迪普希指南汇总
羊毛党永不为奴!
更新
- 稀疏Attention,结合Nvidia 稀疏 Tensor Core,利用稀疏token提升训练推理速度,同事性能不下降
应用/羊毛
- DeepSeek 实用集成: https://github.com/deepseek-ai/awesome-deepseek-integration/blob/main/README_cn.md
- Nvidia NIM: https://build.nvidia.com/deepseek-ai/deepseek-r1
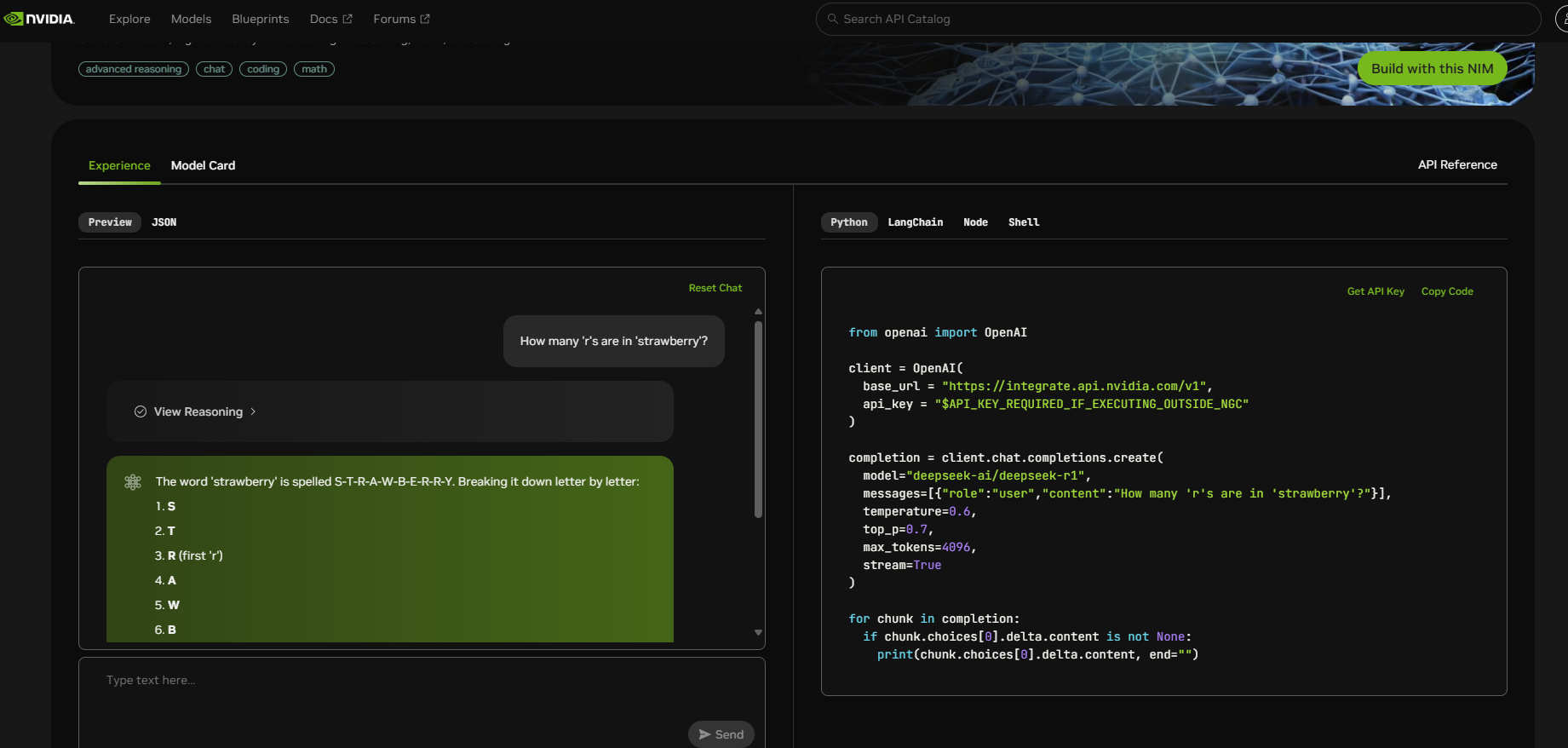
1 | |
1 | |


参考:
- 满血版DeepSeek-R1,五大平台白嫖攻略!
