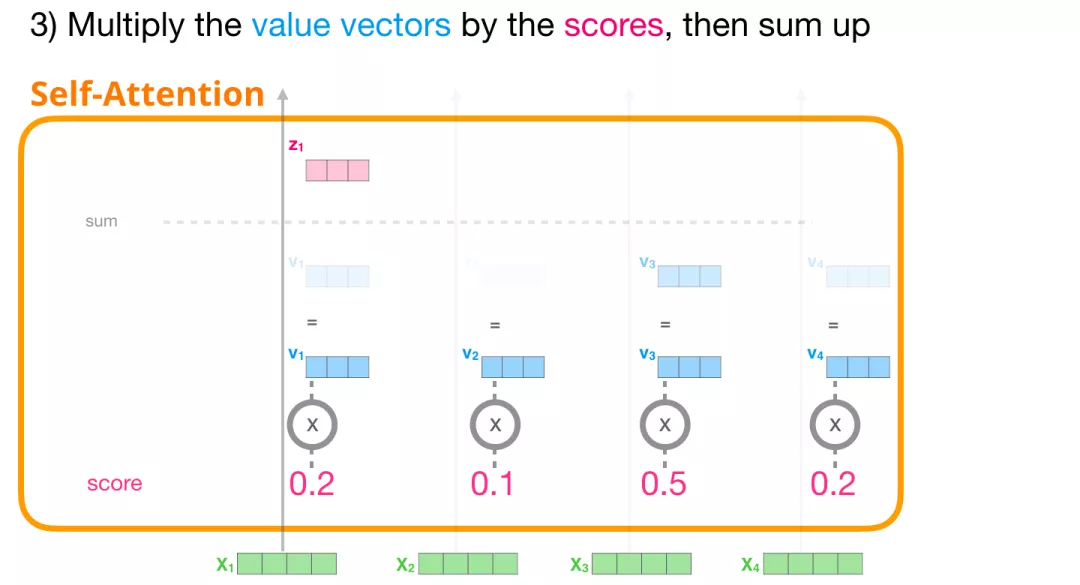
分数越低,Value 向量就越透明。这是为了说明,乘以一个小的数值会稀释 Value 向量。
如果我们对每个路径都执行相同的操作,我们会得到一个向量,可以表示每个 token,其中包含每个 token 合适的上下文信息。这些向量会输入到 Transformer 模块的下一个子层(前馈神经网络)。
图解Masked Self-attention
现在,我们已经了解了 Transformer 的 Self Attention 步骤,现在让我们继续研究 masked Self Attention。Masked Self Attention 和 Self Attention 是相同的,除了第 2 个步骤。
现在假设模型有2个 token 作为输入,我们正在观察(处理)第二个 token。在这种情况下,最后 2 个 token 是被屏蔽(masked)的。所以模型会干扰评分的步骤。它总是把未来的 token 评分设置为0,因此模型不能看到未来的词,如下图所示:
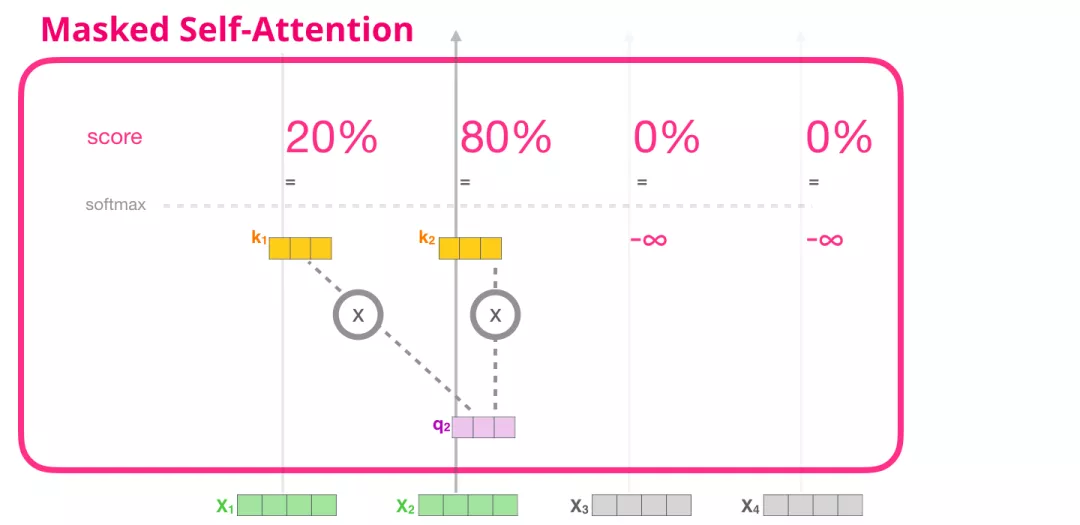
这个屏蔽(masking)经常用一个矩阵来实现,称为 attention mask矩阵。依旧以4个单词的序列为例(例如:robot must obay orders)。在一个语言建模场景中,这个序列会分为 4 个步骤处理:每个步骤处理一个词(假设现在每个词就是是一个token)。另外,由于模型是以 batch size 的形式工作的,我们可以假设这个简单模型的 batch size 为4,它会将4个序列生成任务作为一个 batch 处理,如下图所示,左边是输入,右边是label。

在矩阵的形式中,我们使用Query 矩阵和 Key 矩阵相乘来计算分数。将其可视化如下。但注意,单词无法直接进行矩阵运算,所以下图的单词还需要对应成一个向量。

在做完乘法之后,我们加上三角形的 attention mask。它将我们想要屏蔽的单元格设置为负无穷大或者一个非常大的负数(例如 GPT-2 中的 负十亿):

然后对每一行应用 softmax,会产生实际的分数,我们会将这些分数用于 Self Attention。

这个分数表的含义如下:
- 当模型处理数据集中的第 1 个数据(第 1 行),其中只包含着一个单词 (robot),它将 100% 的注意力集中在这个单词上。
- 当模型处理数据集中的第 2 个数据(第 2 行),其中包含着单词(robot must)。当模型处理单词 must,它将 48% 的注意力集中在 robot,将 52% 的注意力集中在 must。
- 诸如此类,继续处理后面的单词。
到目前为止,我们就搞明白了mask self attention啦。
GPT2中的Self-Attention
让我们更详细地了解 GPT-2的masked self attention。
模型预测的时候:每次处理一个 token
但我们用模型进行预测的时候,模型在每次迭代后只添加一个新词,那么对于已经处理过的token来说,沿着之前的路径重新计算 Self Attention 是低效的。那么GPT-2是如何实现高效处理的呢?
