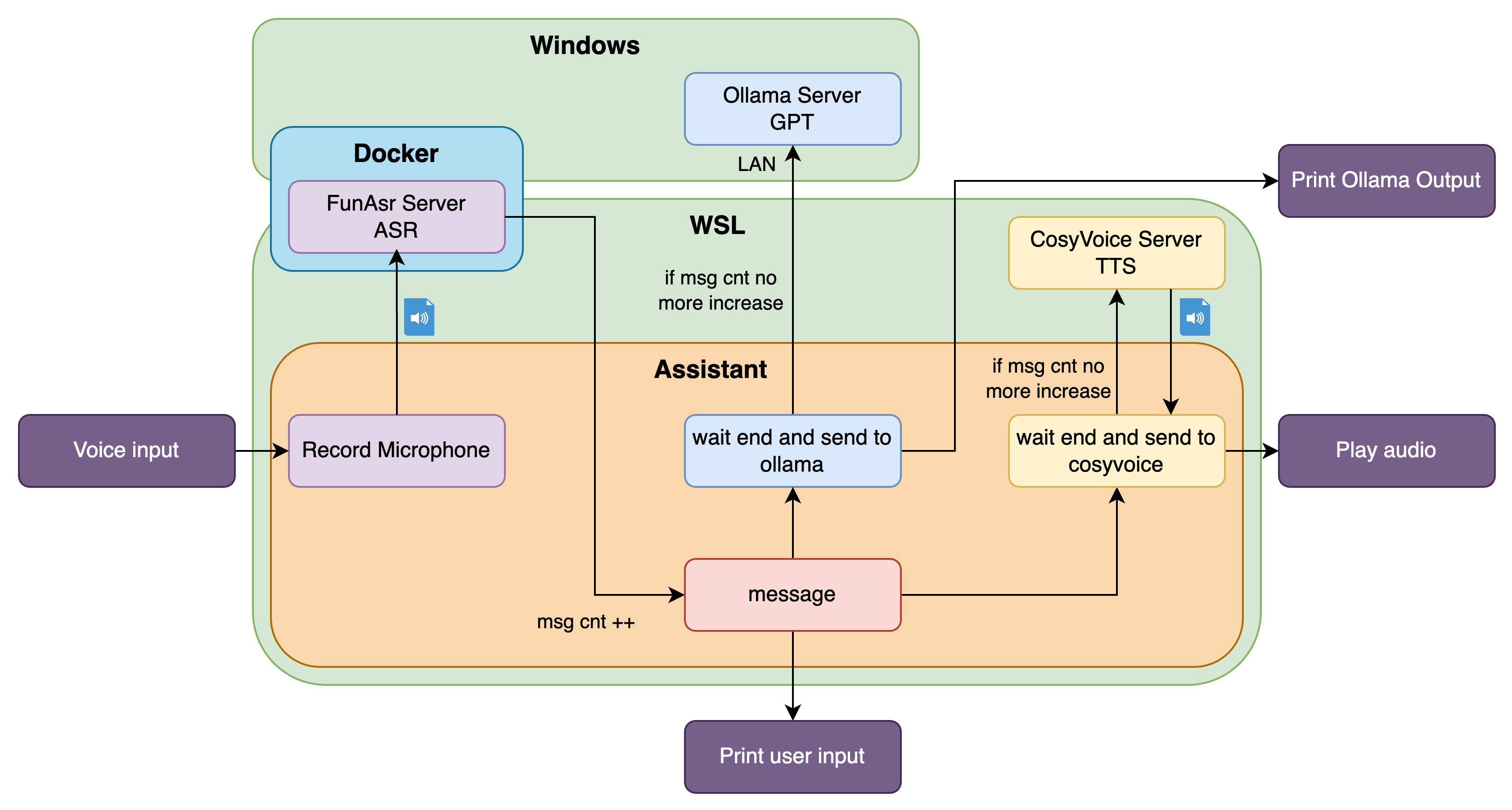
A Local AI Assistant like Siri
This is a project to deploy a local AI assistant. This combines FunASR,Ollama and CosyVoice.
- FunASR version: 1af68ba6ffc21d4dc3bd5f01cda656def97e361c
- CosyVoice version: 9e0b99e48e67c3a874b7d0bbdc1a6a15c35f422e
Current version cannot use the cosyvoice.
TODO
- Cosyvoice Streaming…
- Solve the defect that when playing the result audio, the microphone records the input and enter the death loop.
Preparation
FunASR
You need to guarantee the WSL and Windows host can share the docker, this can be opened WSL in the docker desktop.