- 免费无限次!671B满血版DeepSeek R1隐藏入口,优秀平台推荐!
- 史诗级羊毛警报!腾讯云掏出671B核弹级模型白送:DeepSeek-V3/R1无限免费调用
- 0元!使用魔搭免费算力,基于Qwen基座模型,复现DeepSeek-R1
- 首发!硅基流动 x 华为云联合推出基于昇腾云的 DeepSeek R1 & V3 推理服务
- 在笔记本电脑快速运行蒸馏 DeepSeek R1
- 手把手带你用DeepSeek-R1和Ollama搭建本地应用,一文搞定!
- 字节终于出手了!挑战 Cursor,直接免费!
提示词
新闻
- 200多行代码,超低成本复现DeepSeek R1「Aha Moment」!复旦大学开源
- 历史时刻:DeepSeek GitHub星数超越OpenAI,仅用时两个月
- 中外轮番掘金,从月入10万到估值5亿,AI商业化的DeepSeek时刻不远了
- OpenAI突然公开o3思维链!网友:让我们谢谢DeepSeek
- R1中文复现教程预告!
- 李飞飞团队训练出媲美DeepSeek R1的推理模型,云计算费用不到50美元
- 国内AI适配再下一城:天数智芯加入,DeepSeek R1千问蒸馏模型再添新选择
- DeepSeek获四大国产GPU力挺!给全世界上了重要一课
- 潞晨华为联手放大招!DeepSeek-R1推理API免费不限量,算力直逼英伟达,开箱即用
- 四大国产GPU力挺DeepSeek!
- 英伟达机器人跳APT舞惊艳全网,科比C罗完美复刻!CMU 00后华人共同一作
- 英伟达憾失DeepSeek关键人才?美国放走AI「钱学森」,哈佛教授痛心疾首
- 人形机器人也能像詹姆斯和科比一样敏捷?CMU华人团队发布“ASAP”技术,让宇树机器人变“真人”
- 外媒拆解DeepSeek制胜秘籍!OpenAI CEO终于认错:我们站在了历史错误的一边
- DeepSeek突围奥秘曝光,一招MLA让全世界抄作业!150+天才集结,开出千万年薪
- 首个OpenAI免费推理模型o3-mini发布!DeepSeek让奥特曼反思:不开源我们错了
- o3-mini 碾压DeepSeek R1?一条python程序引发近400万围观
- 官宣:DeepSeek V3和R1模型完成海光DCU适配并正式上线
- 这篇博文让英伟达“血流成河”!
- 新研究揭示DeepSeek/o3弱点:频繁切换思路放弃正确方向,最短答案往往就是对的!
- 英伟达微软带头接入Deepseek,OpenAI急筹2800亿新融资
- DeepSeek在美两重天:五大巨头接入,政府诚惶诚恐
- 奥特曼率队深夜血战DeepSeek,o3-mini急上线!价格骨折免费用,ChatGPT被挤爆
- “DeepSeek甚至绕过了CUDA”,论文细节再引热议,工程师灵魂提问:英伟达护城河还在吗?
- 硅谷掀桌!DeepSeek遭OpenAI和Anthropic围剿,美国网友都看不下去了
- 超全推理语言模型蓝图来了!揭开o1、o3、DeepSeek-V3神秘面纱
- DeepSeek独立发现o1核心思路,OpenAI首席研究官亲自证实!奥特曼被迫发声
- DeepSeek 团队神操作:用“汇编”取代CUDA 让性能狂飙!
- DeepSeek重创美国芯片产业,英伟达一夜蒸发6000亿!巨头破防,美股历史性崩盘
- DeepSeek砍掉英伟达台积电5万亿市值!登五大外媒头版,OpenAI急得发预告
- DeepSeek开源o1击毙OpenAI,强化学习惊现「啊哈」时刻!网友:AGI来了
Model
Github: https://github.com/deepseek-ai
Hugging face: https://huggingface.co/models?other=deepseek_v3
有热心人转好的bf16版: https://huggingface.co/arcee-ai/DeepSeek-R1-bf16
昨天vllm进了一堆deepseek的优化支持: https://github.com/vllm-project/vllm/releases/tag/v0.7.1
MLA 的cutlass 实现,现在ck tile 通了可以试着快速抄个作业看看。新鲜出炉,还没merge:https://github.com/flashinfer-ai/flashinfer/pull/766/files#diff-b79afcbf2122f61bc5f5653483159cee4c7e8d9affb74552dc56912f3a4efd3f
技术分析
- AI大神Andrej Karpathy的通俗解释:预训练、监督式微调、强化学习!