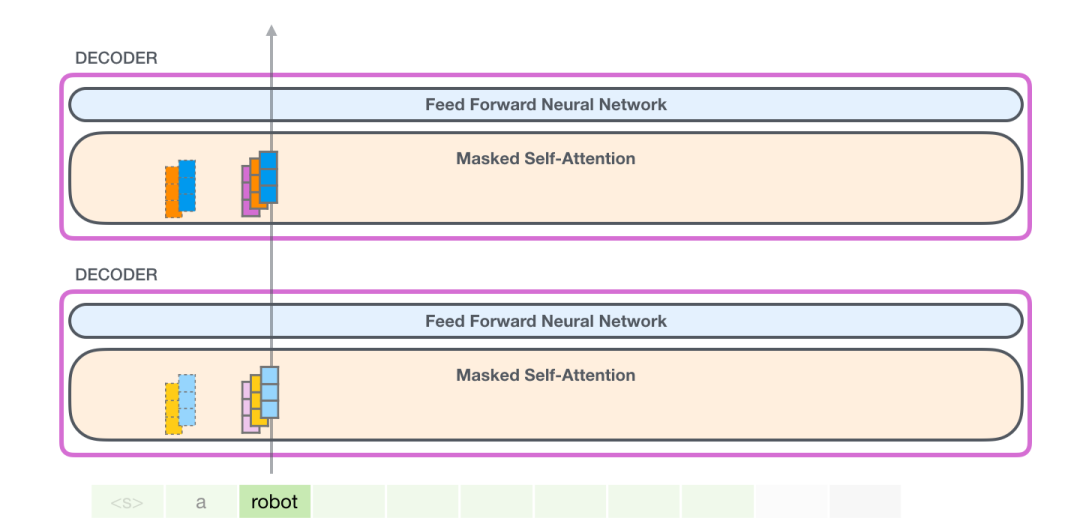
先处理第一个token a,如下图所示(现在暂时忽略 <s>)。
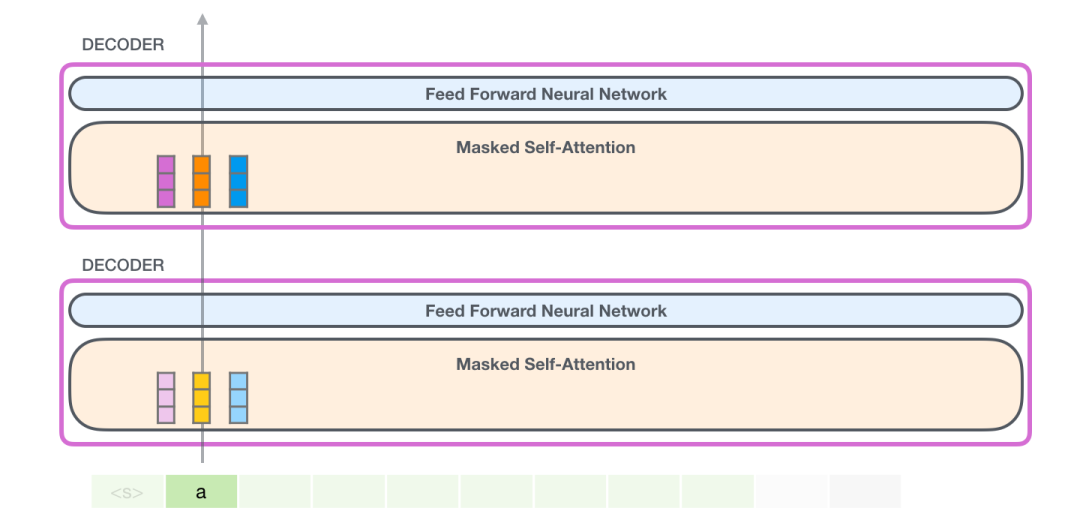
GPT-2 保存 token a 的 Key 向量和 Value 向量。每个 Self Attention 层都持有这个 token 对应的 Key 向量和 Value 向量:
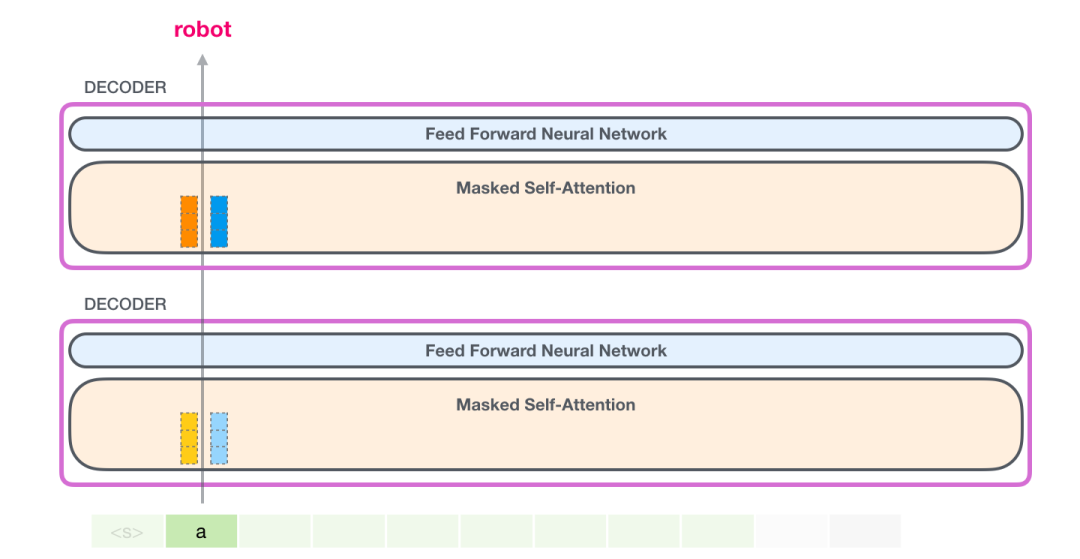
现在在下一个迭代,当模型处理单词 robot,它不需要生成 token a 的 Query、Value 以及 Key 向量。它只需要重新使用第一次迭代中保存的对应向量:
(1) 创建 Query、Key 和 Value 矩阵
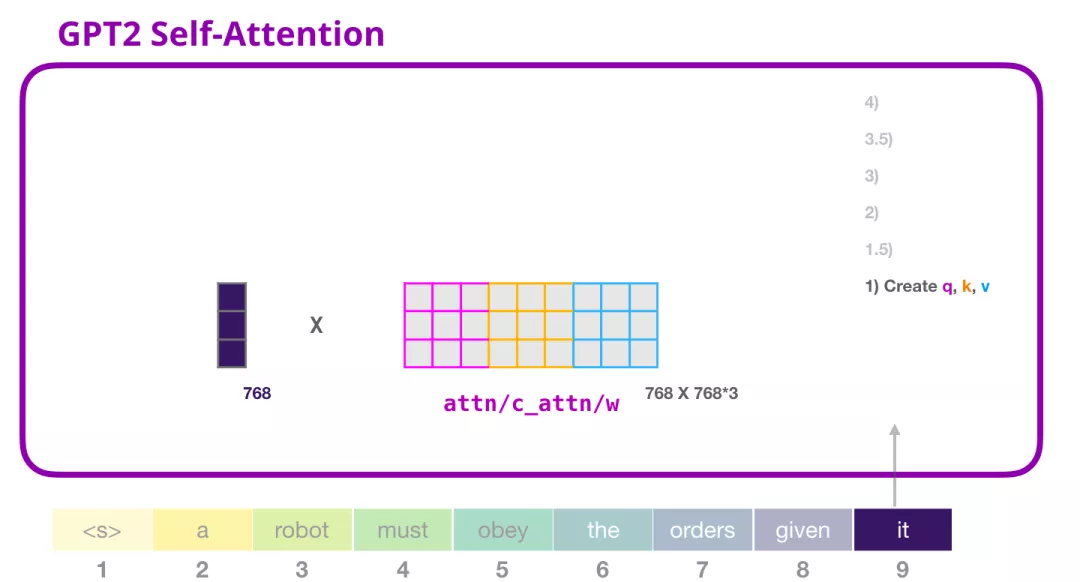
让我们假设模型正在处理单词 it。进入Decoder之前,这个 token 对应的输入就是 it 的 embedding 加上第 9 个位置的位置编码:

Transformer 中每个层都有它自己的参数矩阵(在后文中会拆解展示)。embedding向量我们首先遇到的权重矩阵是用于创建 Query、Key、和 Value 向量的。
Self-Attention 将它的输入乘以权重矩阵(并添加一个 bias 向量,此处没有画出)。