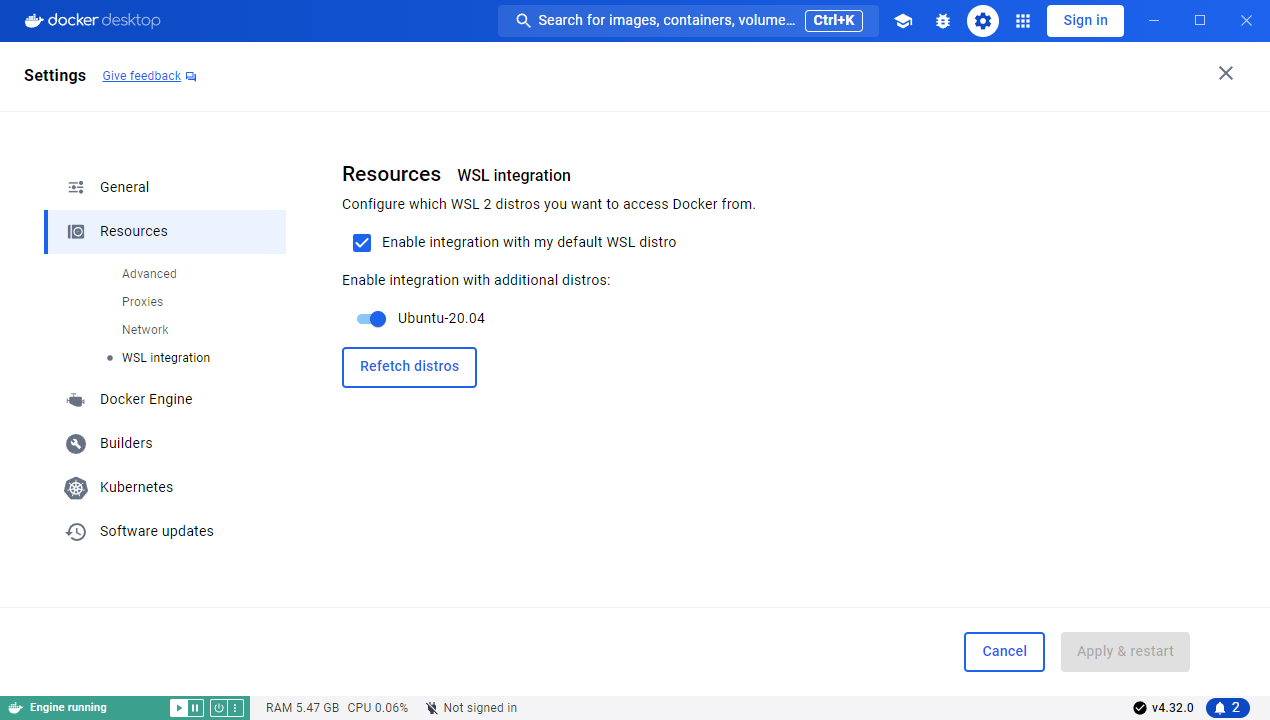
Follow this tutorial to deploy FunASR: FunASR Realtime Transcribe Service.
Download workspace and run the local Asr server:
1
2
3
4
5curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/funasr-runtime-deploy-online-cpu-zh.sh
sudo bash funasr-runtime-deploy-online-cpu-zh.sh install --workspace ./funasr-runtime-resources
# Restart the container
sudo bash funasr-runtime-deploy-online-cpu-zh.sh restartIn the container, it will download models from the modelscope. After that you should see:
1
2
3
4
5docker ps -a
docker exec -it <contianer ID> bash
# In container:
watch -n 0.1 "cat FunASR/runtime/log.txt | tail -n 10"
We need to stop recording when the mic is not active. Here the technology is called VAD.
We also need to judge when the users input stop, not by the mic, but the results count from FunASR server. The count of sentences(messages) sent from the ASR server increases when user is saying. When user stopped, the count will stop increasing. I set the latency to 2s, when there is no more sentences coming from the server, the thread of wait_end_and_send_to_ollama will block and wait the results from the Ollama server.
FIX: Note that when assistant is saying, the users input at the same time will be set as next input. An important feature is that user can interrupt the assistant.
Ollama
Download and install ollama in windows. After that, run ollama run llama3.1 or ollama run qwen:7b in the Powershell to download the model. Then start the ollama server:
1 | |
You can easily follow the Ollama PyPi tutorial to use ollama APIs.
1 | |
CosyVoice
Follow the tutorial: CosyVoice
Cuda 11.8 torch and torchaudio:
1
pip install torch==2.0.1 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118If you want to clone audio, transform audio file recorded from windows recorder:
This is a very funny feature provided by CosyVoice, for example, you can clone Trump’s voice. This is already realized several years ago, but here it supports Chinese and uses LLM. Note that you should follow the law and privacy policy, it is very significant.