- DeepSeek简明解析,10分钟速通DeepSeekV1~V3核心技术点!
- 以推理视角学习Deepseek V3
- 5 个工程师 24 小时手撸免费版 Deep Research!
- DeepSeek R1 Zero中文复现教程来了!
- 华为 PreServe:LLM 推理中的预取方案,缓解 Memory Bound
- 再读MLA,还有多少细节是你不知道的
论文
PDF - DeepSeek-V3 Technical Report
我们介绍了DeepSeek-V3,这是一种强大的混合专家(MoE)语言模型,具有671B的总参数,每个令牌都激活了37B。为了实现高效的推理和具有成本效益的训练,DeepSeek-V3采用了多头潜在注意力(MLA)和DeepSeekMoE架构,这些架构在DeepSeek-V2中得到了彻底的验证。此外,DeepSeek-V3开创了负载平衡的辅助无损失策略,并为更强的性能设定了多令牌预测训练目标。我们在14.80万亿多样化和高质量的令牌上预先训练DeepSeek-V3,然后是监督微调和强化学习阶段,以充分利用其能力。综合评估显示,DeepSeek-V3的性能优于其他开源模型,并实现了与领先的闭源模型相当的性能。尽管性能出色,但DeepSeek-V3的完整训练只需要2.788MH800 GPU小时。此外,其训练过程非常稳定。在整个训练过程中,我们没有遇到任何不可恢复的损失峰值或执行任何回滚。模型检查点可在 https://github.com/deepseek-ai/DeepSeek-V3
简介
近年来,大型语言模型(LLM)经历了快速迭代和演进(OpenAI,2024a; Anropic,2024;Google,2024),逐步缩小了与通用人工智能(AGI)的差距。除了闭源模型之外,开源模型,包括DeepSeek系列(DeepSeek-AI,2024b,c;郭等人,2024;DeepSeek-AI,2024a)、LLaMA系列(Touvron等人,2023a,b;AI@Meta,2024a,b)、Qwen系列(Qwen,2023,2024a,2024b)和Mistral系列(江等人,2023;米斯特拉尔,2024),也在取得重大进展,努力缩小与闭源同行的差距。为了进一步推动开源模型功能的界限,我们扩展了我们的模型并引入了DeepSeek-V3,这是一个具有671B参数的大型混合专家(MoE)模型,其中每个令牌激活37B。
凭借前瞻性的视角,我们始终如一地追求强大的模型性能和经济的成本。因此,在架构方面,DeepSeek-V3仍然采用多头潜在注意力(MLA)(DeepSeek-AI,2024c)进行高效推理,采用DeepSeekMoE(戴等人,2024年)进行经济高效的训练。这两种架构已经在DeepSeek-V2(DeepSeek-AI,2024c)中得到验证,展示了它们在保持稳健模型性能的同时实现高效训练和推理的能力。除了基本架构之外,我们还实施了两种额外的策略来进一步增强模型能力。首先,DeepSeek-V3开创了负载平衡的辅助无损失策略(Wang等人,2024a),目的是最小化鼓励负载平衡的努力对模型性能产生的不利影响。其次,DeepSeek-V3采用多令牌预测训练目标,我们已经观察到它可以提高评估基准的整体性能。