这个相乘会得到一个向量,这个向量是 Query、Key 和 Value 向量的拼接。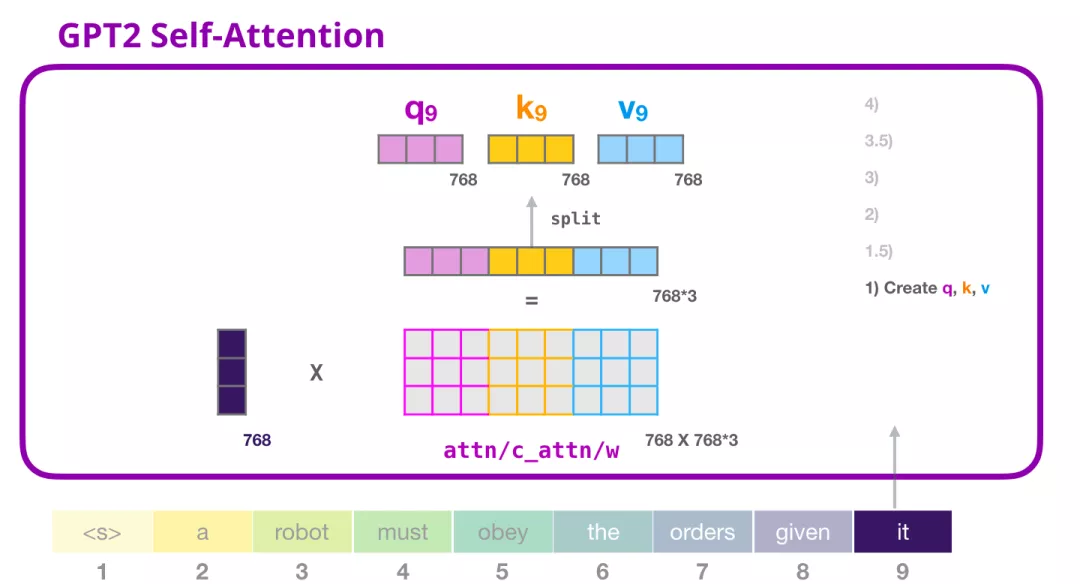
得到Query、Key和Value向量之后,我们将其拆分multi-head,如下图所示。其实本质上就是将一个大向量拆分为多个小向量。
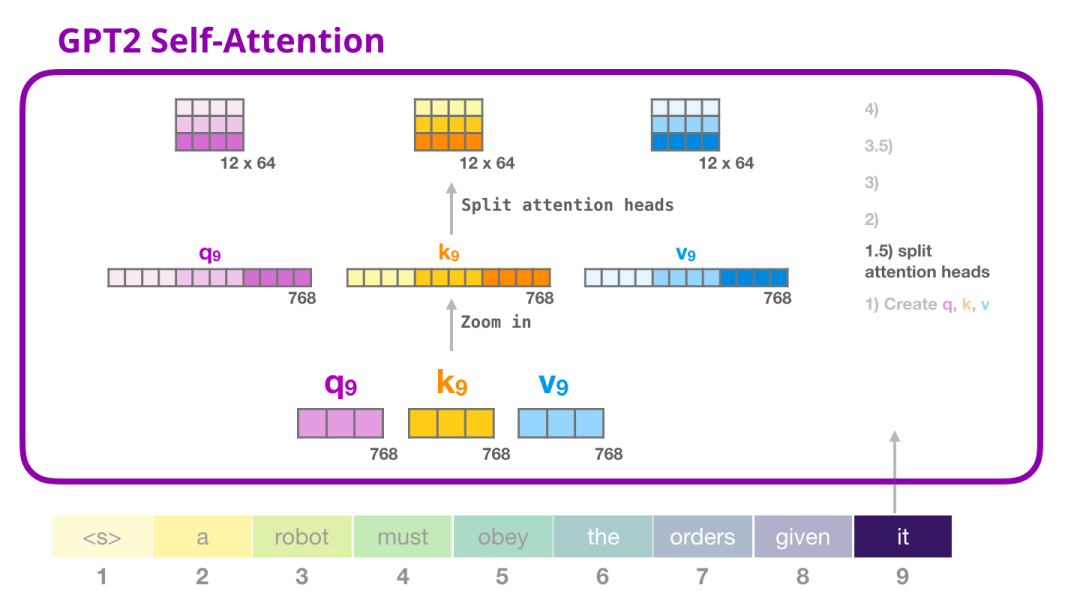
为了更好的理解multi head,我们将其进行如下展示:
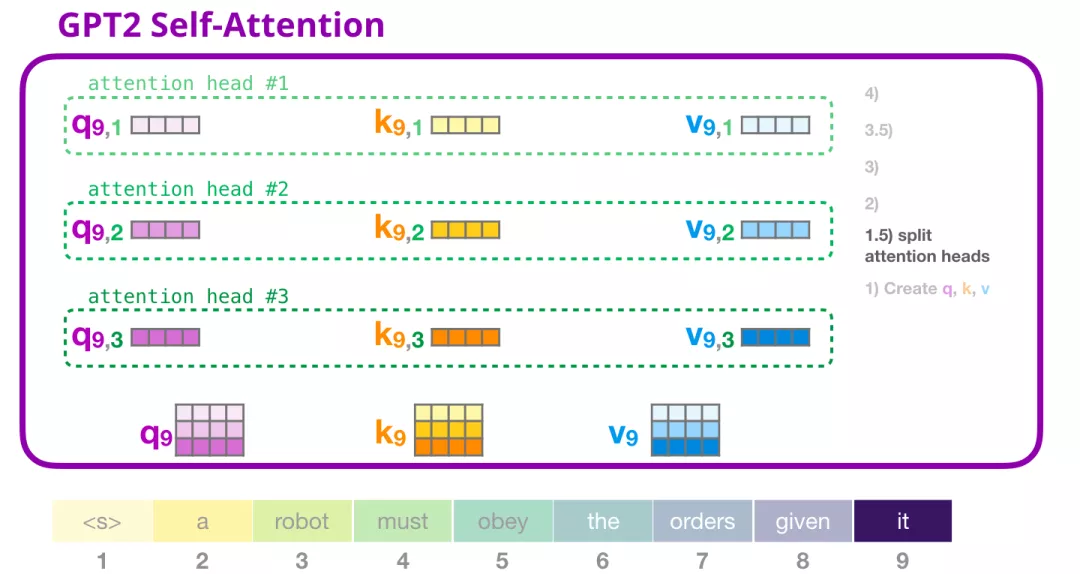
(2) 评分
我们现在可以继续进行评分,假设我们只关注一个 attention head(其他的 attention head 也是在进行类似的操作)。
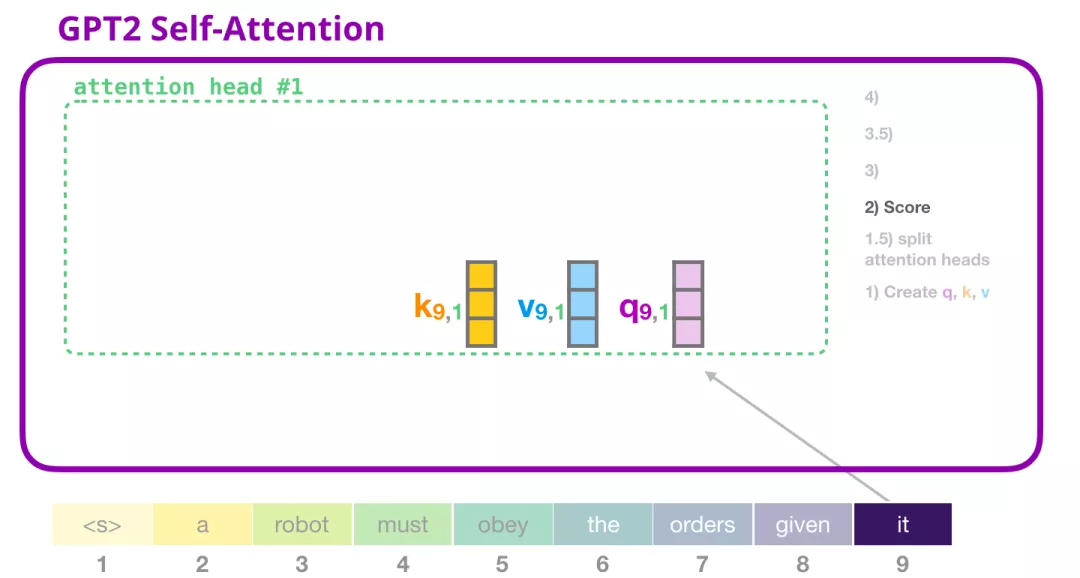
现在,这个 token 可以根据其他所有 token 的 Key 向量进行评分(这些 Key 向量是在前面一个迭代中的第一个 attention head 计算得到的):
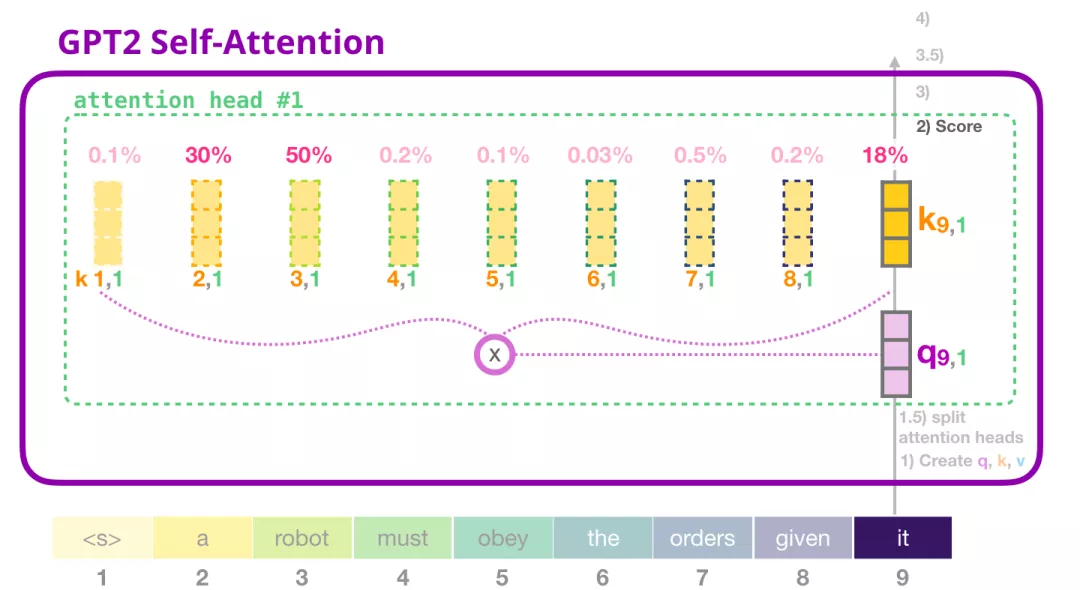
(3) 求和
正如我们之前所看的那样,我们现在将每个 Value 向量乘以对应的分数,然后加起来求和,得到第一个 attention head 的 Self Attention 结果:
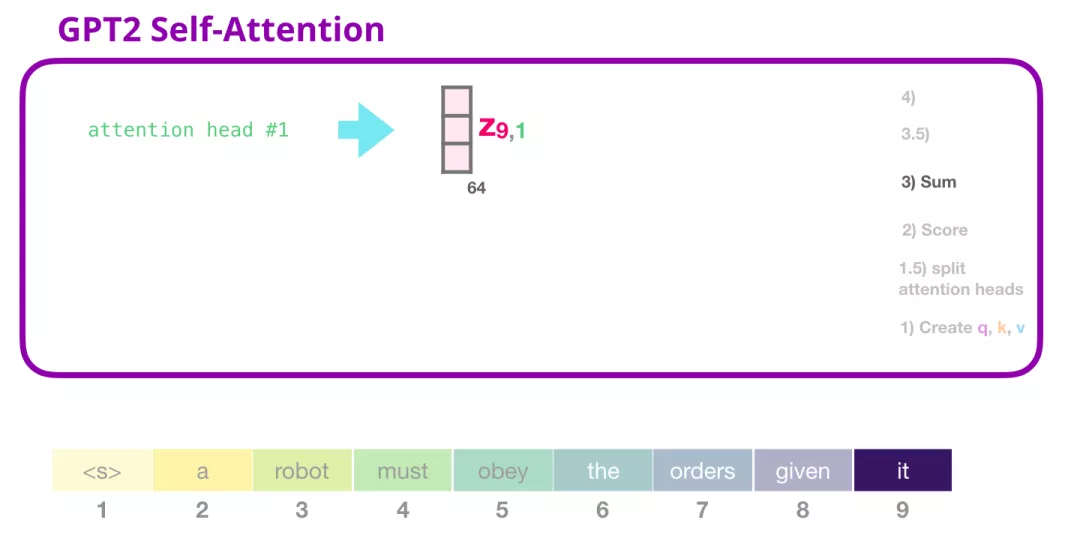
合并 attention heads
multi head对应得到多个加权和向量,我们将他们都再次拼接起来:
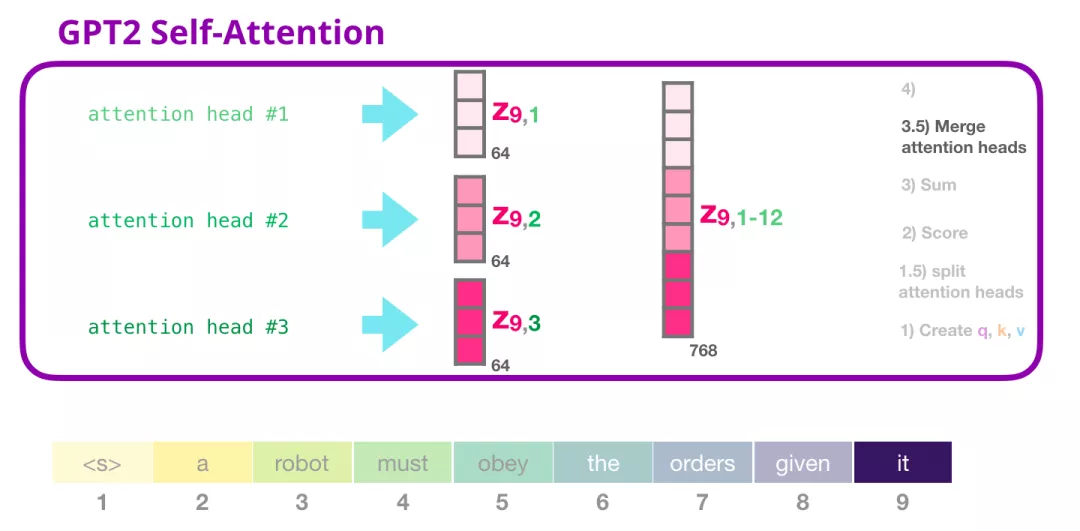
再将得到的向量经过一个线性映射得到想要的维度,随后输入全连接网络。
(4) 映射(投影)
我们将让模型学习如何将拼接好的 Self Attention 结果转换为前馈神经网络能够处理的输入。在这里,我们使用第二个巨大的权重矩阵,将 attention heads 的结果映射到 Self Attention 子层的输出向量:
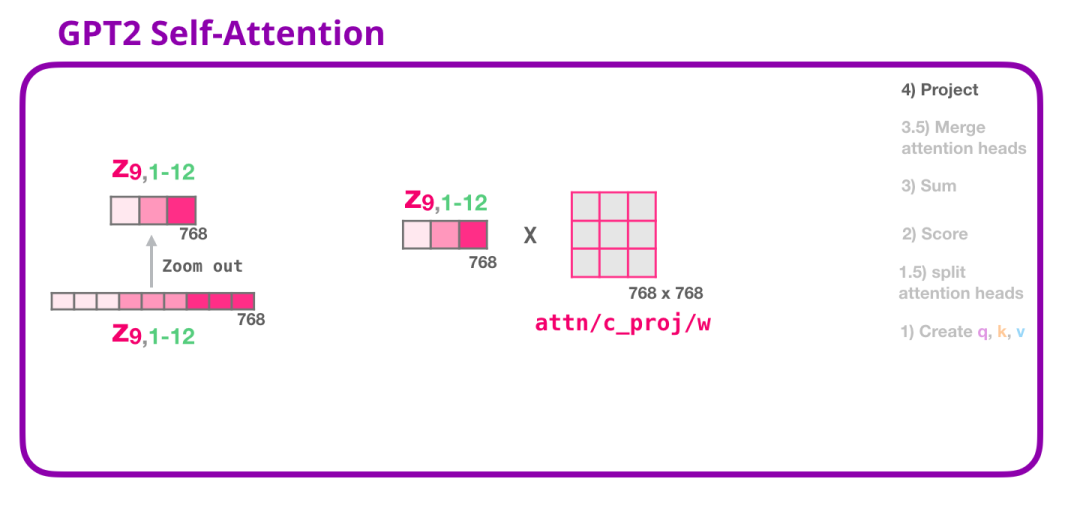
通过以上步骤,我们产生了一个向量,我们可以把这个向量传给下一层:
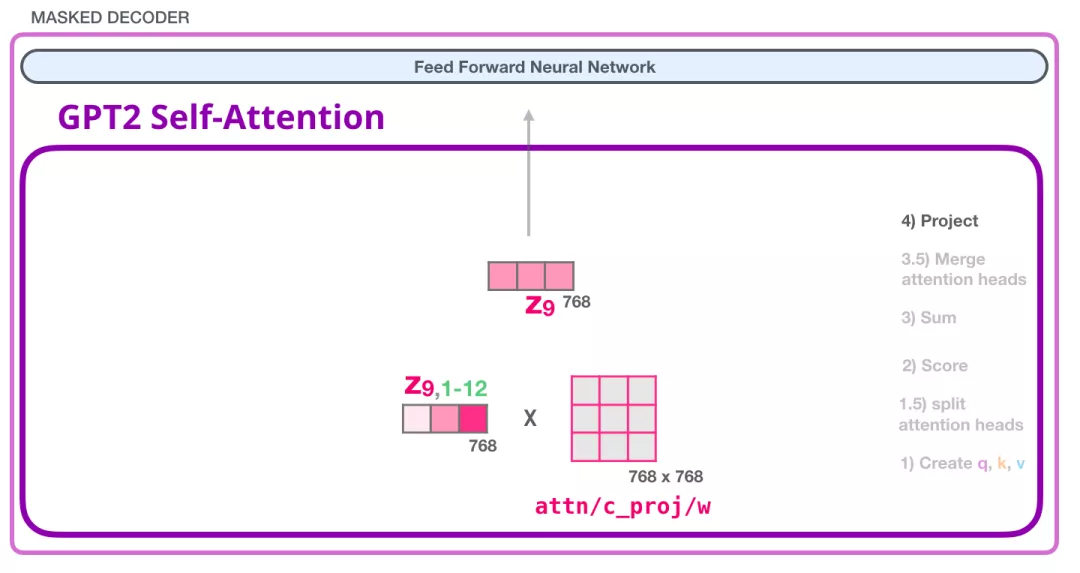
GPT-2 全连接神经网络
第 1 层
全连接神经网络是用于处理 Self Attention 层的输出,这个输出的表示包含了合适的上下文。全连接神经网络由两层组成。第一层是模型大小的 4 倍(由于 GPT-2 small 是 768,因此这个网络会有3072个神经元)。