1
ffmpeg -i input.m4a output.wavONNX Runtime Issue:
onnxruntime::Provider& onnxruntime::ProviderLibrary::Get() [ONNXRuntimeError] : 1 : FAIL : Failed to load library libonnxruntime_providers_cuda.so with error: libcufft.so.10: cannot open shared object file: No such file or directory1
2pip3 install onnxruntime-gpu==1.18.1 -i https://mirrors.aliyun.com/pypi/simple/
pip3 install onnxruntime==1.18.1 -i https://mirrors.aliyun.com/pypi/simple/Glibc issue:
version GLIBCXX_3.4.29 not found1
2
3
4
5find ~ -name "libstdc++.so.6*"
strings .conda/envs/cosyvoice/lib/libstdc++.so.6 | grep -i "glibcxx"
sudo cp .conda/envs/cosyvoice/lib/libstdc++.so.6.0.33 /lib/x86_64-linux-gnu
sudo rm /usr/lib/x86_64-linux-gnu/libstdc++.so.6
sudo ln -s /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.33 /usr/lib/x86_64-linux-gnu/libstdc++.so.6
Server and client
1 | |
Cosyvoice Docker
You can also follow the tutorial to build the container. Thus in windows, the server can be accessed from the host or any other devices in the LAN.
Note that there may be a CUFFT_INTERNAL_ERROR bug in cu117 docker. You can update to cu118 manually in the docker.
Uninstall 11.7 pytorch cuda in the container.
1 | |
Play the audio in python
After get the .wav files from the server, you can use simpleaudio python library to play the audio.
1 | |
Deploy
Windows
Run the script:
1 | |
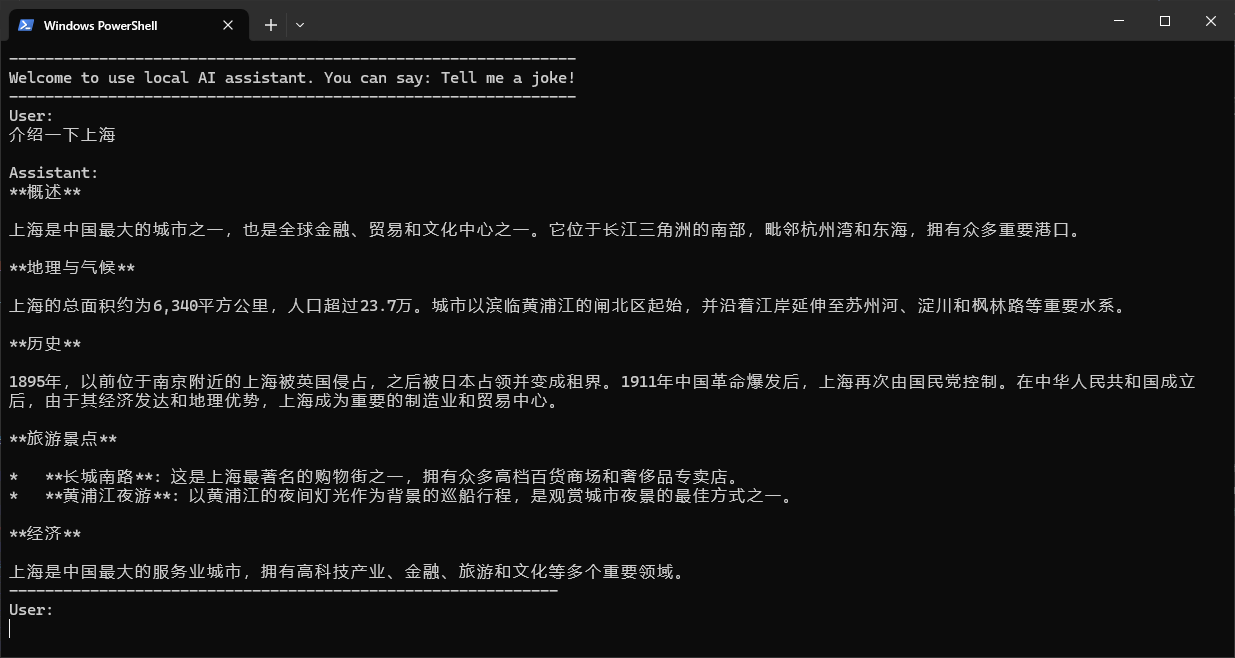
WSL
If ollama runs in the Windows host, you should enable wsl to access it in LAN (For other devices, this should also be enabled). In Powershell:
1
2
3[Environment]::SetEnvironmentVariable('OLLAMA_HOST', '0.0.0.0:11434', 'Process')
[Environment]::SetEnvironmentVariable('OLLAMA_ORIGINS', '*', 'Process')
ollama serveRun
ipconfigin Poweshell to get the IPv4 of Host, for example:172.20.10.2.The audio may not work due to the audio card. A way to solve the problem:
1
sudo apt-get install python3-pyaudio pulseaudio portaudio19-devRun the scripts:
1
2pip3 install websockets pyaudio ollama
python3 funasr_client.py --host "127.0.0.1" --port 10095 --hotword hotword.txt --llamahost "172.20.10.2:11434" --llm_model "qwen:7b"