为了实现高效训练,我们支持FP8混合精度训练,并对训练框架实施全面优化。低精度训练已成为高效训练的有前途的解决方案(Kalamkar et al.,2019; Narang et al.,2017;彭等人,2023b;Dettmers et al.,2022),其演变与硬件能力的进步密切相关(Micikevicius et al.,2022;罗等人,2024;鲁哈尼等人,2023a)。在这项工作中,我们引入了FP8混合精度训练框架,并首次在极其大规模的模型上验证了其有效性。通过对FP8计算和存储的支持,我们实现了加速训练和减少GPU内存使用。至于训练框架,我们为高效的管道并行性设计了DualPipe算法,它具有更少的管道气泡,并通过computation-communication重叠隐藏了训练期间的大部分通信。这种重叠确保了,随着模型进一步扩展,只要我们保持恒定的computation-to-communication比,我们仍然可以跨节点雇用细粒度的专家,同时实现近零的全对全通信开销。此外,我们还开发了高效的跨节点全对全通信内核,以充分利用InfiniBand(IB)和NVLink带宽。此外,我们精心优化了内存占用,使得在不使用昂贵的张量并行性的情况下训练DeepSeek-V3成为可能。结合这些努力,我们实现了高训练效率。
在预训练期间,我们在14.8T高质量和多样化的令牌上训练DeepSeek-V3。预训练过程非常稳定。在整个训练过程中,我们没有遇到任何不可恢复的损失峰值或不得不回滚。接下来,我们对DeepSeek-V3进行了两阶段的上下文长度扩展。在第一阶段,最大上下文长度扩展到32K,在第二阶段,进一步扩展到128K。在此之后,我们在DeepSeek-V3的基本模型上进行了后训练,包括监督微调(SFT)和强化学习(RL),以使其与人类偏好保持一致,并进一步释放其潜力。在后训练阶段,我们从DeepSeek-R1系列模型中提炼推理能力,同时小心地保持模型准确性和生成长度之间的平衡。
我们在一系列基准测试上评估DeepSeek-V3。尽管培训成本低廉,但综合评估显示,DeepSeek-V3-Base已成为目前可用的最强大的开源基础模型,尤其是在代码和数学方面。它的聊天版本还优于其他开源模型,并在一系列标准和开放式基准测试上实现了与领先的闭源模型(包括GPT-4o和Claude-3.5-Sonnet)相当的性能。
| Training Costs | Pre-Training | Context Extension | Post-Training | Total |
|---|---|---|---|---|
| in H800 GPU Hours | 2664K | 119K | 5K | 2788K |
| in USD | $5.328M | $0.238M | $0.01M | $5.576M |
最后,我们再次强调了表1中总结的DeepSeek-V3的经济培训成本,这是通过我们优化的算法,框架和硬件的共同设计实现的。在训练前阶段,每万亿个令牌上的DeepSeek-V3只需要180k H800 GPU小时,即在我们的群集上使用2048 H800 GPU,在我们的群集上进行3.7天。因此,我们的训练阶段在不到两个月的时间内完成,花费了2664k GPU小时。与119k GPU小时的上下文延长和5K GPU小时相结合,用于培训后的GPU小时,DeepSeek-V3仅花费278.8万GPU小时才能进行全面培训。假设H800 GPU的租金价格为每GPU小时2美元,我们的总培训费用仅为557.6万美元。请注意,上述成本仅包括对DeepSeek-V3进行的官方培训,不包括与先前的研究和消融实验有关的成本,并进行了有关建筑,算法或数据的消融实验。