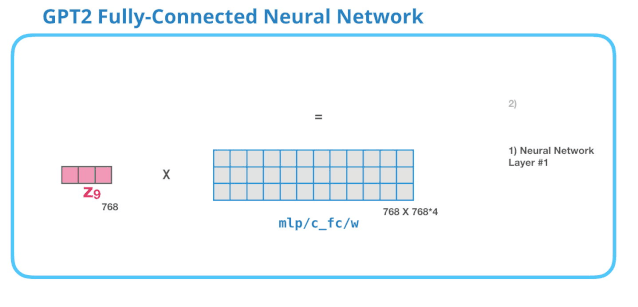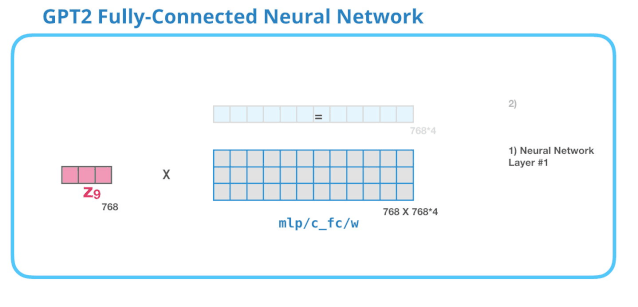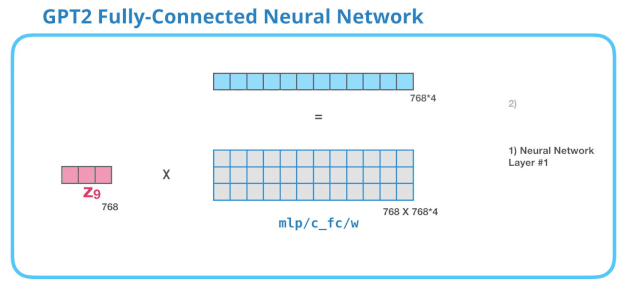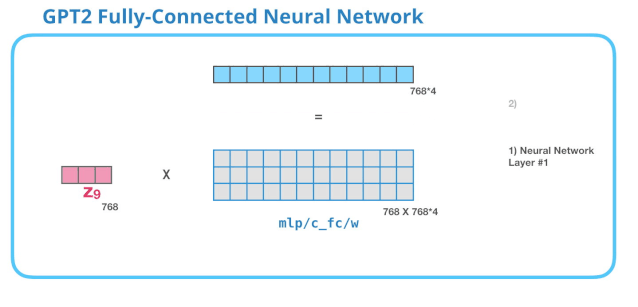
没有展示 bias 向量
第 2 层. 把向量映射到模型的维度
第 2 层把第一层得到的结果映射回模型的维度(在 GPT-2 small 中是 768)。这个相乘的结果是 Transformer 对这个 token 的输出。
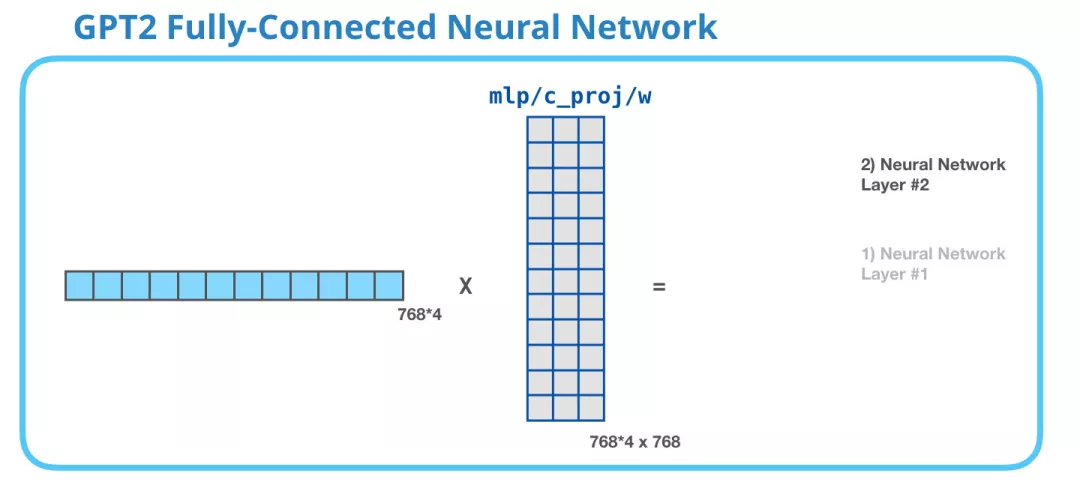
没有展示 bias 向量
总结一下,我们的输入会遇到下面这些权重矩阵:
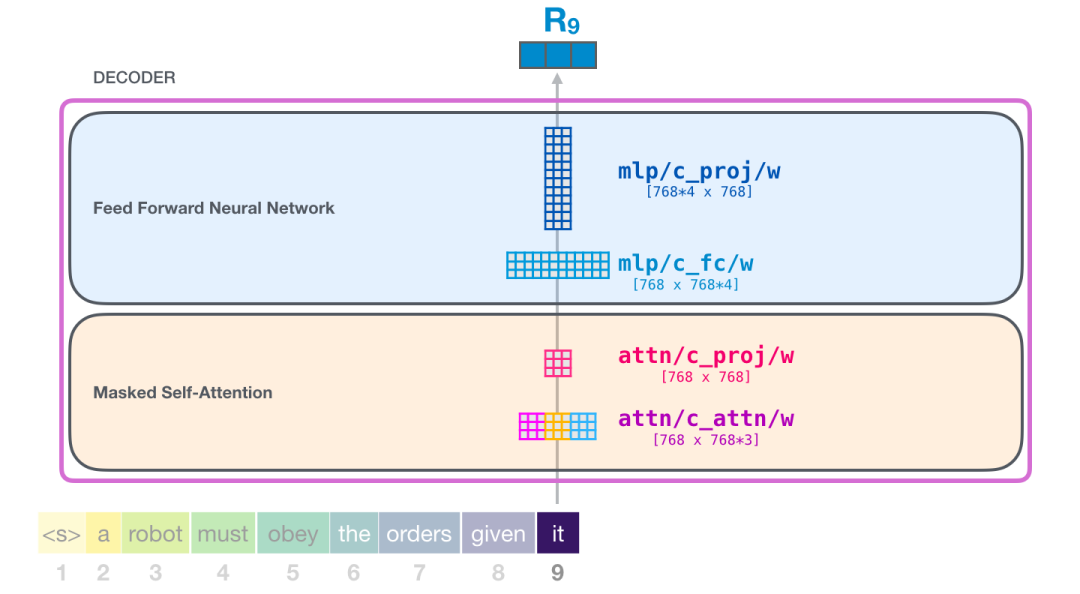
每个模块都有它自己的权重。另一方面,模型只有一个 token embedding 矩阵和一个位置编码矩阵。
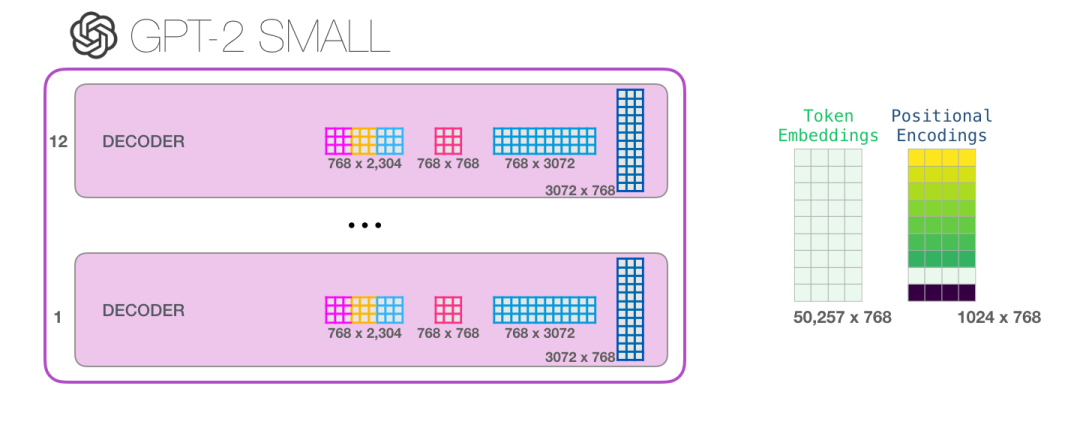
如果你想查看模型的所有参数,我在这里对它们进行了统计:
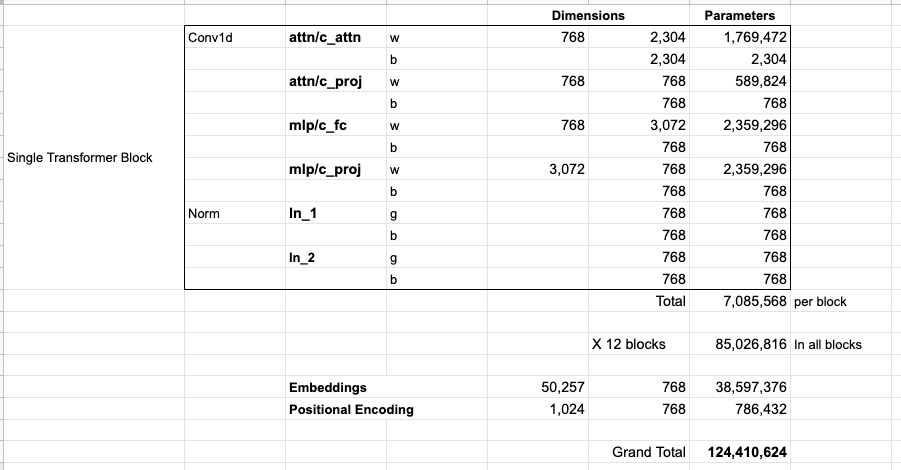
由于某些原因,它们加起来是 124 M,而不是 117 M。我不确定这是为什么,但这个就是在发布的代码中展示的大小(如果我错了,请纠正我)。
语言模型应用