PDF - DeepSeek-R1:通过强化学习激励 LLMs 的推理能力
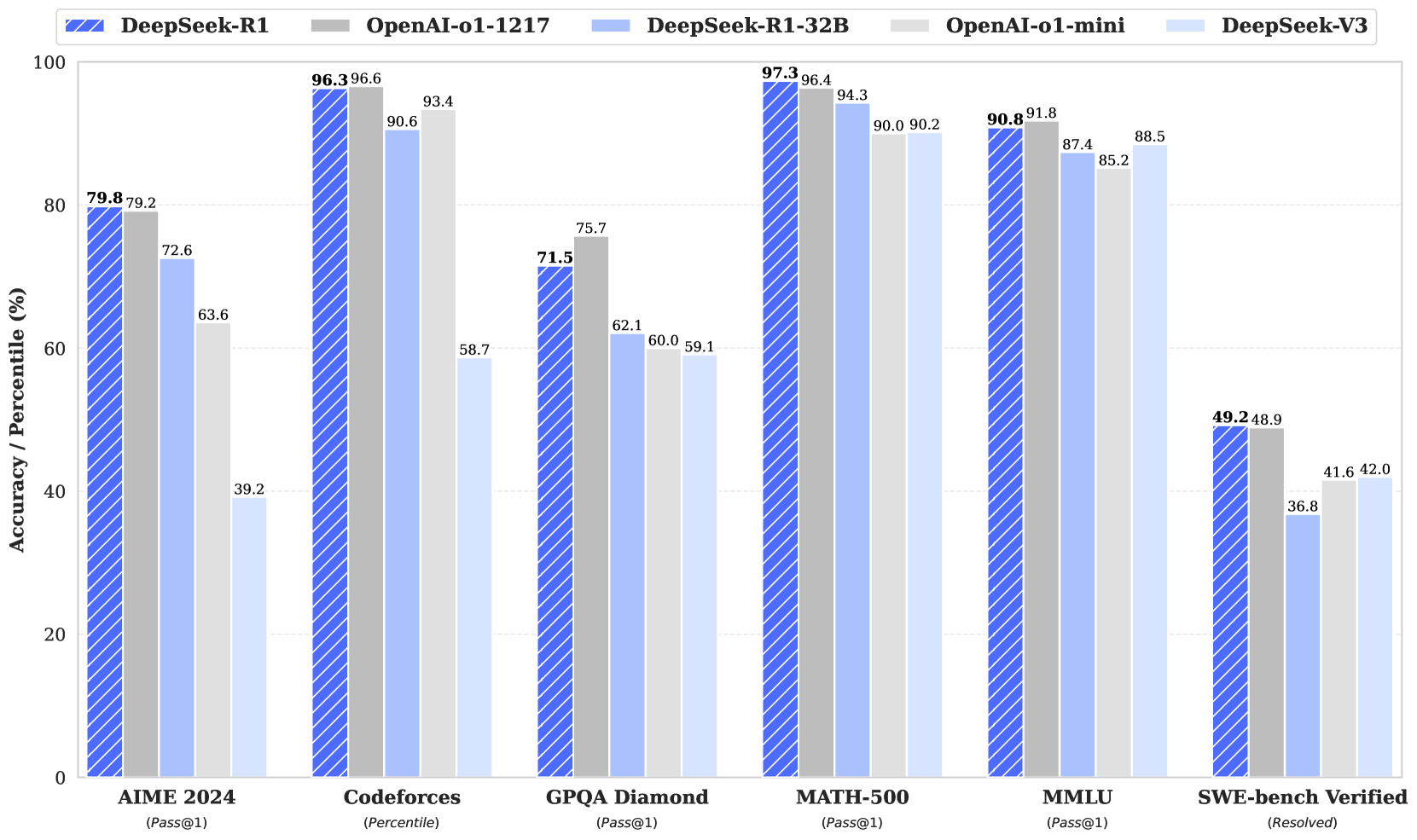
我们介绍了第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。DeepSeek-R1-Zero 是一种通过大规模强化学习 (RL) 训练的模型,无需监督微调 (SFT) 作为初步步骤,它展示了卓越的推理能力。通过 RL,DeepSeek-R1-Zero 自然而然地呈现出许多强大而有趣的推理行为。然而,它面临着可读性差和语言混合等挑战。为了解决这些问题并进一步提高推理性能,我们推出了 DeepSeek-R1,它在 RL 之前结合了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能。为了支持研究社区,我们开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及基于 Qwen 和 Llama 从 DeepSeek-R1 提炼出的六个密集模型(1.5B、7B、8B、14B、32B、70B)。
简介
近年来,大型语言模型 (LLM) 经历了快速迭代和发展(OpenAI,2024a;Anthropic,2024;Google,2024),与通用人工智能 (AGI) 的差距逐渐缩小。
最近,后训练已成为整个训练流程的重要组成部分。事实证明,它可以提高推理任务的准确性、与社会价值观保持一致并适应用户偏好,同时与预训练相比,它所需的计算资源相对较少。在推理能力方面,OpenAI 的 o1(OpenAI,2024b)系列模型首次通过增加思维链推理过程的长度来引入推理时间扩展。这种方法在数学、编码和科学推理等各种推理任务中取得了显着的改进。然而,有效的测试时间扩展的挑战仍然是研究界的一个悬而未决的问题。之前已有多项研究探索了各种方法,包括基于过程的奖励模型(Uesato 等人,2022 年;Lightman 等人,2023 年;Wang 等人,2023 年)、强化学习(Kumar 等人,2024 年)以及蒙特卡洛树搜索和波束搜索等搜索算法(Feng 等人,2024 年;Xin 等人,2024 年;Trinh 等人,2024 年)。然而,这些方法都没有达到与 OpenAI 的 o1 系列模型相当的通用推理性能。
在本文中,我们迈出了使用纯强化学习 (RL) 来提高语言模型推理能力的第一步。我们的目标是探索 LLM 在没有任何监督数据的情况下开发推理能力的潜力,重点关注它们通过纯 RL 过程进行自我进化。具体来说,我们使用 DeepSeek-V3-Base 作为基础模型,并使用 GRPO (Shao et al., 2024) 作为 RL 框架来提高模型在推理方面的性能。在训练过程中,DeepSeek-R1-Zero 自然而然地出现了许多强大而有趣的推理行为。经过数千个 RL 步骤后,DeepSeek-R1-Zero 在推理基准上表现出超强的性能。例如,AIME 2024 上的 pass@1 分数从 15.6% 提高到 71.0%,通过多数投票,分数进一步提高到 86.7%,与 OpenAI-o1-0912 的性能相当。