只有 Decoder 的 Transformer 在语言模型之外一直展现出不错的效果。它已经被成功应用在了许多应用中,我们可以用类似上面的可视化来描述这些成功应用。让我们看看这些应用,作为这篇文章的结尾。
机器翻译
进行机器翻译时,Encoder 不是必须的。我们可以用只有 Decoder 的 Transformer 来解决同样的任务:
![]()
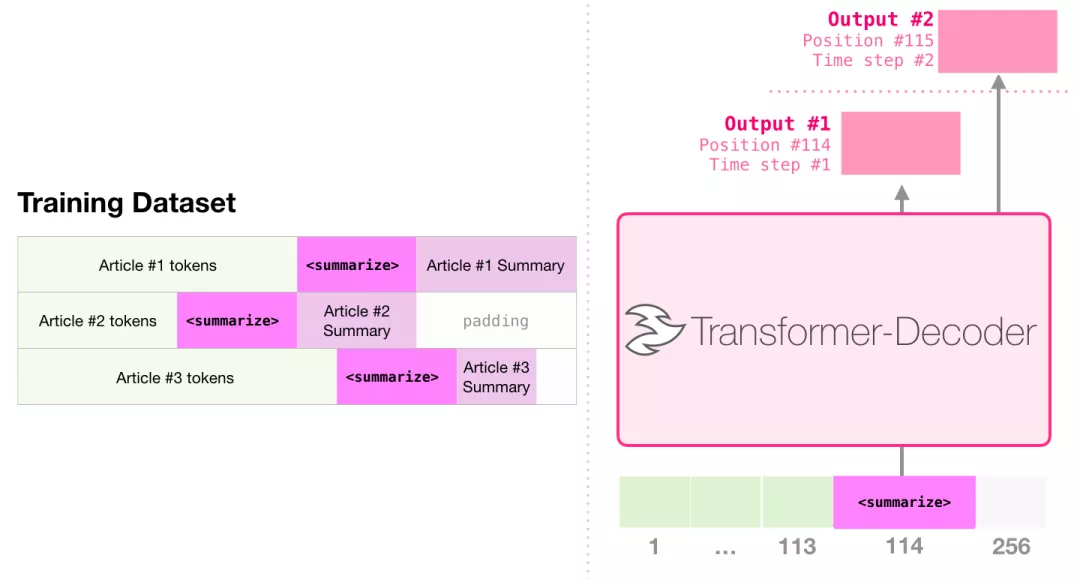
生成摘要
这是第一个只使用 Decoder 的 Transformer 来训练的任务。它被训练用于阅读一篇维基百科的文章(目录前面去掉了开头部分),然后生成摘要。文章的实际开头部分用作训练数据的标签: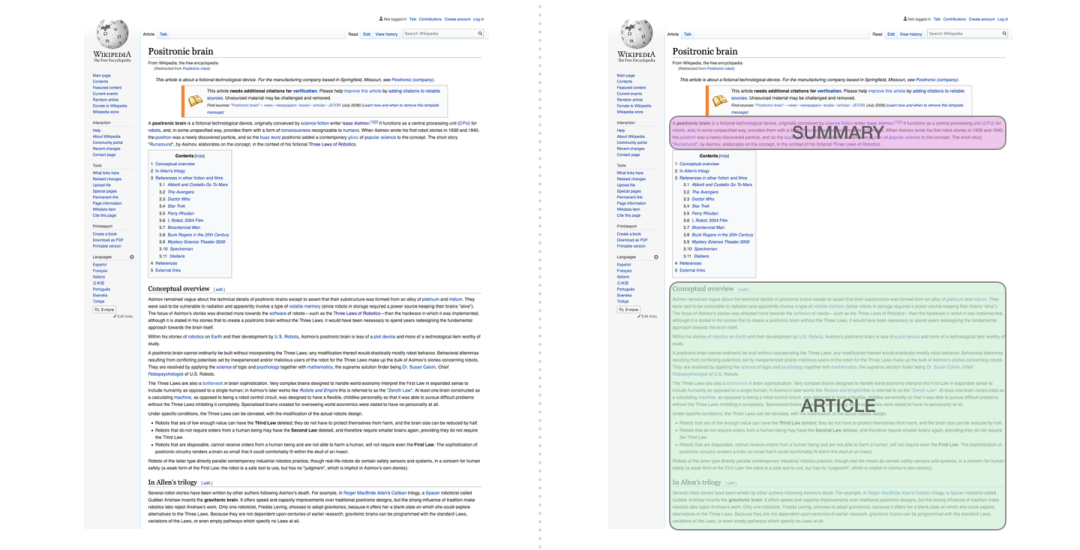
论文里针对维基百科的文章对模型进行了训练,因此这个模型能够总结文章,生成摘要:
 图
图
迁移学习
在 Sample Efficient Text Summarization Using a Single Pre-Trained Transformer(https://arxiv.org/abs/1905.08836) 中,一个只有 Decoder 的 Transformer 首先在语言模型上进行预训练,然后微调进行生成摘要。结果表明,在数据量有限制时,它比预训练的 Encoder-Decoder Transformer 能够获得更好的结果。