然而,DeepSeek-R1-Zero 面临着可读性差、语言混杂等问题。为了解决这些问题,进一步提升推理性能,我们推出了 DeepSeek-R1,它采用了少量冷启动数据和多阶段训练流程。具体来说,我们首先收集数千个冷启动数据来微调 DeepSeek-V3-Base 模型,然后像 DeepSeek-R1-Zero 一样进行面向推理的强化学习。当强化学习过程接近收敛时,我们在强化学习检查点上通过拒绝采样创建新的 SFT 数据,结合 DeepSeek-V3 在写作、事实问答、自我认知等领域的监督数据,重新训练 DeepSeek-V3-Base 模型。在使用新数据进行微调后,检查点会经历额外的强化学习过程,涵盖所有场景的提示。经过这些步骤,我们获得了一个检查点,称为 DeepSeek-R1,其性能与 OpenAI-o1-1217 相当。
我们进一步探索从 DeepSeek-R1 到较小密集模型的蒸馏。使用 Qwen2.5-32B (Qwen, 2024b) 作为基础模型,从 DeepSeek-R1 直接蒸馏的效果优于在其上应用 RL。这表明,更大的基础模型发现的推理模式对于提高推理能力至关重要。我们开源了蒸馏后的 Qwen 和 Llama (Dubey et al., 2024) 系列。值得注意的是,我们蒸馏后的 14B 模型的表现远胜于最先进的开源 QwQ-32B-Preview (Qwen, 2024a),蒸馏后的 32B 和 70B 模型在密集模型的推理基准上创下了新纪录。
贡献
后训练:在基础模型上进行大规模强化学习
- 我们直接将 RL 应用于基础模型,而不依赖监督微调 (SFT) 作为初步步骤。这种方法允许模型探索解决复杂问题的思路 (CoT),从而开发出 DeepSeek-R1-Zero。DeepSeek-R1-Zero 展示了自我验证、反思和生成长 CoT 等功能,标志着研究界的一个重要里程碑。值得注意的是,这是第一个公开研究,验证了 LLM 的推理能力可以纯粹通过 RL 来激励,而无需 SFT。这一突破为该领域的未来发展铺平了道路。
- 我们引入了开发 DeepSeek-R1 的管道。该管道包含两个 RL 阶段,旨在发现改进的推理模式并与人类偏好保持一致,以及两个 SFT 阶段,作为模型推理和非推理能力的种子。我们相信,通过创建更好的模型,该流程将使行业受益。
蒸馏:较小的模型也可以很强大
- 我们证明,较大模型的推理模式可以提炼成较小的模型,与通过 RL 在小型模型上发现的推理模式相比,其性能更好。开源 DeepSeek-R1 及其 API 将使研究界受益,以便将来提炼出更好的小型模型。
- 使用 DeepSeek-R1 生成的推理数据,我们对研究界广泛使用的几个密集模型进行了微调。评估结果表明,提炼后的较小密集模型在基准测试中表现非常出色。DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上取得了 55.5% 的成绩,超过了 QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上的得分为 72.6%,在 MATH-500 上的得分为 94.3%,在 LiveCodeBench 上的得分为 57.2%。这些结果明显优于之前的开源模型,与 o1-mini 相当。我们向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 检查点。