GPT-2 的论文也展示了在语言模型进行预训练的生成摘要的结果。
音乐生成
Music Transformer(https://magenta.tensorflow.org/music-transformer) 论文使用了只有 Decoder 的 Transformer 来生成具有表现力的时序和动态性的音乐。音乐建模 就像语言建模一样,只需要让模型以无监督的方式学习音乐,然后让它采样输出(前面我们称这个为 漫步)。
你可能会好奇在这个场景中,音乐是如何表现的。请记住,语言建模可以把字符、单词、或者单词的一部分(token),表示为向量。在音乐表演中(让我们考虑一下钢琴),我们不仅要表示音符,还要表示速度–衡量钢琴键被按下的力度。
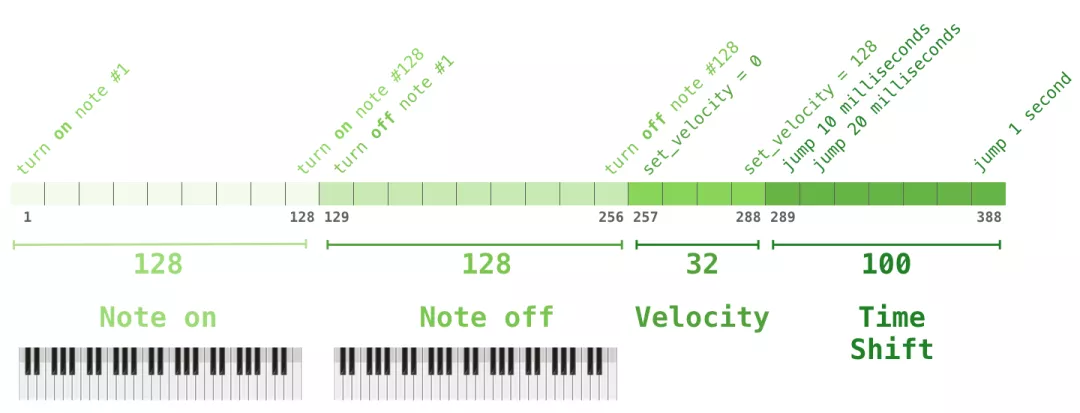
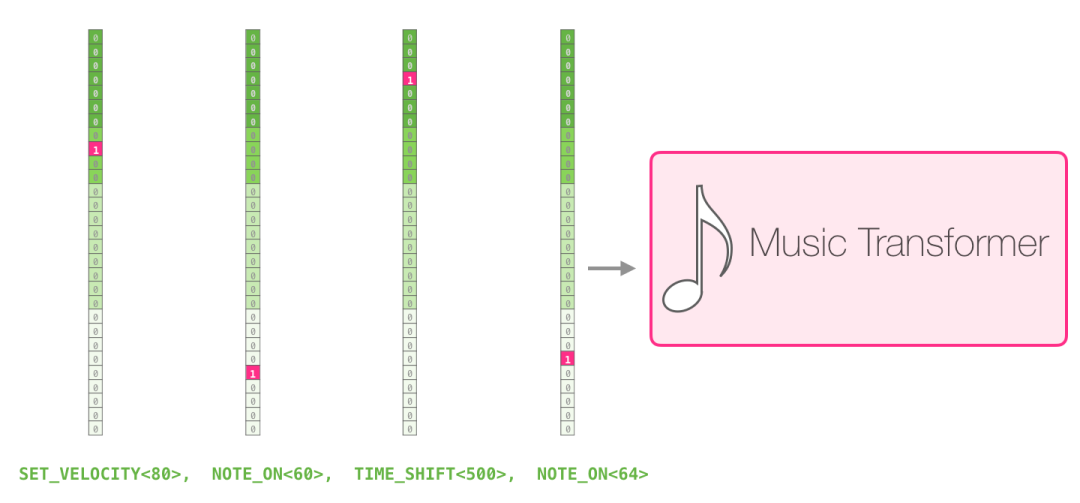
一场表演就是一系列的 one-hot 向量。一个 midi 文件可以转换为下面这种格式。论文里使用了下面这种输入序列作为例子:

这个输入系列的 one-hot 向量表示如下:
我喜欢论文中的音乐 Transformer 展示的一个 Self Attention 的可视化。我在这基础之上添加了一些注释:
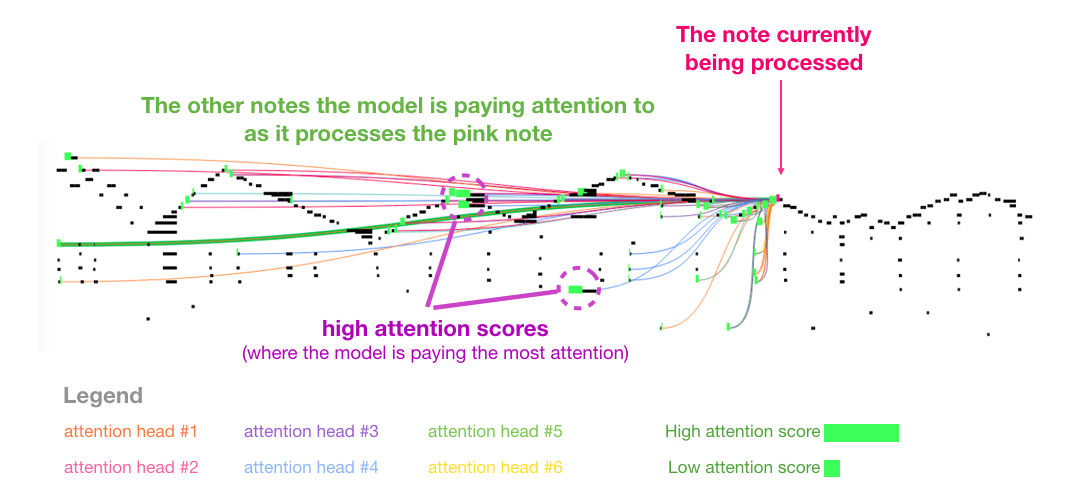
这段音乐有一个反复出现的三角形轮廓。Query 矩阵位于后面的一个峰值,它注意到前面所有峰值的高音符,以知道音乐的开头。这幅图展示了一个 Query 向量(所有 attention 线的来源)和前面被关注的记忆(那些受到更大的softmax 概率的高亮音符)。attention 线的颜色对应不同的 attention heads,宽度对应于 softmax 概率的权重。
总结
现在,我们结束了 GPT-2 的旅程,以及对其父模型(只有 Decoder 的 Transformer)的探索。我希望你看完这篇文章后,能对 Self Attention 有一个更好的理解,也希望你能对 Transformer 内部发生的事情有更多的理解。
附加资料
- 《Attention Is All You Need》
- 《Transformer: A Novel Neural Network Architecture for Language Understanding》
- 《Tensor2Tensor announcement》
- 视频 Łukasz Kaiser’s talk来理解模型和其中的细节
- 代码 Jupyter Notebook provided as part of the Tensor2Tensor repo
- Tensor2Tensor repo